Editori:
Ricerca finanziata dal MURST Dipartimento per gli Affari Economici Ufficio III, Programmi di Ricerca di Rilevante Interesse Nazionale nell'ambito del Progetto n.9909112115 "Gestione Integrata di Sistemi Produttivi Interagenti: Metodi Quantitativi Avanzati per la Quick Response", Area 09 - Ingegneria industriale, 1999.
Stampato a Genova, Italy, November 2001
ISBN 88-900732-0-9
Editori:
Agostino Bruzzone, Roberto Mosca, Roberto Revetria
DIP University of Genoa
Via Opera Pia 15
16145 Genova, Italy
agostino@itim.unige.it, roberto@itim.unige.it, revetria@itim.unige.it
Report Finale: Gestione Integrata di Sistemi Produttivi Interagenti: Metodi Quantitativi Avanzati per la Quick Response
Coordinatore Scientifico del Programma di Ricerca:
Roberto Mosca, DIP, Universita di Genova
Responsabili Scientifici delle Altre Sedi Consorziate:
Martino Bandelloni, SITI DE, Universita' Firenze
Gino Cardarelli, DE, Universita' dellAquila
Marco Garetti, DIG (ex-DEP), Politecnico di Milano
Alfredo Lambiase, DIMEC, Universita' di Salerno
Marcello Lando, DIMEG, Universita' di Napoli, Federico II
Giovanni Mummolo, DIMEG (ex-DPPI), Politecnico Bari
Permission is granted to photocopy portions of the pubblication for personal use and for the use of students providing credit is given to the MURST Project n.9909112115 "Gestione Integrata di Sistemi Produttivi Interagenti: Metodi Quantitativi Avanzati per la Quick Response", Roberto Mosca. Permission does not extend to other type of reproduction nor to copying for incorporation into commercial advertising nor for any other profit-making purpose. Other publications are encouraged to include 300 to 500 word abstracts or summaries for any chapter included in this book providing credit to the author and to the MURST Project n.9909112115 "Gestione Integrata di Sistemi Produttivi Interagenti: Metodi Quantitativi Avanzati per la Quick Response" Roberto Mosca
Obiettivo di questo progetto è stato la costruzione di reti di simulatori gerarchici interagenti on line per la quale, in base all'esperienza acquisita nel lavoro effettuato dal gruppo genovese del DIP, il programma della ricerca si e articolato in tre fasi principali:
Costruzione di schedulatori e di shell di simulatori in grado di consentire lo studio di una ampia casistica di impianti di produzione nel settore manifatturiero mediante riconfigurazioni snelle e amicali ma anche con interfaccia friendly nei confronti dell'utente finale.
Scelta del protocollo ottimale di colloquio tra i differenti livelli gerarchici sulla base di considerazioni sia di tipo teorico (tecnologia, economicità, rapporto prezzo/prestazione, affidabilità, etc.) che sperimentale.
Convalida della metodologia mediante applicazione ad un caso reale significativo (almeno tre livelli gerarchici)
Nella fase iniziale, della durata di 12 mesi, sono stati chiamati a partecipare tutti i gruppi di ricerca, con le loro competenze e abilità specifiche, maturate in passato, nell'affrontare il problema della programmazione multi-site e ora quello della gestione integrata del rapporto main-subcontractor.
In questa fase Genova ha provveduto a generalizzare maggiormente, con l'aggiunta di nuovi elementi e di nuove logiche, la shell OSIRIS operando a stretto contatto con il gruppo di Bari (simulatori ibridi) e con il gruppo di Firenze (costruzione automatica di modelli di simulazione).
Alla sede di Napoli è stato demandato lo studio del problema delle assegnazioni più convenienti delle diverse attività di sub-fornitura nell'ottica di massimizzazione dell'efficienza globale del sistema di produzione in presenza di più fornitori con profili diversi in termini di qualità, costo del prodotto, rispetto dei termini di consegna, etc., mentre a quello di Salerno è stato assegnato l'obiettivo di studiare i problemi di interfacciamento tra simulatori e metodologie ERP.
Le sedi di Milano e dell'Aquila infine hanno avuto il compito di studiare tipologie di schedulazioni innovative, da abbinare ai simulatori.
Nella seconda fase, della durata di 6 mesi si sono valutate possibili soluzioni alternative anche mediante sperimentazione diretta attraverso l'aiuto di aziende e di altri gruppi di ricerca con i quali esistono rapporti di collaborazione (es. Riga TU).
Lo fase finale, durata circa 1 anno, con tutti i gruppi contemporaneamente impegnati, e stata prettamente sperimentale: in esso e stata individuata una azienda tipo ed e stata modellizzata.
Lesperienza del progetto ha consentito di evidenziare le necessità di coordinamento e gestione di progetto che sono risultate una componente chiave per arrivare a completare con successo il corrente programma di rircerca. Sotto questo profilo al ruolo del coordinatore scientifico e stato affiancato quello di responsabile del progetto per quanto riguarda modellizzazione ed integrazione al fine di garantire un efficace sviluppo della ricerca.
La buona volonta dimostrata da tutti i partecipanti al progetto, nonche lo spirito di iniziativa emerso durante le diverse fasi hanno dimostrato come obiettivi ambiziosi quali quelli allorigine della ricerca fossero comunque pienamente raggiungibili.
Linnovativita legata allimpiego di tecnologie nuove e praticamente inesplorate nello specifico settore industriale e infrastrutturale, non solo ha consentito di ottenere risultati prestigiosi a livello internazionale, ma ha anche fornito uno spunto a tutti i partecipanti per mettere a frutto il meglio delle loro esperienze e tutta la loro professionalita.
Il completamento del progetto non va considerato un punto darrivo dato che tutti i partners coinvolti sono attualmente attivi in una prosecuzione di detta ricerca (progetto WILD Web Integrated Logistics Designer) destinato a sfruttare non solo questa esperienza, ma anche gli strumenti e le metodologie messe a punto, per studiare tecniche innovative di pianificazione distribuita della supply chain.
Per i contenuti relativi al gruppo di ricerca DIP Genova gli autori risultano essere Agostino Buzzone, Pietro Giribone, Roberto Mosca, Roberto Revetria, Flavio Tonelli.
Per i contenuti relativi al gruppo di ricerca DE LAquila, gli autori ed i curatori risultano Gino Cardarelli, Antonio Caputo e Gabriele Di Stefano.
Per i contenuti relativi al gruppo di ricerca DIG (ex DEP) Milano gli autori risultano essere Marco Garetti, Alberto Portioli, Sergio Cavalieri, Roberto Cigolini, Maria Caridi, Alessandro Brun, Marco Macchi, Sergio Terzi.
Per i contenuti relativi al gruppo di ricerca DIMEC Salerno, gli autori ed i curatori risultano essere Raffaele Iannone e Alfredo Lambiase, Salvatore Miranda, Stefano Riemma.
Per i contenuti relativi al gruppo di ricerca DIMEG (ex DPPI) Bari gli autori risultano essere Giovanni Mummolo, Raffaello Iavagnilio, Giorgio Mossa, Maria Grazia Gnoni, Ornella Benedettini, Ranieri.
Per i contenuti relativi al gruppo di ricerca DPGI Napoli, gli autori ed i curatori risultano essere Elisa Andrei, Marcello Lando, Roberto Macchiaroli, Maria Elena Nenni, Liberatina Santillo, Matteo Savino.
Per i contenuti relativi al gruppo di ricerca SITI DE
Firenze, gli autori ed i curatori risultano Mario Rapaccini, Mario Tucci
e Gianni Bettini.
Si desidera ringraziare per il contributo fornito il MURST e le Sedi cofinanziatrici (Politecnico di Bari, Politecnico di Milano, Università di LAquila, Università di Firenze, Università di Genova, Università di Salerno, Università Federico II di Napoli) del Project n.9909112115 "Gestione Integrata di Sistemi Produttivi Interagenti: Metodi Avanzati per la Quick Response". Un ringraziamento va a tutti i soggetti coinvolti nel suddetto progetto:A.Giannocoli, M.Loi, R.Vulcano, M.Schenone, A.Bonello, S.Pozzicotto, O.Chiambretti, A.Brandolese, A.Pozzetti, A.Sianesi, M.Taisch, P.Mancino, M. Ferretti, A.Cardamone, A.Autorino, R.Rizzo, A.Valentino, V.Zoppoli, M.Palumbo, P.Pelagagge, R.Rinaldi, M.Bandelloni.
Un ringraziamento speciale va alla compagine industriale che ha fornito il caso per la sperimentazione e la dimostrazione, indispensabile per la convalida delle teorie e delle metodologie proposte nella ricerca; in particolare si ringrazia la Piaggio Aero Industries e tutte le industrie coinvolte nella sperimentazione per la disponibilità dimostrata: Geven, Magnaghi, OMA, PlyForm, Salver, Sirio Panel.
Un particolare ringraziamento a Giorgio Garassino che ha fornito un supporto fondamentale quale subject matter expert nella convalida del modello e punto di contatto per la fase di dimostrazione.
Ringraziamo particolarmente per il contributo significativo in sede di sviluppo e sperimentazione Giorgio Vigano' e Giorgio Diglio.
Si ringraziano, inoltre, per laiuto offerto negli sviluppi della sede di Firenze: Elisabetta De Sabato, Massimiliano Mestrone, Manuele Cheli, Matteo Maurri, Nunzio Martino e Jacopo Pancani. Si ringrazia inoltre Ernesto Ippoliti per il contributo offerto nella sede di L'Aquila e Marco Baldoli per il contributo offerto nella sede di Salerno.
Un ringraziamento significativo per il supporto nella formazione relativa all'architettura HLA va riconosciuto a: R.Crosbie, K.Morse, E.M.Mantero, T.McGuire, S.Simeoni. Ringraziamo inoltre i colleghi che in altre sedi internazionali hanno collaborato con il presente progetto e con cui e' stato possibile corrispondere proficuamente per lo sviluppo di dette linee di ricerca: P.Elfrey, C.Frydman, N.Giambiasi,R.Huntsinger, Y.Merkuryev, A.Naamane, G.Neumann, M.Schumann, T.Schultze, R.Signorile, O.R.Torinco, G.Upkenis, E.Williams.
Per la parte di supporto web e design si ringraziano G.Berrino, M.Mosca, L. Patrone.
Un ultimo sentito ringraziamento va al compianto Franco
Turco che spentosi nel corso del progetto a seguito di una terribile malattia,
ha comunque corrisposto un significativo contributo e funge tutt'oggi da
ispiratore a molte iniziative fra tutti colleghi del progetto.
Gestione Integrata di Sistemi Produttivi Interagenti: Metodi Quantitativi Avanzati per la Quick Response
COMPENDIUM
Giovan Battista Perasso
Gestione Integrata di Sistemi Produttivi Interagenti: Metodi Quantiativi Avanzati per la Quick Response
Costruzione Schedulatori User Friendly per ampia gamma di casi manufatturieri
DIP, Genova
Obiettivo primario della ricerca condotta è stata la creazione di uno strumento innovativo per la gestione integrata on-line/real-time della produzione di unità operative distribuite,nell'imprenscindibile ottica della quick response, e con particolare riferimento alla sempre più diffusa pratica dell'outsourcing, pratica attuata in special modo da aziende di grandi dimensioni verso le piccole medie imprese (utilizzando per questi termini la classificazione UE su dipendenti e fatturato) e quindi di basilare interesse per quella miriade di aziende che costituiscono l'asse portante del tessuto industriale nazionale.
Risulta opportuno, per una migliore comprensione della proposta di ricerca attuale, ricordare che il "core" del ricercatore impiantista è rappresentato non dallo studio di questo o di quel componente, ma dell'impianto nella sua globalità, sia come progetto che come gestione, conformemente ai dettami della visione sistemica dell'azienda in generale e della sua produzione in particolare.
Per raggiungere gli scopi della "mission" l'impiantista utilizza talora le metodologie create da specialisti puntuali di altre discipline (dalle macchine alla ricerca operativa, dall'informatica alla fisica tecnica, etc.) per finalizzarle all'indagine comportamentale e alla creazione di regole gestionali per quel sistema, sempre ad elevata complessità, che viene genericamente definito "impianto", nell'intento di ottimizzarne la progettazione, la gestione, la manutenzione, i trasporti interni, la produzione, etc.
Pertanto se è pur vero che talora le metodologie utilizzate possono essere non di frontiera, se giudicate da chi le ha ideate e le realizza, le applicazioni che di esse ne fa l'impiantistica sono sicuramente originali, come si conviene alla ricerca applicata, e di sicura validità tecnica, scientifica ed economica.
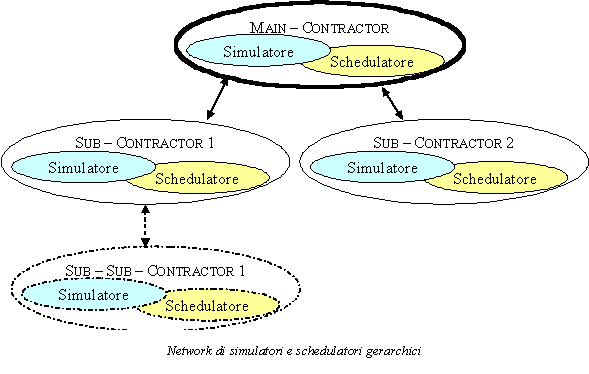
Tornano all'obiettivo della riecrca, in termini metodologici, esso e stato perseguito attraverso la creazione di network di simulatori / schedulatori gerarchicamente interagenti e attivati on line / real time al controllo della produzione.
Ogni simulatore di livello gerarchicamente inferiore (sub fornitori) e in grado di ricevere ed elaborare le informazioni di sua competenza relative a variazioni nella programmazione della produzione al livello superiore.
Sulla base di queste lo strumento locale di simulazione / schedulazione provvede alla riprogrammazione della produzione dell'unità interessata. Riprogrammazione che, poi, e sottoposta, assieme a quella di altri sub fornitori di pari livello gerarchico, al simulatore posto al livello immediatamente superiore.
Quest'ultimo, sulla base dei risultati ottenuti a seguito del loop di schedulazione / simulazione, vaglia l'accettabilità delle soluzioni proposte, rinviando al livello inferiore eventuali richieste di riprogrammazione.
Obiettivo etico della ricerca è stato, invece, il miglioramento delle relazioni tra i fornitori "forti" e subfornitori "deboli" (classicamente PMI Piccole e Medie Imprese) essendo ancora oggi troppo spesso questi ultimi costretti a dover fare le spese delle inefficienze che i prime-contractors generano nei sistemi integrati di produzione ma anche, per contro, quello di garantire ai main-contractors, il rispetto degli impegni assunti, molte volte con leggerezza, dai sub-contractors (con conseguente messa a repentaglio sia del risultato economico sia della credibilità del prime-contractor stesso).
In effetti ormai da alcuni anni ha iniziato a farsi strada l'idea di condivisione, da parte di più utenti posti in siti geograficamente diversi, di stessi complessi modelli algoritmici in generale e di simulazione in particolare; questo fenomeno è fortemente collegato anche al progressivo prendere piede di reti telematiche via via più accessibili e capillarmente diffuse, nonché alla contrazione dei costi e dei tempi del processo gestionale e decisionale ottenibili in questo modo.
Le prime applicazioni sono oramai state estesamente collaudate in settori applicativi specifici e si sta osservando una tendenza ad estendersi delle stesse a nuove aree tematiche ed a riguardare via via anche il settore industriale tradizionale.
Il settore dell'impiantistica industriale, sotto questo punto di vista, è particolarmente sensibile dato che i progetti sono da sempre fortemente caratterizzati da esigenze di coordinamento tra vasti team di lavoro distribuiti geograficamente e fortemente integrati in diverse componenti disciplinari su attività complesse; tuttavia sono state valutate anche potenzialità legate al settore dei pubblici servizi identificando un buon potenziale in questo settore per l'analisi funzionale dei sistemi.
Gli sviluppi nei settori avanzati in cui queste tecniche sono oggi particolarmente diffuse (industria aerospaziale e militare) hanno portato alla definizione di standard operativi ed allo sviluppo di nuove tecnologie applicative; l'area è molto dinamica tuttavia l'evoluzione risulta ben coordinata e permette di garantire buona operatività agli strumenti che sono in corso di sviluppo; in particolare gli standard DIS (Distributed Interactive Simulation), HLA (High Level Architecture) uniti al diffondersi e stabilizzarsi di linguaggi ed ambienti dedicati JAVA, VRML 2.0, Corba rendono possibile procedere attivamente nello sviluppo di queste applicazioni. Già dal 1996 presso il DIP dell'Università di Genova si sono sviluppate applicazioni in questo settore tematico sulla base delle esperienze maturate precedentemente nel settore della simulazione e sull'importanza di integrare questi modelli con gli utenti finali: in particolare per quanto riguarda applicazioni al settore dei progetti d'impianto (progetto VAED: Virtual Aided Engineering and Desing), al settore della Logistica distribuita (Progetto Poseidon: Port Simulation Environment for Interactive Distributed Organization & Networking), al settore dell'Analisi di Rischio e di Sicurezza (Progetti Safety First: Settore Marittimo, CIPROS: Impianti Industriali e Protezione Civile) ed altri settori che richiedono l'interattività distribuita (traffici marittimi, formazione). Alcuni demo di questi progetti sono disponibili sulla rete WEB.
Tali sistemi sono attualmente in fase di integrazione con strutture che riproducono la gestione della commessa e le varie fasi di project management e che operano direttamente sulla rete; dimostratori tecnologici di questi sistemi sono già stati sperimentati a scopo formativo sia in ambito universitario che aziendale fornendo ottimi risultati.
Come già accennato queste collaborazioni si sono svolte su base internazionale ed in particolare hanno portato a contatti e collaborazioni con altri gruppi di riferimento nel settore in Europa ed in Nord America; sono stati effettuati scambi di studenti in particolare con la Otto-von-Guericke-University di Magdeburgo (Germania), la Riga Technical University, la Bogazici University (Istanbul Turchia) ed il National Center for Simulation e lInstitute for Training and Simulation di Orlando (Florida); in effetti già da tempo il DIP di Genova è un riferimento internazionale nel settore della simulazione, nel quale è attivamente coinvolto nei principali eventi (Simulation in Industry Conference 1996); la seconda edizione (San Francisco 1999) della conferenza Web-Based Modelling & Simulation che si tiene annualmente negli Stati Uniti su queste tematiche è stata coordinata da un membro del DIP quale General Chairman. Le tecnologie esistenti spingono ad operare utilizzando principalmente sistemi basati sui linguaggi dedicati al Web-Based Modelling e quindi JAVA e VRML: per queste ragioni sono stati attivati progetti per sperimentare le potenzialità di questi strumenti nel settore relativo all'impiantistica ed alla produzione industriale.
All'inizio del 1998 il gruppo di ricerca sulla simulazione discreta e stocastica del DIP di Genova, nell'ambito di un progetto del Fondo Sociale Europeo avente come scopo la crescita gestionale di alcuni subfornitori dell'unità produttiva ligure di una azienda multinazionale, il cui "core business" è rappresentato dalla fabbricazione di elettromotrici per la trazione ferroviaria, ispirandosi in qualche misura all'idea esposta al precedente paragrafo, provvedeva a studiare prima e ad implementare poi un primo embrione di rete gerarchica di simulatori on line/real time per la gestione integrata della produzione di tre distinti sistemi produttivi interagenti a due livelli gerarchici.
I tre simulatori, uno per il main contractor e uno ciascuno per i due subfornitori, ad eventi discreti, stocastici e di grande dettaglio sono stati scritti utilizzando il linguaggio di simulazione object oriented MODSIM (CACI La Jolla - California). Ogni simulatore riceve informazioni sull'andamento della produzione direttamente dal Sistema Informativo (è possibile importare dati da diversi sistemi di ERP). Infatti il meccanismo di connessione al database permette a chi sviluppa in MODSIM di effettuare operazioni su tutti quei database per i quali è previsto un driver di tipo Open Database Connectivity (ODBC). Inoltre è possibile caricare grossi volumi di dati nel database usando direttamente istruzioni SQL nel codice MODSIM. I simulatori possono essere connessi in modo semplice attraverso uno specifico socket; la applicazioni potenziali di questa tecnologia includono sia la simulazione distribuita, dove nodi differenti sulla rete considerata sono processati utilizzando una scomposizione del modello in elementi concorrenti, sia un network di simulatori dove diversi modelli di simulazione possono interagire attraverso la rete. Questi, correttamente sincronizzati e programmati da un supervisore di sistema, calcolano le proiezioni di futuri andamenti di produzione. Allorquando, per una qualsivoglia ragione, l'andamento programmato della produzione del main contractor (con accelerazioni o decelerazioni) è differente dalla previsione, i dati di riprogrammazione, testati dal simulatore principale, con conseguente evidenziazione di eventuali criticità su date di consegna, quantità di materiali e/o di manodopera per servizi, etc., vengono trasmessi ai simulatori/schedulatori locali che provvedono ad elaborare i nuovi piani di produzione dei subfornitori (adeguando a loro volta i piani di acquisizione di materie prime, semilavorati, etc., dai subfornitori); piani che verranno, quindi, ritrasmessi al simulatore principale per ulteriori verifiche di compatibilità. Stante i tempi stretti imposti dalla ricerca il Gruppo DIP si rese subito conto della impossibilità di poter ripetere per tre volte l'operazione di costruzione di tre diversi simulatori, per cui preferì dare vita ad una shell multi purpose (denominata OSIRIS, Object Simulator Interconnected Reuseable Integrated System) che fosse, almeno entro certi limiti, facilmente adattabile alle tre realtà in studio. L'attuale fase di sperimentazione, di questa complessa architettura a rete di simulatori/schedulatori interagenti, sta fornendo risultati molto validi e prospetticamente interessanti, su un problema strategico quale quello della subfornitura.
La sperimentazione di queste tematiche sulle applicazioni registrate si è dimostrata potenzialmente molto importante ed i risultati ottenuti hanno consentito di completare la fase di analisi di fattibilità e l'identificazione di principi guida e regole per lo sviluppo di questo genere di applicazioni, con riferimento al settore della gestione di progetti distribuiti ed alla gestione di sistemi logistici; le prime applicazioni condotte hanno permesso di verificare reali la validità degli strumenti messi a punto ed i margini di miglioramento conseguibili.
Si e ritenuto quindi opportuno estendere questa ricerca per lo sviluppo di una base metodologica profonda per questo genere di applicazioni estendendo decisamente il loro uso nel settore industriale tramite un impegno comune di ricerca con altre sedi universitarie in un progetto come quello qui riproposto.
In questo progetto Genova ha provveduto anche alla messa a punto di modelli di schedulazione per la programmazione della produzione dei siti industriali costituenti la catena di subfornitura oggetto della ricerca, al fine di estendere la convalida degli studi in corso.
Per quanto riguarda l'opportunità di utilizzo di HLA la sede Genovese ha operato come responsabile della valutazione delle diverse architetture di supporto per la realizzazione delle reti di simulatori schedulatori, sviluppando moduli in JAVA e C++ nonché integrazioni per confrontare le performance di HLA con quelle di altre architetture con pacchetti di simulazione attivi quali Automod, Simul8, Arena.
Sviluppi di schedulatori intelligenti con particolari caratteristiche capaci di una visione dinsieme della rete logistica sono inoltre previsti come sviluppi in altri progetti (i.e. WILD Web Integrated Logistics Designer, che coinvolge praticamente tutti i partner del presente studio).
DEF, Firenze
Nellambito della presente ricerca è stata definita una metodologia generale per lallocazione e lo scheduling delle risorse umane in sistemi manifatturieri di tipo labour-intensive. La metodologia è stata validata in un contesto reale, relativo alla produzione di macchinari per lindustria tessile. Lapproccio seguito ha previsto la formalizzazione dei vari task di produzione con diagrammi di Gantt, la definizione dei tempi di completamento dei singoli task in rapporto ad un tempo standard di completamento (in corrispondenza dellassegnazione di un numero standard di risorse), ed infine la definizione della competency matrix degli operatori, identificando così gruppi omogenei, ai fini dellassegnazione degli addetti, dal punto di vista delle competenze possedute. Tramite un modello di simulazione dinamico, che a step regolari esegue il re-scheduling delle attività da eseguire nel reparto, è stato possibile indagare la bontà delle differenti logiche, adottate nel sistema per la gestione delle squadre di lavoratori.
La procedura ha potuto essere quindi generalizzata, fornendo le modalità di validazione dei modelli di simulazione/schedulazione e limpostazione dellarchitettura generale di analisi (basata su tecniche DOE). Sulla base delle esperienze maturate la metodologia si è dimostrata applicabile in numerosi contesti, ovvero in ogni sistema produttivo che preveda un forte apporto di manodopera qualificata, organizzata in squadre, per lesecuzione di task numerosi, simultanei, e di significativa durata, ed in cui il problema gestionale sia principalmente legato alla ricerca della migliore logica di assegnazione degli operatori (rientrando in questa casistica tutte le produzioni pesanti che richiedono assiemaggio finale, ad esempio realizzazione di impianti, grandi attrezzature, macchinari, come pure il contesto della manutenzione di impianti effettuata da personale specializzato).
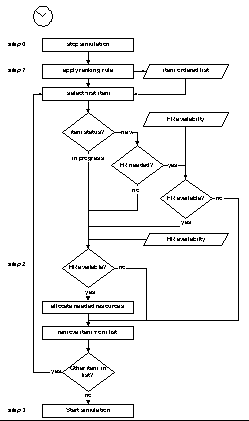
Logica di allocazione delle risorse, da cui deriva lo scheduling dei tasks.
DIMEG, Bari
In parallelo Bari ha costruito un modello di schedulazione delle attività di una produzione "per project" finalizzato alla determinazione delle date di inizio e fine delle attività del progetto nel rispetto dei vincoli:
Il modello è applicabile ad un set di N progetti
identici, corrispondenti alla realizzazione di altrettanti prodotti. Un
assegnato piano di produzione definisce la data di consegna di ciascun
prodotto, ![]() . Le attività
. Le attività ![]() del k-esimo progetto e i vincoli tecnologici fra di esse sono rappresentabili
mediante logica PERT. Si è indicato con Wk
il set degli eventi nel reticolo PERT relativo al k-esimo prodotto. Sono
stati introdotti vincoli fra attività di due prodotti realizzati
in successione a causa di uneventuale disponibilità limitata di
alcune attrezzature. Le durate delle attività
del k-esimo progetto e i vincoli tecnologici fra di esse sono rappresentabili
mediante logica PERT. Si è indicato con Wk
il set degli eventi nel reticolo PERT relativo al k-esimo prodotto. Sono
stati introdotti vincoli fra attività di due prodotti realizzati
in successione a causa di uneventuale disponibilità limitata di
alcune attrezzature. Le durate delle attività ![]() possono variare in un range
possono variare in un range ![]() in funzione delle risorse assegnate allattività
in funzione delle risorse assegnate allattività ![]() .
Maggiori sono le risorse allocate ad unattività, minore è
il tempo richiesto per la sua esecuzione. Ad un maggiore impiego di risorse
corrisponde anche un aumento del costo diretto dellattività
.
Maggiori sono le risorse allocate ad unattività, minore è
il tempo richiesto per la sua esecuzione. Ad un maggiore impiego di risorse
corrisponde anche un aumento del costo diretto dellattività ![]() .
.
Si è assunta una dipendenza lineare fra costo diretto e durata per la singola operazione:
![]()
![]() ,
, ![]()
dove:
![]() : intercetta
con lasse del costo diretto;
: intercetta
con lasse del costo diretto;
![]() : aumento
del costo diretto per lattività
: aumento
del costo diretto per lattività ![]() per unità di riduzione della durata
per unità di riduzione della durata![]()
Si è impostato il problema di schedulazione come problema di programmazione lineare finalizzato alla minimizzazione del costo diretto complessivo del progetto:
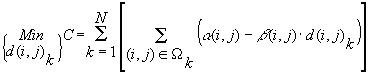
sottoposto ai seguenti vincoli:
![]() V.1
V.1
![]() V.2
V.2
![]() V.3
V.3
![]() V.4
V.4
dove:
![]() : istante delli-esimo
evento del k-esimo prodotto;
: istante delli-esimo
evento del k-esimo prodotto;
![]() : set delle
attività del k-esimo prodotto che precedono attività del
(k+1)-esimo prodotto;
: set delle
attività del k-esimo prodotto che precedono attività del
(k+1)-esimo prodotto;
![]() : evento
finale del reticolo PERT di ciascun prodotto.
: evento
finale del reticolo PERT di ciascun prodotto.
I vincoli V.1 definiscono lintervallo di tempo impegnabile per ciascuna attività. I vincoli V.2 rappresentano le precedenze fra attività diverse del medesimo prodotto. I vincoli V.3 introducono precedenze fra sottogruppi di attività di due prodotti realizzati in sequenza. Infine, i vincoli V.4 impongono che la data di completamento di ciascun prodotto sia coerente con la data di consegna assegnata.
Lo schedulatore è stato implementato mediante un solver di programmazione matematica "Whats best" - LINDO®(rel. 5.0). Tale package commerciale è in grado di risolvere problemi anche di notevole complessità computazionale; esso consente infatti di gestire un numero illimitato di variabili e di equazioni di vincolo. Si tratta di un software di facile impiego e di immediata integrazione in ambiente "Visual Basic Application" (VBA) con altri package commerciali in quanto utilizza linterfaccia di "Excel" sia per la formulazione del problema sia per la presentazione dei risultati.
DE, LAquila
Il programma di ricerca presso il team di ricerca dellAquila è stato teso allo sviluppo ed integrazione di simulatori e schedulatori per lo studio di sistemi manifatturieri complessi composti da più soggetti interagenti. La prima attività intrapresa è stata dunque la messa a punto di un sistema di schedulazione flessibile che fungesse da strumento operativo per le successive fasi della ricerca. Lo sviluppo di tale sistema di schedulazione è avvenuto basandosi su un caso di studio reale in cui le problematiche di scheduling si presentano particolarmente impegnative. Il sistema sviluppato è comunque flessibile e facilmente riconfigurabile per essere adattato ad una ampia gamma di casi manifatturieri. Lazienda scelta per lo sviluppo iniziale del sistema di schedulazione è la Italpneumatica Sud di Carsoli (AQ), struttura produttiva della SMC Italia, che produce cilindri pneumatici per il mercato italiano ed europeo. Lo stabilimento, che occupa una superficie coperta di circa 10.000 m2 con oltre 100 addetti, è organizzato in due reparti (lavorazione componenti, assemblaggio) e tre magazzini (materie prime, componenti, prodotti finiti). Lo scenario produttivo è caratterizzato da circa 1000 ordini in process per un totale di circa 4000 operazioni da schedulare su 46 macchine utensili CNC e 11 isole di assemblaggio; gli ordini di produzione provengono, allincirca in ugual misura, dal controllo delle scorte (prodotti e componenti standard) e dai clienti (prodotti non standard e speciali); le due tipologie di ordini sono caratterizzate da lead time molto diversi (1-2 mesi contro 1-2 settimane). Da circa due anni lazienda sta sperimentando in produzione il prototipo di un sistema integrato di scheduling e di controllo avanzamento produzione appositamente sviluppato nellambito di un altro progetto di ricerca applicata. Tale sistema rende disponibili un notevole quantitativo di dati sugli ordini lanciati, sui cicli di produzione, sui tempi di lavorazione e di setup, sulla disponibilità delle risorse che sono stati utilizzati per la convalida e la verifica delle prestazioni dello schedulatore.
Lo schedulatore sviluppato risulta essere di tipo euristico ed è caratterizzato dalla capacità di operare a più livelli di aggregazione dei job, cioè in grado di scegliere prima una famiglia, da questa una sottofamiglia, e infine il job. Appartengono alla stessa famiglia (o sottofamiglia) i job che richiedono lo stesso setup. Nelle successive scelte risale al livello superiore solo quando i job o le sottofamiglie del livello attuale sono esauriti. Ovviamente le regole utilizzate per scegliere un sottoinsieme di job considerano le caratteristiche di tutti i job dei diversi sottoinsiemi in competizione: ad esempio la data di consegna può essere sostituita con una variabile del tipo numero di job del sottoinsieme con data di consegna compresa in un determinato intervallo. Di fatto sono state sperimentate regole basate sulla ottimizzazione di una funzione obiettivo rappresentata da un polinomio i cui termini sono costituiti dal valore di una variabile calcolata su diverse caratteristiche dei sottoinsiemi (numero di job, tempo totale di lavorazione, tempo di setup per la famiglia, numero di job con data di consegna critica, ecc.). Una prima versione dello schedulatore è stata utilizzata per oltre un anno nella programmazione operativa della produzione della Italpneumatica. Nel corso della ricerca è stata sviluppata una seconda versione che, mantenendo le principali caratteristiche della precedente, rispondesse ai seguenti requisiti:
DIG, Milano
Lunità di Milano si è dedicata in passato alla creazione di modelli di simulazione per il mondo manifatturiero ed industriale in genere sia per la gestione e schedulazione della produzione che per la progettazione di impianti produttivi, per realtà industriali interessate allimpiego dello strumento della simulazione. I programmi normalmente impiegati partono dalla programmazione ad oggetti applicata al mondo della simulazione (SIMPLE++), ad ambienti più user friendly (Simul8, Arena, Witness).
Tramite un modello di simulazione è possibile prevedere il comportamento di un sistema nelle condizioni che prevedibilmente si presenteranno nel corso del suo normale utilizzo e funzionamento pratico. La natura assolutamente generale della simulazione ne permette un utilizzo in diversi settori merceologici e di servizio. In particolare, il suo utilizzo nelle realtà produttive e dei servizi si rivela particolarmente utile per:
Shell di Simulazione User Friendly per Ampia Gamma di Casi Manufatturieri
DIP Genova
Lo studio originario si e sviluppato a partire dalla necessita di integrare ricerche presistenti relativi alla gestione della supply chain tramite una shell sviluppata dal team Genovese per un case study di produzione locomotori (Bombardier ex ADTranz).
Detto studio e stato la causa prima del corrente progetto per cui gli sviluppi degli strumenti originariamente costruiti e lanalisi delle esperienze raccolte e risultato essere il cuore ed il motore di tutte le attivit seguenti.
Lo strumento chiave realizzato in origine, e denominato OSIRIS, forniva tutta una serie di facilities per lo studio della produzione e della logistica di impianti in modo rapido ed efficace
Architettura funzionale OSIRIS
La shell OSIRIS sviluppata nel 1998 per affrontare una serie di problemi di logistica e manufacturing e uno strumento di simulazione, che predilige il caso di impianti monoprodotto, anche se puo essere adattato a configurazioni multiprodotto. Nel caso del dimostratore relativo allaeronautica esistono due realtà: una monoprodotto Genova ed una pluriprodotto Finale. Detto questo, lintenzione iniziale era quella di adottare OSIRIS per Genova e non Finale, (a Finale si rileva la necessità di uno strumento di simulazione che sia in grado di simulare il processo produttivo di almeno 300 pezzi). Per quanto riguarda lo schedulatore (realizzato in Visual Basic 6.0 ed in grado di collegarsi ad un database esterno via ODBC con oggetti DAO), questo è stato completato e testato in riferimento ad industrie di carpenteria meccanica (i.e.PSTL OMG) ed è stato studiato per funzionare su circa 1000 articoli; la tecnica di schedulazione utilizzata è stata derivata direttamente dalle euristiche di tipo EDD e CR (con alcune modifiche per una maggiore adattabilità al caso). Questa tecnica, prevede unallocazione delle fasi di lavorazione sulle diverse macchine, presenti nel sito produttivo, ed una continua scansione sia delle risorse (ricerca di risorse nello stato di idle/busy) sia delle code a monte di ogni macchina. Queste ultime sono riordinate per ogni evento temporale significativo ai fini dellavanzamento della produzione. Eventi significativi possono essere il rilascio di una risorsa, larrivo di materiale, il guasto di una macchina utensile, ecc , riprendendo una sorta di schedulazione scan e rescan. Il sistema risulta efficace ancorche vi siano margini di ottimizzazione dal punto di vista prestazionale. La schedulazione, così effettuata, è di tipo forward e per questo in grado di guardare solo avanti nel tempo e realizza un piano di produzione teso alla saturazione delle risorse produttive od in altre parole al produrre al più presto possibile. Questo tipo di schedulazione earliness, che per sua implicita natura tende a creare elevati valori di WIP (work in progress), è stata preferita a tecniche di tipo tardiness, più eleganti ed ottimizzate, ma meno "sicure" per quanto concerne un aspetto di previsione e controllo delle consegne puntuale come nel presente progetto. Poiché la schedulazione realizzata durante lallocazione delle risorse non è in grado di considerare la stocasticità del processo, larchitettura è completata, come classico, da uno schedulatore che, prendendo come input lMPS verifica in regime stocastico il piano. Questa funzione può essere assunta da OSIRIS (al quale sono state aggiunte le opportune microistruzioni per la generazione dei messaggi da inviare sul socket per RTI). Riferendoci a questultimo aspetto si e aggiunta una macro istruzione GenMessage che se opportunamente "agganciata" ad un programma Java può inviare messaggi di testo di qualunque tipo ed unaltra di triggering (chiamata Filter) che blocca lesecuzione di un processo simulato in attesa di un messaggio dallesterno. OSIRIS è realizzato con MODSIM III, le modifiche al pacchetto non sono risultate banali ed hanno richiesto circa 1 mese uomo di lavoro e sono state completate nella prima meta del progetto. Lo schedulatore è stato realizzato in Visual Basic ha evidenziato la necessità di migliorare la gestione dei calendari di ogni macchina e dei routings alternativi, fornisce una robusta interfaccia grafica, facile ed intuitiva che permette la generazione, memorizzazione e gestione di differenti scenari in automatico, genera un MPS in formato testo separato da tabulatori completo, ed ha una sezione di analisi dei dati con grafici per ogni macchina, prodotto, cliente e per le loro interazioni, fornisce dati di sintesi relativi a ritardi, anticipi, carichi macchina in un intervallo temporale, cumulative di produzione, etc.
DIMEG, Bari
In parallelo a queste iniziative ed al fine di pervenire ad una descrizione realistica del comportamento del sistema produttivo, la sede di Bari ha costruito un simulatore che consideri, oltre alla sequenza e alla durata delle attività del processo produttivo, la presenza di fenomeni locali, quali:
Il simulatore sviluppato dallunità di ricerca del Politecnico di Bari è stato implementato in ARENA®. La scelta del software di simulazione è stata determinata da diversi fattori fra cui:
Il software è interfacciabile in ambiente VBA. Tale caratteristica ne consente la facile integrazione con moduli realizzati con altri software al fine di ottimizzare lo scheduling della produzione e, più in generale, la gestione delle risorse.
DEF, Firenze
Le applicazioni di SM&A (Simulation Modelling & Analysis) richiedono lesecuzione di una serie di fasi di modeling e di analisi che sono estremamente critiche ai fini del successo dellapplicazione. Per questo scopo, è stata sviluppata una procedura di validazione e di analisi, valida per un ampia gamma di casi manifatturieri, che si basa sulla architettura rappresentata in figura.
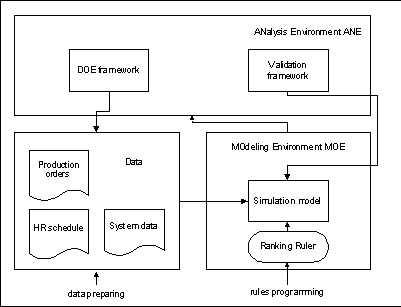
Framework per SM&A
La procedura di validazione utilizza una t-statistic,
opportunamente sviluppata, per dare evidenza della bontà dei dati
in uscita dal simulatore, mentre il framework di analisi dei risultati
del simulatore utilizza esperimenti fattoriali ed esperimenti di tipo composto
centrale. Larchitettura proposta può essere implementata utilizzando
come kernel di simulazione un qualunque ambiente che sia programmabile
dallinterno o controllabile dallesterno (praticamente tutti i principali
simulatori commercializzati). Linterfaccia utente può essere resa
quanto di più semplice da utilizzare si possa ipotizzare, e larchitettura
può essere orientata allutilizzo in tempo reale del simulatore,
nella validazione di schedule e di soluzioni alternative nella programmazione
operativa della produzione.
DE, LAquila
La sede di LAquila ha preferito orientarsi verso lutilizzo di un ambiente di simulazione per sistemi manifatturieri ad eventi discreti general purpose di tipo commerciale anziché sviluppare uno shell di simulazione ad hoc. Lambiente di simulazione prescelto è ARENA della System Modeling Corp., sviluppato sulla base del linguaggio dedicato SIMAN. A tale scopo è stata acquisita la Release 4 del pacchetto software in versione multilicenza al fine di permettere la simulazione contemporanea su più computer in rete.
Motivazioni della scelta sono state le seguenti:
DIMEC, Salerno
Il software di simulazione scelto, per la realizzazione del modello, è "ARENA Professional Edition" della System Modelling Corporation. Tale pacchetto si caratterizza per la estrema semplicità di sviluppo di modelli di simulazioni che hanno per oggetto realtà industriali.
Arena è un pacchetto software che consente di costruire modelli costituiti da moduli; la collocazione di un modulo allinterno della shell grafica equivale alla scrittura di un blocco funzionale in linguaggio SIMAN.
Gli elementi caratteristici dellambiente di simulazione, che consentono il corretto funzionamento del modello progettato, sono essenzialmente due: i moduli e le entità.
Il software, grazie ad una shell di progettazione molto semplice ed intuitiva, consente di costruire, mediante moduli opportuni, che possono essere di alto o di basso livello, tutte le fasi logiche e di processo dellazienda che si intende modellare e di collegarle secondo la logica desiderata.
I moduli consentono tra laltro di realizzare sia delle fasi produttive quali stazioni di processo, code, magazzini, stazioni di ispezione, carico/scarico da carrelli, risorse, trasporti, ecc., sia delle fasi logiche quali decisioni, assegnazioni di attributi, esecuzione di porzioni di codice Visual Basic, ecc.
Le entità sono degli oggetti che movendosi allinterno del modello tra i vari moduli rendono possibile la simulazione; esse possono rappresentare dei semplici flussi logici oppure dei prodotti che evolvono allinterno del sistema.
I moduli posizionati nella shell svolgono le operazioni preposte soltanto quando le entità li attraversano; ciò rende possibile sviluppare ed in seguito verificare il funzionamento del modello in modo molto semplice; infatti, quando il modello viene eseguito, la shell di progettazione diviene una finestra di visualizzazione che consente di vedere graficamente il passaggio delle diverse entità allinterno del sistema, nonché di verificare le operazione svolte dai moduli.
Al termine della simulazione lambiente offre la possibilità di visualizzare un report che contiene tutte le informazioni relative alla simulazione appena svolta.
DPGI, Napoli
Per la realizzazione del modello di simulazione, si è dovuta operare una scelta tra le diverse possibilità offerte dal mercato in termini di software di simulazione. Tale scelta ha privilegiato il software di simulazione "ARENA Professional Edition" della System Modelling Corporation. Il pacchetto si caratterizza per la estrema semplicità di sviluppo di modelli di simulazioni che hanno per oggetto realtà industriali.
Non ultima tra le motivazioni che hanno condotto a tale
scelta è la competenza già posseduta dai componenti dellunità
operativa di Napoli nello sviluppo di modelli di simulazione con tale applicativo.
Stato dellArte e Sistemi Preesistenti
DIP, Genova
Essendo OSIRIS ovviamente uno sviluppo originariamente legato ad una applicazione particolare, ancorche sufficientemente complessa da risultare rappresentativa, si sono evidenziati nel suo impiego una serie di limiti di generalizzazione che il presente progetto si e prefisso di correggere ed integrare.
La sede di Genova ha quindi inizialmente lavorato sull'evoluzione della shell di simulazione OSIRIS definendo i formati file idonei all'interfacciamento con sistemi ERP (Enterprise Resource Planning) e realizzando nuove istruzioni che consentono l'accesso dinamico a Database SQL; la shell attualmente risulta operativa anche in ambiente Windows NT, mentre l'implementazione Unix e l'interfaccia Java sono state sospese a favore di altri tools dedicati piu' efficaci visto anche che il motore di base (Modsim III), dopo lacquisto di CACI da parte di Compuware, ha un futuro incerto e potrebbe risultare non più economicamente manutenibile; la costruzione dei nuovi tools si è basata sia sull'impiego di Automod/Autosched, tools sul cui impiego esiste una collaborazione tra DIP e Ford Motor Company (Detroit U.S.A., Dott. Edward Williams), che sullo sviluppo di tools ad hoc in Java e C++.
Passaggio di OSIRIS su Unix e NT
Il software utilizzato per lo sviluppo dellapplicativo
OSIRIS, MODSIM III di Caci Products Company, aveva tra le sue caratteristiche
di rilievo, la possibilità di operare senza modifiche al codice
sia in ambiente Microsoft Windows che in ambiente UNIX. Questo è
stato possibile fino alla versione 1.3.2 del prodotto stesso (versione
attuale 2.3.0), versione oggi non più supportata a causa del passaggio
di proprietà del prodotto stesso alla società CompuWare.
Questultima avendo abbandonato, per i prodotti di simulazione la piattaforma
Unix, non ha ritenuto fosse di rilievo strategico la migrazione e laggiornamento
del linguaggio di simulazione in ambiente Unix, decidendo per la sospensione
delle chiavi di attivazione delle vecchie licenze (queste andavano ripristinate
una volta allanno). CompuWare inoltre ha deciso per la totale sospensione
del pacchetto a partire dallanno 2001, fornendo però in questo
caso una licenza permanente duso per la piattaforma Microsoft (con software
identico per il S.O. NT e 98). La CompuWare rimane ad oggi disponibile
a fornire tools di simulazione, purtroppo non più compatibili
con il codice MODSIM generato, che ritiene maggiormente innovativi e funzionali.
I test ad oggi prodotti sulla piattaforma NT hanno dimostrato unottima
funzionalità sia in termini di affidabilità del codice prodotto
che dellefficienza dello stesso. Il linguaggio di simulazione è
stato utilizzato per circa dieci applicazioni differenti (modelli di microtraffico,
configuratori di impianto, shell di schedulazione, sistemi integrati) dimostrando
solo qualche carenza nellambito dellinterfaccia grafica povera sia in
termini di estetica che di funzionalità ed implementazione, costringendo
molte volte alla generazione della stessa attraverso altri tools
di sviluppo quali ad esempio Microsoft Visual Basic (I2 techologies con
il prodotto Supply Chain Strategist) ed un motore di schedulazione in MODSIM
III. Buoni i test sulla gestione dellI/O, efficacemente supportato dal
driver
ODBC. Sufficiente il giudizio sulla gestione dinamica della memoria non
sempre in grado di deallocare processi di cui si è autorizzato da
programma il dispose vincolando in questo modo lunghe simulazioni.
Insufficiente per quanto riguarda il supporto del protocollo HLA supportato
in un primo momento ed successivamente ritirato (specifiche non conformi)
a partire dalla versione 1.3.5, mai più ripristinato. Altrettanto
non può essere detto per lambiente Microsoft Windows 98 che presenta
alcune lacune di compatibilità in funzione del sistema utilizzato
(italiano od inglese ad esempio), lacune riscontrate a livello delle librerie
dinamiche di gestione della visualizzazione delle interfacce difficilmente
risolubili e non documentate (se ne sconsiglia quindi luso in ambiente
98). Valgono gli stessi risultati degli altri tests in ambito NT
qualora il programma non presenti interfaccia grafica.
Nuove Microistruzioni Sviluppate per OSIRIS
Le microistruzioni attualmente implementate sulla versione
di OSIRIS (Object Interconnected Reusable Integrated System release 2.1)
sono 15 e possono essere riassunte come segue:
| Assembly | This assembly operation transforms
different items in work in process or finished goods.
Fields: Work in process name or item name needs to be assembled (Identifier); Needing mechanical resource name to make possible assembly operation (Resource to assembly); Assembly operation learning curve can be associated to current work in process or product (Learning curve button). In combo box list are presented all learning curve defined in Operation list in Operation Learning Curve window; |
|
| Delay | This elementary operation means
simulation time elapsing (each working operation can be modeled through
time parameter definition).
Fields: Identifier; Operation time (Waiting Time), statistics distributions can be chosen, and expressed in hours unit time; |
|
| End | Involves process execution end;
Process
end detail dialog box appears equal to Message detail
dialog
box. End operation isnt a real elementary operation but a process-end
message.
Requested data are: Message identifier; Message type; Items name; it will be used to refer items in system buffer; Message sender object; Message receiver object; Time to wait before sending message; Quality (not used); Quantity (not used); Broadcast message check box. End operation is set to terminate each process. It is important to underline End operation performs message sending such as DEP.ini, PUSH OBJECT or PROCESS COMPLETED, if trace file is required; |
|
| Filter | Filter operation allows process
interrupt until some event occurs (a message for instance).
Identifier; Message list in which user defines messages have to be received to start again process; |
|
| GenMessage | This operation is able to generate
external message with a specific text message.
Fields: Identifier; Kind of Action combo box allows actions selecting to execute when message arrives; New Action button features new action creation; Edit Action button features message setting modifying; Message button features message type definition to wait for activation; |
|
| Get | This operation involves item or
product request.
Fields: Identifier; Requested object name; |
|
| GetHum | This operation involves human
resource request.
Fields: Identifier; Resource List button allows to access human resource list previously defined in Human Resource creation process. Get human operation requires only once resource. When resource isnt available model manager puts unsatisfied request in FIFO queue until some resource will become free. Fields: Identifier; Human resource name; Resource number to acquire; |
|
| GetMech | Mechanical resource operation. Dialog box and fields in this elementary operation are equal to GetHum operation settings; | |
| Message | Through this operation it is possible sending messages to active objects. Messages are used to synchronize activities between objects. Message button actives message definition window; | |
| MoveTo | Simulates work in
process transportation across layout (for instance from a work-centre to
other).
Fields: Identifier; Travel Time, expressed in hour unit time. Combo box allows to choice proper statistics distribution; Destination gate; |
|
| Release | Release resource operation previously acquired and used for process. It becomes immediately available to satisfy further requests. Dialog box use is equal to GetHum and GetMech operations; | |
| Test | Test operation allows
process final testing to verify item or product quality.
Like assembly operation, test operation is usually associated to progress or learning curve. Fields: Identifier, for instance TEST_INVERTER; Necessary resource to execute test operation (Resource to test), for instance TEAM_TEST; Learning curve related to a particular product type. Combo box shows all implemented curves. They are defined in Operation list menu by filling in Operation Learning Curve. |
|
Aggancio Moduli ODBC/SQL OSIRIS
Attualmente sono state sviluppate due differenti modalità di collegamento ad un database compatibile con il driver ODBC. Il test più esaustivo è stato eseguito sul database di tipo SQL (Microsoft SQL 7.0), ma lo stesso programma ha fornito risultati soddisfacenti anche con database di tipo DBF. Esiste inoltre la possibilità di sfruttare le funzionalità, via ODBC, ad un database di tipo ORACLE™.
Interfaccia Microsoft Excel OSIRIS
Lo sviluppo in ambiente Microsoft Excel™ può essere riadattato modificando i soli trace records che sono definiti allinterno del database aziendale; il collegamento avviene attraverso drivers ODBC con oggetti OLE ed infine comandi ActiveX Microsoft.
Il sistema, inoltre, dispone dei comandi e delle procedure necessari allinterazione con lo schedulatore descritto ai punti precedenti, è cioè in grado di generare i files nel formato richiesto dallo schedulatore. Il front-end realizzato fornisce allo schedulatore ed ad un eventuale modello di simulazione tutti i dati necessari per operare unattività di pianificazione e programmazione della produzione; utilizzando le maschere presenti, è possibile variare tutti i parametri del processo produttivo (quali operatori, macchine utensili, tempi, etc.), modifica che consente di valutare i risultati ottenibili attraverso eventuali nuove definizioni dei criteri gestionali dellintero ciclo produttivo (generazione degli scenari). Con operazioni estremamente semplici e rapide, si possono modificare i parametri sulla base dei quali effettuare lanalisi, allo scopo di verificare le possibili variazioni della risposta ottenuta in uscita dal schedulatore.
Infine il sistema dispone di comandi necessari allattivazione delle procedure di salvataggio dei dati, contenuti nel database di origine, nel corrispondente formato ASCII standard.
Interfaccia Visual Basic OSIRIS
Qualora la definizione degli input da fornire allo schedulatore richieda la riformattazione dei dati, confrontando i parametri richiesti dallo stesso rispetto a quanto presente direttamente nel database del sistema informativo aziendale (S.I.A.), è possibile sviluppare un modulo per limportazione, il filtraggio e la manipolazione dei dati e la loro conversione nel formato richiesto dallo schedulatore.
Per facilitare l'utilizzo di tale operazione è opportuno utilizzare un front-end di facile consultazione ed allineato con il database originale; è stato quindi realizzato un modulo tramite lutilizzo del linguaggio di programmazione Microsoft Visual Basic 6 (Enterprise Edition). La scelta è stata dettata dai seguenti requisiti fondamentali:
Il linguaggio di programmazione Visual Basic, è uno degli strumenti migliori per creare facilmente e rapidamente applicazioni in ambiente Windows, in quanto fornisce una serie di oggetti che permettono di semplificare la fase di sviluppo del programma. La parte Visual si riferisce al metodo utilizzato per creare linterfaccia utente di tipo grafico (la cosiddetta GUI: Graphical User Interface). Infatti senza dover scrivere necessariamente codice è possibile creare facilmente linterfaccia dellapplicazione che si sta implementando, utilizzando una serie di moduli base forniti dal programma.
La parte Basic fa riferimento al linguaggio BASIC (Beginners All-Purpose Symbolic Instruction Code), di cui risulta evidente la facilità con cui questo modulo può essere modificato, anche da personale non esperto, in vista di successive modifiche.
Visual Basic, come tutti i più moderni linguaggi di programmazione, supporta una serie di costrutti di utilizzo comune oltre che una serie di caratteristiche specifiche dovute alla sua peculiarità di essere un linguaggio di programmazione orientato agli oggetti e guidato agli eventi.
Inizialmente occorre definire le caratteristiche visualidellapplicazione che sono rappresentate sullo schermo attraverso lutilizzo delle cosiddette "form", ad ognuno di esse è associato un modulo di codice (form module con estensione .frm) che contiene le procedure ad eventi relative a quel "form" ed a tutti gli oggetti che comprende; queste sono procedure che eseguono un comando in risposta ad uno specifico evento che si è verificato in precedenza o che è stato determinato dallesterno. In aggiunta alle procedure ad eventi il "form module" può contenere delle procedure generali, indipendenti da qualsiasi "form", che sono definite in un altro modulo standard (standard module con estensione .bas). Per quanto riguarda la parte visuale è possibile utilizzare una serie di controlli standard che sono tipici delle applicazioni Windows quali ad esempio pulsanti, etichette, caselle di testo, pulsanti di opzione o menù a tendina, risulta inoltre essere possibile creare controlli personalizzati oppure recuperare controlli tipici di altri applicativi, quali ad esempi i fogli di lavoro di ExcelTM o le tabelle di AccessTM.
Nella fase di realizzazione del modulo d'importazione e gestione dei dati dall'archivio informatico di unazienda si è utilizzata una libreria di oggetti di Visual Basic 6 dedicata alla gestione dei database: la libreria DAO. Il modulo DAO è costituito da un insieme di oggetti che determinano la struttura di un sistema di database relazionale; con le proprietà ed i metodi dagli oggetti DAO è possibile eseguire tutte le operazioni necessarie per gestire tale sistema, tra cui la creazione di database, la definizione di tabelle, campi ed indici, la relazione fra tabelle e l'esecuzione di queries nel database stesso. Le librerie DAO sono state le prime a disporre dei tools necessari ad effettuare sia la gestione di database Microsoft Jet, ovvero il modulo utilizzato da Microsoft AccessTM, ed a consentire la connessione diretta a tabelle di AccessTM e ad altri tipi di database tramite ODBC.
Nel modulo DAO sono disponibili quindici oggetti, tra cui ricordiamo i principali:
Spesso per alcuni gruppi è possibile procedere alla semplice estrazione dalle tabelle del S.I.A. utilizzando direttamente il linguaggio SQL nelle procedure di Visual Basic e quindi sfruttando la potenzialità degli oggetti DAO di connessione diretta al database Access.
Il front-end è molto semplice ed interattivo e, grazie ad una serie di pulsanti di comando e di menù a tendina, permette di accedere agevolmente agli altri pannelli del programma; ogni comando riporta lindicazione del modulo a cui si sta accedendo completata da unicona che richiama la funzione del modulo in questione. Il pannello principale permette, grazie a menù a tendina, di visualizzare direttamente il pannello modifica di ogni singola tabella del database locale per attuare le variazioni da apportare allo stesso prima della conversione dei file nel formato desiderato. I moduli che completano linterfaccia sono sostanzialmente tre:
Il modulo di modifica del database, avviene su di una copia locale; questo presenta una serie di pulsanti di comando che riepilogano tutte le categorie di tabelle; una volta selezionata la tabella desiderata si accede ad un modulo dedicato che può essere utilizzato in due modalità distinte: con i tasti di modifica disabilitati od abilitati. Nel primo caso, è possibile utilizzare la barra di scorrimento associata alla tabella per evidenziare ogni singolo record con tutti i campi principali: in questa modalità non è possibile apportare modifiche a nessun dato contenuto nel database fino a quando tramite la selezione di un option button non si sono attivati tutti i tasti di modifica ed i text box relativi ad i record della tabella. Trovandosi, quindi, nella modalità di modifica dei record vi è la possibilità di compiere tre specifiche azioni sulla tabella:
Interfaccia collegamento ORACLE (via ODBC) OSIRIS
Nelle available references di Microsoft Visual Basic non si hanno di default le librerie di ORACLE quali ad esempio ORACLE InProc Server 3.0 Type Library. Al fine di creare una connessione ORACLE dobbiamo creare una DSN dedicata. E possibile utilizzare un controllo Oracle precedentemente scaricato dagli Ado Data Control components. Visualizzando le proprietà del comando ADO è possibile collegare lo stesso al DSN seguendo questa procedura:
selezionare dal Data Link Properties: 1) Microsoft OLE DB Provider For ODBC DRIVER, 2) Collegare la stringa: Build, 3) Connection + collegamento stringa + build + Machine data source + selezionare la DSN. Per creare una DSN: START + Settino + Control Panel + Data Source ODBC + System DSN + Add + Microsoft ODBC for ORACLE. E necessario quindi impostare il Data Source Name, lUser Name, la Password ed infine il Server (il SID del Server). A questo punto è necessario collegare il controllo Datagrid al controllo ADO ed rendere visibile loutput del codice SQL direttamente memorizzato su DataSource.
A questo seguono operazioni di installazione delle librerie dinamiche richieste (Nsusr32.dll in C:\winnt\System32) e la dichiarazione di tutte le variabili.
Link Java OSIRIS
Non essendo ancora disponibile, al momento del primo sviluppo prototipale della configurazione schedulatore/simulatore OSIRIS (1998), un protocollo di trasferimento delle informazioni che permettesse di collegare insieme differenti unità operative (con il termine unità operative si intende il software e la sua implementazione su di una base dati per ogni realtà di sub fornitura ed una di controllo e supervisione per il main contractor), un primo pensiero era andato alla realizzazione di uninterfaccia di trasferimento dei dati di output, e delle relative sincronizzazioni, attraverso la rete internet. E allora immediato capire il perché questa soluzione abbia preso, per lo meno in considerazione, lutilizzo di un link realizzato con tecnologia Java. La scarsa affidabilità della rete internet ed il continuo susseguirsi di nuovi rilasci di versioni del linguaggio hanno, almeno in quella prima fase, spinto lo studio verso una soluzione che fosse semplice ed affidabile. Questo compromesso tra prestazioni e risultato è stato ottenuto facendo dialogare in modalità off-line le differenti unità operative, utilizzando la rete internet ed il protocollo FTP. Ogni unità operativa era dunque in grado di elaborare le proprie proiezioni, sia in regime deterministico sia in regime stocastico, inviandole ai livelli superiori. E evidente come questa soluzione sia carente dal punto di vista della sincronizzazione del tempo (richiesta di elaborazione da parte dei livelli superiori al fine di effettuare una previsione dei piani di produzione in tempo utile) limite, al tempo, valicato attraverso richieste in formato elettronico dei risultati intermedi necessari allattività di pianificazione. Evidente appare quindi linteresse suscitato da una tecnologia come HLA che permette, non solo di sincronizzare opportunamente le richieste di una attività di pianificazione a ritroso, a priori difficilmente identificabile ma anche di, ma anche di svincolarsi dal problema di unità operative non interconnesse tra di loro se non nei termini dei loro risultati.
I limiti sperimentati nellintegrazione HLA di OSIRIS hanno comunque indirizzato a sospendere ulteriori sviluppi in questo senso a favore della costruzioni di sistemi di integrazione JAVA multipurpose (i.e. HORUS descritto nel seguito).
Aggancio ad ERP tipo SAP/3, BAAN, JD Edwards OSIRIS
Data la complessità funzionale dei sistemi transazionali nel caso di integrazione con OSIRIS si e deciso di estendere la parametrizzazione dei modelli in modo da garantire un esteso caricamento da file ASCII della configurazione; questo approccio ha consentito di lasciare in modo semplice ed efficace la possibilità di integrazione con ERP a fronte di programmi di interfaccia; detto sistema e stato sperimentato attualmente sia con sistemi custom di nuova generazione che, quantomeno in via preliminare con sistemi ERP presso alcuni dei case study in esame.
Convalida delle capacità di Generalizzazione di OSIRIS sul Caso Piaggio AeroIndustries
A seguito di alcuni meeting avuti in Piaggio (stabilimento di Finale ing.Maurizio Troya e ing.Gianpietro Ciravegna) sono emerse alcuni fatti, noti, che possono essere nel seguito brevemente riassunti: le previsioni di vendita per i velivoli P180 sono di 15 velivoli per lanno 2000 e di 25 per il 2001. Il suddetto velivolo è composto da circa 15,000 pezzi, pezzi che sono costruiti o completati nella sede di Finale per una parte consistente. La produzione di Finale Ligure può essere articolata seconda una suddivisione data dal 35-40% per la produzione Falcon (main contractor Alenia), 20-50% P-180 (main contractor Finale Genova), 15-30% per motoristica e revisioni (suddivisione variabile nel corso del 2000/2001). Lo stabilimento conta un organico di 1250 persone tra diretti ed indiretti. Il fatturato, ha visto negli ultimi due anni un incremento del 70-80% con un passaggio da 140 Mld del 1999 agli attuali 230 Mld. Di questo, cospicua quota, è rappresentata dalla produzione del P-180.
La produzione di Finale Ligure è articolata su circa 9,000 part number di cui per esigenze di modellistica (shell OSIRIS) si focalizzeranno sui 1000 particolari critici. I 1000 part number considerati, completamente tempificati, sono sostanzialmente tutte quelle operazioni manuali che richiedono una schedulazione ed una simulazione. Il P-180 viene assemblato nello stabilimento di Genova, dove, la presenza di numerosi scali di assemblaggio permette la composizione dellintero veicolo a partire da sottoassiemi di livello 1.
Osiris ha acquisito le informazioni per il modello di produzione dal sistema informativo utilizzato in Piaggio
Si ritiene utile, in questa breve nota, descrivere sommariamente il sistema informativo aziendale utilizzato allinterno dei due stabilimenti, rispettivamente, Genova e Finale Ligure. Il sistema informativo, basato su architettura IBM 2030/OS390, compie oggi 25 anni ed è stato completamente realizzato allinterno dellazienda ed utilizza conseguentemente un formato dei dati proprietario, esiste oggi un progetto di implementazione di un moderno sistema ERP (probabilmente SAP R/3). Il sistema è in grado di gestire un database di tipo gerarchico denominato IMS, ma ha la possibilità di esportare dati in formato DB2 così da poterlo utilizzare con un driver SQL. In realtà, come spesso accade in questi casi, dalla teoria alla pratica il passo è lungo ed il processo di estrazione e filtraggio dei dati richiede un primo ed obbligatorio step da parte dellufficio sistemi informativi che scrive le opportune queries di interrogazione basandosi su quanto richiesto e ovviamente sul trace record. In sintesi il processo è identificabile in 2 passi: interrogazione dellMVS e trasferimento delle informazioni su stazione remota via FTP del file di testo formato DB2.
I dati impiegati da OSIRIS possono essere brevemente riassunti come segue: diagrammi flussi logistici, diagramma del processo produttivo, lista part number, lista dei processi e dei tempi (cicli tecnologici), lista macchine (CDC) capacità produttive e flessibilità, gradi di libertà sul sistema quali outsourcing, turnazione, lavoro interinale, condivisione capacità produttive con altre produzioni.
Il modello sviluppato con OSIRIS e stato convalidato sui dati disponibili evidenziando prestazioni soddisfacenti; le valutazioni relative al carico dei magazzini in funzione dello sviluppo di produzione legato al P180 hanno evidenziato la necessità di procedere nellanalisi della supply chain.
Il sistema di integrazione ERP consentirà di acquisire i dati esportabili tramite transazioni dal nuovo ERP e di mantenere up-to-date la simulazione.
A seguito di questa esperienza si e potuta verificare la flessibilità e la capacità di generalizzazione assunta dal simulatore OSIRIS a seguito degli interventi legati a questo progetto; tuttavia la capacità di integrarsi in federazione HLA cosi come la velocità di esecuzione del modello e la complessità di sistema affrontabile hanno fatto preferire proseguire con altre linee applicative in parallelo piu efficaci nello sviluppo di federazioni di simulatori..
DPGI, Napoli
Preliminarmente alla fase di sviluppo vero e proprio del modello di simulazione si è proceduto ad una valutazione del software da adottare. Tale fase ha tenuto conto delle caratteristiche fisiche e logiche del sistema da modellizzare e delle caratteristiche tecniche che si intendeva conferire al modello stesso di simulazione.
Il problema di sincronizzazione del tempo simulato, infine,
è stato risolto mediante lutilizzo di un blocco VBA, periodicamente
eseguito allinterno del modello, che interrompe lesecuzione della simulazione
fino allarrivo su una delle porte socket di un messaggio per il prossimo
appuntamento. Linsieme delle funzionalità descritte hanno consentito
la corretta integrazione in ambiente HLA.
Simulatori Ibridi
DIMEG; Bari
Il ricorso alla modellizzazione ibrida di sistemi produttivi, ossia alla integrazione ed interazione di modelli di programmazione matematica e di simulazione ha consentito di determinare pianificazioni aggregate della produzione rispondenti a predeterminati obiettivi tecnici ed economici e di valutare la fattibilità di tali piani attraverso modelli di simulazione.
I modelli ibridi realizzati sono costituiti da due moduli fondamentali interagenti in ambiente VBA. Un primo modulo provvede alla determinazione della dimensione dei lotti di produzione ed al loro sequenziamento risolvendo un problema di "Lot Sizing and Scheduling" multiprodotto, a capacità produttiva limitata, con lobiettivo di ottimizzare una funzione economica dipendente da costi di produzione, costi di setup e costi di immagazzinamento. Il loading del sistema è simulato da un simulatore (secondo modulo) che considera tutte le specificità del sistema produttivo indagato fra le quali: i tempi di guasto e di riparazione, tempi di setup stocasticamente variabili e dipendenti dalla sequenza dei lotti di produzione. Il simulatore fornisce di ritorno allo schedulatore informazioni più affidabili sui tempi medi di setup e sulla capacità effettiva dei centri di lavoro. Queste informazioni consentono di rielaborare un nuovo e più affidabile piano di produzione. La procedura iterativa si arresta sulla base di predefiniti criteri di convergenza sulle prestazioni del sistema produttivo.
La modellizzazione è stata applicata a casi industriali in piena scala. Si tratta della produzione di componenti di sistemi frenanti per autovetture prodotti negli stabilimenti di Bari, Crema e Offanengo. Inizialmente, la modellizzazione ha interessato un singolo sito di produzione (il sito di Bari) al fine di testarne le capacità ed i limiti. Successivamente essa è stata estesa alla intera catena produttiva .
Lapproccio ibrido è stato adottato anche per lallocazione ottimale delle risorse di produzione di una unità produttiva facente parte di una supply chain. Dopo aver indagato i modelli di allocazione ottimale delle risorse disponibili in letteratura, è stato realizzato un modello ibrido che riproduce il comportamento della singola unità produttiva.
La cooperazione con le importanti realtà produttive oggetto di studio ha messo in evidenza il bisogno di disporre di strumenti metodologici ad un tempo semplici ed in grado di rappresentare problemi di interesse industriale.
Per questa ragione le modellizzazioni ibride "locali" e "globali" della catena sono state realizzate attraverso strumenti informatici di larga diffusione e basso costo, quali, come già detto, il solver LINDO® ed il package ARENA®. Si tratta di strumenti "user friendly" molto orientati alluso integrato anche da parte di non esperti di modellistica e, pertanto, di agevole applicazione ed uso in ambito industriale.
Risultati ottenuti:
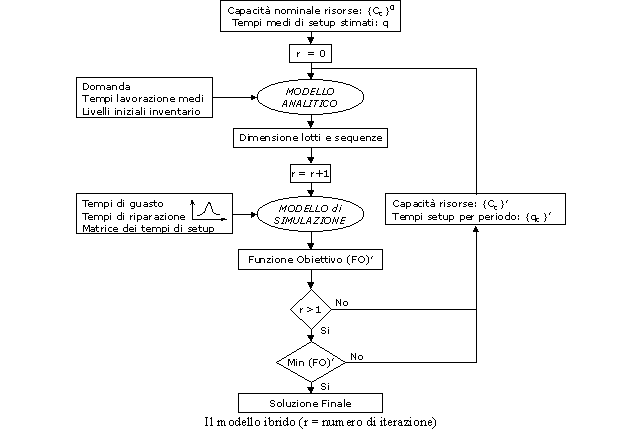
Simulatori Generati Automaticamente
DEF, Firenze
La maturità raggiunta dagli strumenti e dagli ambienti di simulazione oggi disponibili sul mercato, anche per i vantaggi derivanti dallintroduzione della programmazione orientata agli oggetti, nonché le attuali architetture run-time di tali strumenti, che consentono lo scambio dati con ambienti esterni (in modalità ODBC per lacceso ai dati, OLE/DDE per lo scambio di oggetti, tramite interfacce specifiche per la lettura-scrittura di file, tramite lapertura di socket e luso di protocolli EDI, MAPI, X400/X500 per lo scambio di messaggi e dati su rete LAN/WAN/internet), oltre che lintroduzione di potenzialità di tipo controlling outside e/o programming inside, fanno della simulazione uno strumento estremamente potente nellambito del PP&C, per effettuare analisi di scenario in tempo reale, per la verifica di alternative di scheduling e dispatching, e per quantaltro richiesto dai practitioner del citato contesto.
Lintegrazione con gli strumenti tipici dellarea gestionale (come ad esempio, software per la schedulazione, ERP) ha evidenziato ancor più il problema di rendere tali applicazioni alla portata degli utenti dei suddetti sistemi. Per questo fine, lostacolo principale è certamente costituito dalla difficoltà insita nel modelling del sistema produttivo e delle sue strutture ed infrastrutture, nella formalizzazione dei suoi vincoli e delle logiche di funzionamento e controllo.
Lidea alla base della ricerca è quella di sviluppare un approccio formale per il modeling dei sistemi produttivi, che consenta di generare automaticamente un modello di simulazione a partire da una rappresentazione completa degli oggetti appartenenti al sistema e delle loro relazioni, oltre che da un insieme di dati strutturato che descriva il loro stato corrente.
Per questo fine, seguendo il formalismo UML, sono state sviluppate delle view per identificare le classi di oggetti necessarie al fine di rappresentare un generico sistema di tipo manifatturiero, con riferimento alle strutture produttive (macchine, operatori, magazzini e buffer interoperazionali, mezzi di movimentazione) e loro aggregazioni (reparti, celle tecnologiche, linee di fabbricazione e/o assemblaggio).
Loggetto della produzione è stato rappresentato tramite mappatura delle informazioni elementari che legano il prodotto al processo produttivo (progettazione, ingegnerizzazione e fabbricazione), identificando nella distinta base, nelle process sheets e nelle routing sheets gli strumenti da utilizzare al fine della sua descrizione.
Infine, limpegno è stato rivolto alla classificazione
dei modelli di riferimento impiegati nel PP&C (dalla principale letteratura
sullargomento, e dalle esperienze maturate in ambito industriale), ovvero
logiche di tipo push puro (MRP e Load-Oriented Manufacturing Control),
pull puro (Kanban e Order Point), logiche ibride (combinazioni delle precedenti).
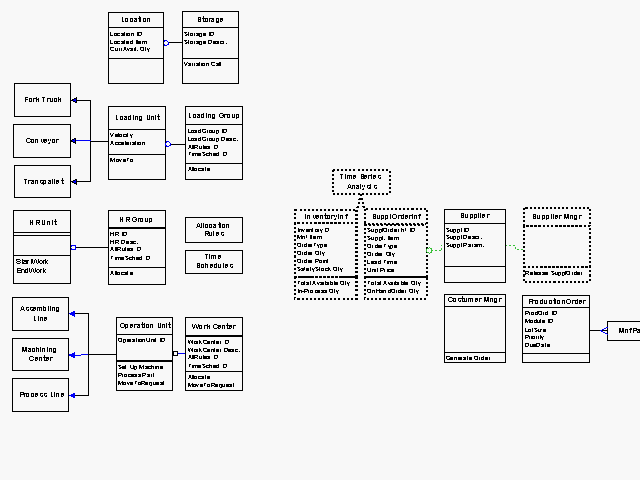
Schema UML delle classi strutturali.
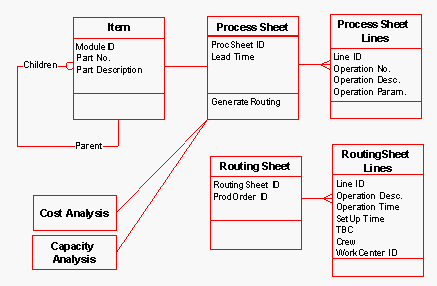
Schema UML delle classi tecnologiche.
Lanalisi condotta ha consentito di identificare le regole generali secondo cui può avvenire lo scambio di informazioni tra sistema di controllo e risorse produttive, ed ha permesso di costruire una struttura di riferimento per la successiva fase di implementazione.
Prima di procedere con laffinamento della struttura (definizione di proprietà e metodi aggiuntivi per caratterizzazioni spinte, estensione a modelli PP&C non contemplati in prima istanza), è stato ritenuto di fondamentale importanza verificare la funzionalità e la robustezza dellapproccio ipotizzato. Per questo, grazie allesperienza sviluppata nel campo della simulazione e della programmazione orientata agli oggetti, è stato fatto un primo test della struttura, utilizzando deliberatamente un simulatore disponibile in commercio. La scelta è caduta sul simulatore ad oggetti SiMPLE++, dove sono state implementate le principali classi di oggetti precedentemente formalizzate per la descrizione delle strutture fisiche e di quelle tecnologiche, ed è stata portata a termine limplementazione di alcuni modelli gestionali (MRP e kanban a doppio cartellino). Si è così ottenuto, come risultato preliminare, la generazione automatica (da una struttura di dati esterna al simulatore) di un modello ready-to-run di un sistema produttivo, opportunamente utilizzato come test bed.
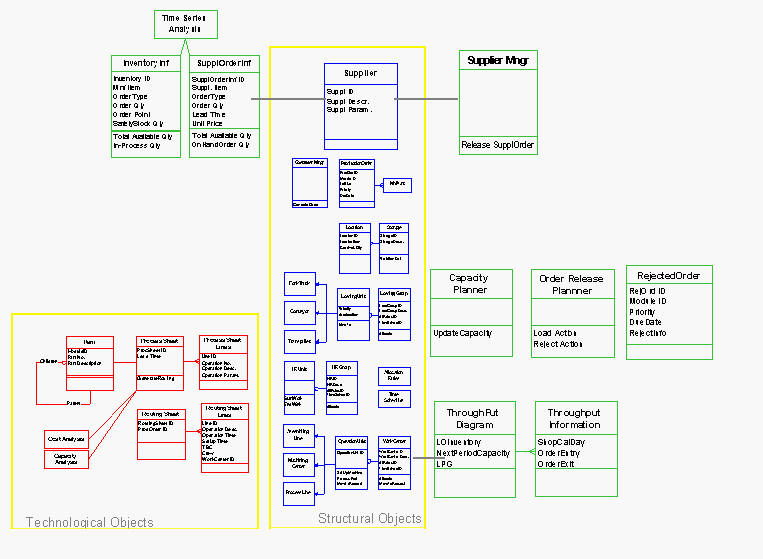
Class Diagram di un sistema gestito con logica Load-Oriented
La logica con cui ciò può avvenire è di seguito riassunta: tutte le classi necessarie a rappresentare il sistema sono presenti nella libreria del simulatore, e tramite una serie di script vengono istanziati e caratterizzati solamente gli oggetti che trovano descrizione nella struttura dati.
I vantaggi che derivano da questo approccio sono di immediata comprensione: il modello/i modelli così generati non necessitano di manutenzione, in quanto immediatamente aggiornabili (massima reusability) eseguendo ex-novo (ad esempio, in seguito allintroduzione di una nuova machina, o di un nuovo prodotto) la procedura di generazione automatica del modello, a partire da un set di dati aggiornato o modificato. Questo può consentire lutilizzo del simulatore come strumento di analisi on-line, ad esempio per la verifica dellAvailable-To-Promise, o per la validazione di un programma di produzione generato, in modo statico, da uno schedualtore.
Considerando conclusa la validazione preliminare dellarchitettura, sono state indagate le modalità per disporre, in un contesto industriale ed operativo, dell'insieme dei dati di base per la generazione automatica dei modelli. Sono state analizzate le possibilità d'impiego, per gli scopi citati, dei datawarehouse e delle piattaforme dati utilizzate dai principali sistemi ERP, sempre più diffusi per la gestione aziendale integrata. Su questo punto di indagine, una estesa ricerca ha permesso di individuare molteplici possibilità di impiego di dati non strutturati o parzialmente strutturati, da ritenersi pronti all'uso per la simulazione dei sistemi produttivi, tramite sviluppo di specifici interpreti. Nello specifico, Con riferimento a SAP R/3, sono state identificate le strutture dove il dato richiesto risiede, e le procedure per arrivare al modello finale, che consistono nella strutturazione di 2 processori di primo livello (composer e builder), un interprete (traslator), ed il kernel di simulazione, che nella fattispecie possono essere implementati direttamente in ABAP/4.
Architettura per lintroduzione in SAP R/3 di un simulatore dinamico per analisi di scenario.
Unulteriore applicazione è stata portata a compimento per uno studio di riconfigurazione di un assembly-shop. In questambito è stato necessario analizzare la convenienza economica di molteplici soluzioni, comprendenti differenti tipologie di stazioni (a carosello od a tavola rotante), varie combinazioni delle attrezzature installate a bordo delle stazioni, differenti tipologie di layout e di dimensionamento della manodopera addetta al reparto (produzione e movimentazione). Per affrontare la complessità del problema (modellazione e gestione dei numerosi parametri di configurazione), è stata sviluppata una procedura di modeling automatico, basata sulla formalizzazione di meta-modelli. Tramite lo sviluppo di un apposito processore, il simulatore prescelto (ARENA) è capace di generare il modello/i modelli da utilizzare per lanalisi a partire da un datasheet parametrico, dove è stata preventivamente impostata la configurazione da testare.
Concludendo, lapproccio sviluppato può contribuire a favorire la diffusione della simulazione come metodologia di analisi a basso costo, rimovendo alla base gli ostacoli citati (eliminazione delle fasi di coding, di verifica e di validazione, generazione automatica di modelli mantenuti validi e credibili nel tempo con il minimo sforzo), e consentendo, in definitiva, larricchimento degli strumenti a disposizione dei responsabili e dei manager che si occupano di PP&C.
Relativamente alla possibilita di sperimentare detta tecnica
e formalizzare modelli di simulazione in modo automatico, lanali ha dimostrato
tuttavia che le informazioni richieste nei sistemi ERP installati risultano
frequentemente incomplete e non affidabili a questo scopo dal momento che
lo sfruttamento di detti sistemi transazionali spesso e legato piu alla
logica amministrativa che alla descrizione del processo; inoltre le strutture
interne alla maggior parte degli ERP esistenti risulta talvolta estremamente
rigida rispetto alle necessità di supportare lo sviluppo, tantomeno
automatico, di modelli di simulazione capaci di rappresentare i processi
reali. Dette considerazioni hanno portato a concludere che le modalita
di integrazione dei sistemi ERP attualmente in uso rende questa eventualità
ancora relativamente lontana, a meno di investire adeguatamente nella fase
di implementazione dellERP e nella analisi definizione dei processi aziendali.
Cooperazione Partecipanti
Il DIP ha coordinato il progetto di ricerca fra tutte le sedi come previsto e si e fatto carico anche di costruire una war room per la sperimentazione ed un team itinerante di integrazione; L'unità operativa di Genova ha infatti provveduto alla realizzazione di un laboratorio informatico presso il Polo Savonese qual base di lavoro per il progetto in essere, laboratorio che comprende in particolare 7 PC connessi in rete, ciascuno destinato ad un partner del progetto, per effettuare gli alfa test ed i test di integrazione; il laboratorio comprende, anche, una workstation e alcune stampanti nonché ausili per la videoproiezione e che e stato frequentemente utilizzato come sede dei meetings e test nel corso progetto di ricerca. La sua funzione principale è quella di consentire di riprodurre su scala ridotta e in rete locale la catena di subfornitura da studiare: le implementazioni dei modelli di ciascun sede possono essere installati e testati sia in modalità stand alone che in fase di integrazione garantendo la massima efficienza e lindispensabile riservatezza per eventuali dati specifici relativi ai partner industriali
La sede genovese ha inoltre curato lorganizzazione di corsi di simulazione ed HLA per diffondere queste conoscenze allinterno del consorzio.
Durante tutto il primo anno la sede Genovese ha operato a stretto contatto con i gruppi di ricerca di Firenze e Bari allo scopo di valutare, ampliare e completare alcune metodologie e strumenti (i.e. tools simulativi) per consentirne l'applicabilità ad una svariata tipologia di realtà industriali in vista della fase due del progetto.
Lattività di cooperazione ha coinvolto, specie per la scelta dei mezzi informatici e per la formazione dei componenti dellunità di ricerca, tutte le sedi impegnate nel progetto. Lunità di ricerca di Bari ha svolto inoltre funzioni di test in collaborazione con le sedi Genova e Firenze.
La cooperazione tra Napoli e Salerno ha consentito, in una prima fase, la sperimentazione del protocollo HLA in rete locale, utilizzando macchine tutte entro lo stesso dominio di rete. Questa soluzione è la più semplice per lesecuzione di una federazione HLA, infatti, quando viene lanciato in esecuzione la RTI con associato un file.fed che definisce le caratteristiche della federazione, HLA verifica automaticamente se nel dominio locale è già in esecuzione una federazione con le stesse caratteristiche. In tal caso non viene generata una nuova federazione ma si ha liscrizione dellutente a quella già esistente. Il passo successivo della sperimentazione è stato quindi lesecuzione della federazione tra due utenti non appartenenti alla stessa rete locale. Si è pertanto eseguita la federazione relativa alla supply chain precedentemente descritta in cui i modelli venivano lanciati in esecuzione ciascuno presso la propria sede universitaria.
Per permettere ai due modelli di integrarsi tramite HLA è stato necessario modificare alcuni parametri di configurazione della RTI, specificando, tra le altre cose, lindirizzo IP della macchina su cui viene creata la federazione. In questo modo le sedi di Salerno e Napoli hanno completato con successo le attività necessarie alla fase di sperimentazione del protocollo HLA.
La seconda e la terza fase di tale studio è stata svolta, principalmente per quanto riguarda la parte iniziale, in collaborazione tra le sedi universitarie di Napoli e Salerno, che hanno scelto, per lo sviluppo del proprio impianto simulato, lo stesso ambiente di simulazione (Arena). In particolare, la collaborazione si è concretizzata nello sviluppo della logica di funzionamento e della logica di gestione ed esplosione delle distinte basi relative ai prodotti da realizzare, sebbene in seguito tale logica è stata in parte personalizzata per meglio modellare le realtà aziendali rispettivamente studiate.
Vista la sostanziale correttezza di funzionamento dei modelli, i test sono continuati affrontando il problema connesso alla verifica della efficacia della generazione dei "file testo" necessari per linterfacciamento verso lesterno. Dopo vari tentativi e grazie allintegrazione delle competenze dei rispettivi gruppi di ricerca, il sistema ha prodotto i risultati attesi. Queste prime fasi sono state caratterizzate dallutilizzo del simulatore su computer stand alone, in quanto, prima di sperimentare le connessioni in rete, era necessario realizzare il corretto funzionamento del modello.
In seguito, in virtù dello sviluppo dellarchitettura SYNCRO (Università di Salerno), la fase di test è proseguita sperimentando in modo completo tutte le problematiche connesse allutilizzo delle porte di comunicazione socket.
Predisposti i modelli per il dialogo verso lesterno, si è proceduto ad una fase di test ed in seguito allintegrazione del modello in ambiente HLA, in collaborazione con le Università di Genova e di Napoli. I test successivi condotti con entrambi gli atenei, si sono svolti prima in rete locale ed in seguito, risolti tutti i problemi, in rete internet. Il successo di tali sperimentazioni ha evidenziato che la metodologia adottata per lo sviluppo del simulatore integrato in ambiente HLA nellambito del progetto, si è dimostrata fondamentalmente corretta.
La cooperazione intrapresa durante la ricerca tra luniversità
di LAquila ed il Politecnico di Milano ha riguardato lo studio, lapprofondimento
e limplementazione del protocollo comunicativo da applicare alla gestione
integrata di sistemi produttivi interagenti, identificata nello standard
fornito dal DMSO, HLA.
Nelle riunioni svoltisi nel polo costituito a Savona è stato possibile procedere ad un confronto diretto, mirante ad identificare le criticità di avvio dello studio dellarchitettura stessa, ed in seguito si è proceduto a trasferire mutuamente il know how tecnologico applicativo che ogni sede ha sviluppato.
In effetti la cooperazione tra le sedi di Milano e LAquila si è sviluppata essenzialmente nella fase di impostazione iniziale del progetto. Le due sedi hanno poi operato scelte diverse per quanto riguarda lambiente di simulazione e le modalità di integrazione con il protocollo di comunicazione HLA rendendo superflua una ulteriore cooperazione specifica.
Firenze ha collaborato con il gruppo di Milano nel processo di definizione delle specifiche e di codifica dellinterfaccia di tipo Proxy, ed ha utilizzato il Main Contractor fornito da Genova per verificare e validare i due modelli SIMPLE++ (Firenze e Milano) che partecipavano, grazie alla medesima interfaccia, ad una campagna sperimentale opportunamente predisposta su rete locale.
Questo ha consentito di rendere modulare, oltre che indipendente dalla reale configurazione del sistema produttivo, il frame che consente di interfacciare il simulatore SIMPLE++ con la federazione. Tale frame è poi servito, senza necessità alcuna di ulteriori personalizzazioni e/o modifiche, per la fase di sperimentazione finale, che ha visto allargare la federazione a tutte le sedi partecipanti, dimostrando di fatto la massima reusability del costrutto.
La sperimentazione del protocollo HLA è stata condotta
dalla sede di Napoli dapprima in rete locale, utilizzando macchine tutte
entro lo stesso dominio di rete. Il passo successivo della sperimentazione
è stato lesecuzione della federazione tra due utenti non appartenenti
alla stessa rete locale. Si è pertanto eseguita la federazione relativa
alla supply chain precedentemente descritta in cui uno dei due modelli
veniva mandato in esecuzione da un PC delluniversità di Napoli.
In questo modo le sedi di Salerno e Napoli hanno completato con successo
le attività necessarie alla fase di sperimentazione del protocollo
HLA.
Assegnazione Sub-forniture
DIP, Genova
Nella realizzazione di modelli avanzati per il supporto alla gestione della supply chain risulta critico il ricorso alle subforniture; sotto questo profilo lesperienza maturata nel caso Bombardier già citato prima dellavvio del progetto ha evidenziato che loutsourcing rappresenta la soluzione per far crescere rapidamente realta pre-esistenti mantenendo il controllo del processo industriale.
Detto controllo e tuttavia pesantemente collegato alla logica di assegnazione delle sub-forniture che con il loro crescere tendono ad assumere importanza strategica per il conseguimento degli obiettivi generali dei nuovi progetti e delle nuove commesse.
A questo proposito si evidenzia immediatamente che termini contrattuali e vincoli vari non sono sufficienti a supportare il controllo, ma diventa necessario un piu diretto coinvolgimento nella gestione dei sub-fornitori quanto meno in termini di metrica prestazionale, feed-back gestionali e supporti revisionali; limpiego di federazioni di simulatori/schedulatori on-line consente di fornire questo supporto e di quantificare le differenti soluzioni relative allassegnazione delle sub forniture.
Si propone quindi il ricorso agli strumenti ed alle metodologie
studiate in questo progetto come approccio funzionale alla progettazione
e assegnazione delle attività presso subfornitori.
Problemi Interfacciamento Simulatori ERP
DIP, Genova
I problemi di lintegrazione tra Simulatori ed ERP sono stati vissuti in molteplici casi industriali ed hanno evidenziato la necessità di prevedere la costruzioni di interfacce ad hoc al fine di ovviare pesanti interventi sia sul simulatore che sul sistema transazionale. Detta pratica gia sperimentata in diversi casi industriali ed in particolare riferimento agli sviluppi descritti dello strumento di simulazione OSIRIS risulta spesso lapproccio piu efficace per garantire linterfacciamento.
DIMEC, Salerno
In effetti fin dallinizio della progettazione del modello di simulazione è stato posto in primo piano il problema dellinterfacciamento dellambiente di simulazione con i moderni software gestionali ERP. Il problema, non di poco conto, è sorto dalla necessità e dallesigenza di trasferire molte informazioni, contenuti in tali archivi, soprattutto relative alla distinta base e ai cicli di lavoro nel modello, in modo sicuro e rapido.
Già in fase iniziale, infatti, si è pensato di realizzare il modello di simulazione completamente svincolato dalla base dati relativa ai prodotti ed ai cicli di lavoro, in modo da consentire un più rapido aggiornamento degli stessi. Tali informazioni, fondamentali per il funzionamento del simulatore, sono stati tutti inseriti in un database relazionale di tipo Access e di qui utilizzati direttamente al fine di consentire, anche ad un profano del software di simulazione, la modifica delle informazioni relative alla produzione senza minimamente dover accedere alla, pur molto semplice, shell di Arena.
Le interrogazioni e tutte le operazioni sui dati, contenuti in tale database, sono state realizzate adoperando il linguaggio SQL (linguaggio standard), che consentirà in futuro di riutilizzare lo stesso codice scritto allinterno delle istruzioni Visual Basic anche con altre basi dati memorizzate in formati diversi.
Il software ERP, scelto per testare lintegrazione, è il Syteline della Symix, un software gestionale di nuovissima generazione basato sullutilizzo del database Progress; tale sistema è in grado, una volta collegato al software di simulazione, attraverso i drivers ODBC, di fornire in automatico tutte le informazioni sui prodotti indispensabili allambiente di simulazione. Tale integrazione consente quindi, al modello di lavorare sempre con informazioni aggiornate e senza alcuna necessità di adattare manualmente i dati al formato richiesto dal simulatore.
La migrazione della base dati dal formato Access al formato Progress, già in fase di studio, porta inoltre un miglioramento delle prestazioni in termini di affidabilità grazie soprattutto alla robustezza del nuovo database.
La possibilità di creare un feedback tra il modello di simulazione ed il Syteline, per poter sfruttare le enormi potenzialità di schedulazione del pacchetto gestionale della Symix, invece, appare più complicata, sia dal punto di vista tecnico, sai da un punto di vista della logica di funzionamento del simulatore; infatti, il problema principale è legato alla variazione molto rapida del tempo simulato, rispetto ai tempi tipici di esecuzione di un pacchetto ERP, che non è stato progettato per eseguire le schedulazioni richieste, talvolta anche complesse, in pochissimi secondi.
Il test della metodologia da adottare per tale integrazione puo essere condotto attraverso lutilizzo di un piccolo software MRP (UnisaGest Software realizzato presso il DIMEC di Salerno) sviluppato appositamente in linguaggio Visual Basic. Il software in oggetto consente di verificare, in modo più approfondito, le problematiche relative sia al flusso logico dei dati, sia alle soluzioni tecniche da adottare. Infatti, linterfacciamento prevede lutilizzo di UnisaGest per il trasferimento del piano principale di produzione al simulatore e lo sviluppo di unapplicazione che consenta la conversione della distinta base e dei cicli di lavoro dalla forma strutturata, utilizzata dal MRP, alla forma "monolivello" ("flat"), necessaria per il funzionamento del modello Arena.
Lapplicazione per la conversione e realizzata in modo da risultare il più possibile indipendente dal tipo di database letto, in modo da poter essere utilizzata in futuro anche con il database Progress.
Si può così valutare la possibilità
di un ritorno delle informazioni dal simulatore verso il software MRP così
da poter confrontare la pianificazione posta in essere da questultimo
con lo scenario fattibile generato dalla simulazione.
Tipologie di Scheduling Innovative Distribuite
DIG, Milano
Negli ultimi decenni, i cambiamenti che hanno coinvolto la maggior parte dei mercati hanno portato ad uno stravolgimento del rapporto tra fornitore e cliente. Oggi più che mai, i clienti pretendono una più ampia gamma di prodotti, un maggiore livello di personalizzazione, elevati standard qualitativi, e condizioni di consegna più vantaggiose; sovente, gli imprenditori faticano a rispondere a queste richieste, rischiando di conseguenza la perdita della propria quota di mercato.
In questo periodo, da alcuni chiamato "Customer Orientation Era", lefficienza nel sistema produttivo è diventata una necessità, o, in altri termini, un Fattore di Competitività negativo: ovvero un sistema produttivo non efficiente non è in grado di mantenere la propria profittabilità nel lungo periodo.
Lefficienza dei sistemi produttivi è diventata pertanto un sempre maggiore oggetto di interesse per ricercatori accademici ed industriali. Molte, tra le più significative innovazioni realizzate in questi anni in ambito di progettazione e gestione dei sistemi produttivi, sono state il risultato di progetti di ricerca mirati allincremento dellefficienza.
Uno tra i più importanti frutti di tale filone di ricerca è sicuramente il Just in Time una filosofia che fa capo a tutto un insieme di tecniche per la progettazione e per la gestione dei sistemi produttivi, volte a massimizzare lefficienza produttiva per mezzo di una riduzione continua di qualsiasi tipo di sprechi.
La considerazione che, intervenendo nella fase di progettazione, si possa ottenere una maggiore flessibilità operativa del sistema produttivo così realizzato, ha portato al concepimento e alla realizzazione dei cosiddetti Flexible Manufacturing Systems (FMS). Gli FMS sono sistemi in grado di reagire in maniera più rapida e meno costosa, rispetto ai tradizionali sistemi produttivi, a cambiamenti esogeni quali, ad esempio, un forte aumento della domanda, variazioni significative nel mix produttivo richiesto, la domanda di nuove varianti di prodotto. Le tecniche di gestione della produzione, invece, si pongono gli obiettivi di utilizzo ottimale delle risorse e livellamento del flusso produttivo. Un flusso produttivo poco livellato, infatti, è sovente la causa principale di un elevato livello di WIP, nonché di confusione nello shop-floor. Daltra parte, ladozione di un insieme di tecniche che garantisca, da un punto di vista teorico, massima flessibilità, nonché il raggiungimento di livelli ottimali di utilizzo in condizioni ideali delle risorse produttive, non è sufficiente a garantire lottenimento di risultati soddisfacenti, perché le performance effettive di un sistema produttivo dipendono dal livello di incertezza che caratterizza lambiente produttivo (Cigolini et al. 1998).
Un sistema produttivo che soddisfi i requisiti di rapidità di risposta ed elevata robustezza operativa, a fronte di limitati costi di impianto e di gestione, può essere definito agile (Parunak, 1994).
Una risposta alla ricerca di modalità di realizzazione di sistemi produttivi che soddisfino i requisiti di agilità, è costituita dai Sistemi Multi Agente (MAS). Tali sistemi, infatti, offrono la possibilità di trovare il giusto compromesso tra flessibilità ed efficienza operativa, garantendo al tempo stesso una elevatissima robustezza.
Una recente survey (Baker, 1997) mostra quanto numerose siamo le applicazioni di Sistemi Multi Agente a problemi di Pianificazione e Controllo della Produzione (PP&C). Tali applicazioni sono accomunate dal fatto che condividono linsieme dei benefici tipici dei MAS, ma anche alcune limitazioni, che non sono ancora state risolte. In particolare, nessuna, tra le architetture Multi Agente presentate in letteratura, considera esplicitamente il problema delle dipendenze tra job, dovute, ad esempio, a vincoli di assemblaggio. Nella presente memoria, gli autori presentano una architettura di pianificazione di breve periodo basata su di un sistema multi-agente, per mezzo della quale sia possibile effettuare il dispatching delle macchine nel job shop e la schedulazione di una Linea di Assemblaggio Finale (FAL), prendendo esplicitamente in considerazione i legami tra item differenti, dovuti a vincoli di assemblaggio. Larchitettura proposta può essere definita come una Eterarchia Multilivello a Mercato di Libera Concorrenza, nella quale i prodotti finiti negoziano listante di assemblaggio con i sub-assembly che li costituiscono, i quali, a loro volta, si contendono le lavorazioni sulle macchine del job shop, per mezzo di unasta Second-Best a Busta Chiusa. Lofferta effettuata da un particolare sub-assembly in una battuta dasta dipende sia dal risultato delle negoziazioni allo stadio precedente, sia dallo stato di tutti quei sub-assembly che sono legati allofferente da vincoli di assemblaggio. La stessa struttura è replicata per i sub-assembly e i loro componenti primari, e così via, fino ad arrivare ai componenti di più basso livello. Le negoziazioni ai vari livelli non sono eseguite sequenzialmente, in quanto in tal modo si giungerebbe ad una soluzione sub-ottimale. Piuttosto, le decisioni contrattate ai vari livelli sono rimesse in discussione iterativamente, con una regola di congelamento che ricorda quella della Simulated Annealing (Kirkpatrick et al., 1983). Il paradigma del mercato di libera concorrenza, che costituisce il nocciolo concettuale dellarchitettura proposta, offre la possibilità di risolvere in modo naturale il trade-off tra ottimalità della soluzione trovata e flessibilità operativa; il meccanismo di asta second-best a busta chiusa permette innanzi tutto di realizzare una comunicazione asincrona tra i job e le risorse del job shop; tale meccanismo, inoltre, fa tendere il sistema ad una soluzione efficiente (Harker and Ungar, 1996).
Una definizione "debole" di Agente
In ambito informatico, levoluzione del concetto di Oggetto proprio del paradigma Object-Oriented (Rumbaugh et al., 1991) ha portato ad una diffusissima adozione del termine Agente. Il nuovo paradigma, che fa capo al termine Agente, potrebbe quindi essere definito Agent-Oriented. Termini quali Agente, Autonomia, e Intelligenza, sono oggetto di incessante dialettica da parte di ricercatori di ogni estrazione. La ricerca di definizioni che possano essere universalmente accettate ha coinvolto illustri informatici, ingegneri, economisti, biologi e, addirittura, filosofi. I risultati fino ad ora ottenuti si possono dire piuttosto deludenti; ciò è indice di una non ancora raggiunta maturità scientifica in ambiti quali lIntelligenza Artificiale. Nella presente memoria, il termine Agente sarà utilizzato per indicare un programma che abbia le seguenti caratteristiche:
contenga al suo interno tutto il codice necessario per il proprio funzionamento (non si avvalga, cioè, di codice condiviso con altri agenti);
abbia un obiettivo locale, e non condivida con altri agenti alcun obiettivo globale;
sia in grado di comunicare con altri agenti per mezzo di un Agent Communication Language (Genesereth and Ketchpel, 1994).
Tale definizione di agente è sicuramente "debole"; è tuttavia sufficiente per la comprensione del modello che verrà qui di seguito presentato. Per una definizione "forte" di agente, si rimanda allautorevole lavoro di Wooldridge e Jennings (1995).
Panoramica dei lavori in letteratura
Il primo esempio di applicazione del paradigma Agent-Oriented ad un sistema di PP&C è, con ogni probabilità, la tesi di dottorato di Shaw (1984). A tre lustri di distanza, sarebbe necessario un lavoro enciclopedico per poter passare in rassegna tutti i lavori pubblicati sullargomento. I nomi dati alle architetture proposte sono i più disparati: tra gli altri, vi sono i Sistemi di Controllo Distribuiti Cooperativi (Shaw, 1984), le Eterarchie (Dilts et al., 1991), i Sistemi Frattali (Parunak et al., 1985), le cosiddette Olarchie (Valckenaers et al., 1997). E interessante rilevare come i termini adottati per identificare tali innovativi sistemi di PP&C siano per lo più permutati da altre discipline: il concetto di cooperazione era già stato adottato nel campo dellelaborazione distribuita delle informazioni (Enslow, 1976); lidea di eterarchia viene dalla neuro-fisiologia (McCulloch, 1949); i frattali costituiscono il concetto principe della Geometria Frattale di Mandelbrot (1982); la parola olone venne proposta, verso la fine degli anni 60, in un tentativo di modellizzazione delle organizzazioni sociali (Koestler, 1989). Indipendentemente dal nome di battesimo, le architetture di PP&C basate sul paradigma Agent-Oriented sono dei sistemi distribuiti, costituiti da una moltitudine di agenti in grado di operare in assenza di controllo globale e di sorgenti di informazioni tra loro coerenti. In questo lavoro, tali architetture verranno indistintamente chiamate con il termine generico Sistemi Multi-Agente (MAS). I MAS si dimostrano particolarmente adatti alla risoluzione di problemi distribuiti, e garantiscono il soddisfacimento di requisiti quali elevata modularità, mantenibilità, e semplicità di funzionamento. Un altro vantaggio significativo dei MAS consiste nella loro robustezza: in generale, meno un MAS dipende da informazioni condivise e controllo globale, meglio è in grado di reagire a cambiamenti inattesi (Smith, 1980). In un recente lavoro, Baker (1997) presenta unampia ed accurata survey di algoritmi di PP&C che possono essere implementati in una eterarchia multi-agente. Una lettura di tale lavoro conferma come il contesto industriale sia un ambito promettente per ulteriori applicazioni di MAS. Nel primo esempio di utilizzo di un MAS per svolgere le funzioni di pianificazione e controllo della produzione a livello shop-floor (Shaw, 1984), gli Agenti rappresentano le celle, ed hanno la possibilità di sub-appaltare ad altre celle lavori già assegnati alla propria cella. Lin (Lin, 1992; Lin e Solberg, 1992) ha proposto una estensione allarchitettura di Shaw, introducendo gli Agenti Parte, ovvero agenti che rappresentano i vari job, e che possono contrattare, per mezzo di una unità di conto fittizia, con i vari Agenti Risorsa . A differenza della architettura di Shaw, nella architettura di Lin gli Agenti Risorsa possono rappresentare macchine, mezzi di trasporto, servizi di impianto, o anche semplici utensili condivisi da più macchine. Recentemente, sono stati introdotti altri tipi di agente, quali lAgente Facilitatore (o Mediatore), che ha il compito di supportare le contrattazioni, e ridurre di conseguenza il rischio di sovraccarico del canale di trasmissione delle informazioni (Rabelo e Camarinha-Matos, 1994; Maturana e Norrie, 1995). Questa evoluzione mostra come, per oltre un decennio, molti ricercatori si siano dedicati alla progettazione di nuovi Sistemi Multi-Agente, che fossero in grado di offrire buone performance anche a fronte di ambienti produttivi incerti e turbolenti.
Sviluppo di una metodologia di modellizzazione di sistemi produttivi distribuiti- analisi modelli statistici, dinamici e funzionali in relazione a package software esistenti
Il paragrafo seguente fornisce l'analisi e la valutazione critica di un campione di metodi formali di modellazione, allo scopo di valutare quali di essi siano dotati delle capacità rappresentative ritenute necessarie per la modellazione di sistemi produttivi distribuiti. Produce quindi una proposta di metodo specifico a supporto della modellazione di un sistema produttivo distribuito nell'ottica prevista dal progetto. Il campione di analisi di metodi formali è selezionato nell'area di manufacturing systems modeling. E' peraltro da notare che i metodi formali di modellazione sono stati originariamente sviluppati per applicazioni di software engineering; in anni più recenti, sono inoltre stati proposti metodi formali in diverse aree disciplinari di enterprise engineering (metodi di business process modelling e di information systems modeling). E' possibile quindi riferirsi ad altri metodi formali, non specificatamente sviluppati per il dominio manifatturiero: nel corso del documento, si farà riferimento a metodi di progettazioni object-oriented, che, per le caratteristiche di trasversalità e generalità dei costrutti di modellazione, possono essere utilizzati proficuamente anche per la modellazione di sistemi produttivi distribuiti. La precedente considerazione è rafforzata ricordando che l'adozione del paradigma di modellazione object-oriented permette la corrispondenza tra entità componenti del sistema da rappresentare con proprietà e comportamenti propri e relativi oggetti di modellazione logica con attributi e metodi specifici, come emerso in più lavori di letteratura. L'analisi, quindi, concentra l'attenzione sulle capacità rappresentative dei metodi in termini dei fattori qui di seguito elencati:
Non si ritiene, invece, allo stato attuale del progetto, essenziale la descrizione dell'aspetto organizzativo di ciascun nodo, ovvero la descrizione delle sue risorse umane, delle relative capabilities e responsabilità sui compiti produttivi. La proposta di una metodologia per sistemi produttivi distribuiti si basa sulla analisi condotta; in effetti questa suggerisce i diagrammi di modellazione che si ritiene debbano essere parte integrante della metodologia al fine di rispondere alle esigenze descrittive del sistema; la proposta viene quindi applicata al caso di sviluppo di un modello di sistema produttivo distribuito nel caso di modellazione federata HLA; infine, si citano alcuni strumenti software a supporto della metodologia proposta, con brevi considerazioni critiche sulle relative potenzialità.
Analisi e valutazione di metodi formali esistenti
Il campione di metodi di manufacturing systems modeling
prescelto
è indicato in tabella. L'analisi condotta presuppone la conoscenza
dei metodi e dei relativi costrutti di modellazione. Si rimanda alle bibliografie
indicate per chiarimenti.
| Nome metodo | Riferimento bibliografico | Nome metodo | Riferimento bibliografico |
| IDEF0 | Menzel et al 1998 | CIMOSA | Vernadat 1999 |
| IDEF1x | Menzel et al 1998 | HOOMA | Wu 1995 |
| IDEF3 | Menzel et al 1998 | JR-net | Park et al. 1997 |
| GIM | Doumeingts et. al 1999 | MES | Bartolotta et al.1999 |
Campione di analisi di metodi formali in area di manufacturing systems modeling
La suite IDEF propone metodi complementari (i.e., IDEF0, IDEF1x e IDEF3) per supportare la descrizione dei diversi aspetti di un sistema produttivo. Allinterno della suite IDEF, IDEF0 è specializzato nella descrizione statica delle funzionalità del sistema, rappresentando in un unico diagramma le funzioni di trasformazione di materiali/informazioni e i flussi di materiali/dati/controllo tra di esse. LIDEF1x è un metodo orientato alle entità, permette cioè una buona descrizione delle proprietà di informazioni e di materiali. LIDEF3 supporta la descrizione delle funzioni di trasformazione dei materiali/dati e controlli, sia dal punto di vista statico che da quello dinamico. Non è caratteristica peculiare della suite IDEF invece la capacità di descrivere l'aspetto fisico-strutturale di sistema produttivo: la descrizione statica delle risorse è comunque possibile attraverso la descrizione di entità in IDEF1x; è possibile dare una descrizione della dinamica delle risorse in IDEF3, anche se in maniera indiretta attraverso la descrizione delle funzioni svolte; è anche possibile associare i flussi di materiali con le risorse produttive, essendo le risorse i meccanismi necessari per lo svolgimento delle funzioni IDEF0.
GIM permette la descrizione statica delle funzioni di trasformazione dei materiali e dei relativi flussi di materiali in quanto utilizza il metodo IDEF0 per modellare il sottosistema fisico. Per mezzo della GRAI net, GIM fornisce la descrizione statica delle funzioni di trasformazione delle informazioni e dei flussi di controllo a carico di un definito centro decisionale DC; la GRAI grid, invece, descrive i flussi informativi e di controllo scambiati tra i diversi DC del sottosistema decisionale. La descrizione statica dei materiali trasformati, anche se non esplicitamente fornita dal metodo, è possibile grazie allutilizzo del metodo E/R (simile a IDEF1x). Il metodo E/R è impiegato, per sua natura, per la descrizione statica dei dati di archivio del sottosistema informativo. GIM non consente la descrizione dinamica delle funzioni di trasformazione dei materiali e delle informazioni. Mostra inoltre lacune evidenti per la descrizione dell'aspetto fisico-strutturale di sistema, essendo supportato, a tal fine, dal solo metodo IDEF0.
CIMOSA consente la descrizione statica delle funzioni di trasformazione di materiali/informazioni/controllo attraverso i propri costrutti della function view (i.e., domain, domain process, business process, enterprise activity e functional operation). Attraverso gli enterprise object è possibile descrivere attributi di materiali e informazioni; attraverso lobject view (in ingresso e in uscita alle enterprise activity) si possono rappresentare i flussi tra le funzioni. CIMOSA non permette però alcuna descrizione dinamica delle funzioni di trasformazione. Per quanto riguarda l'aspetto fisico-strutturale, CIMOSA consente la descrizione statica delle risorse attraverso i costrutti resource e capability set della resource view. Inoltre, identificando i flussi tra le enterprise activity nella function view, ed essendo le enterprise activity svolte da risorse ad esse collegate come meccanismi in input, CIMOSA è indirettamente in grado di modellare l'associazione flusso di materiali e risorse produttive.
MES è specificatamente dedicato per il design di sistemi produttivi manifatturieri. Definisce infatti una libreria di classi necessarie per la rappresentazione del sistema produttivo. In particolare, definisce le operation class, attraverso cui è possibile la descrizione statica delle funzioni di trasformazione dei materiali, la part class, che permette la descrizione statica dei materiali/prodotti in termini di distinta base, i flussi di materiali in input e in output dalle operazioni, rappresentati a mezzo dell'associazione tra le classi part e operation. Il metodo MES non permette tuttavia la descrizione dinamica delle funzioni di trasformazione dei materiali. MES inoltre descrive l'aspetto strutturale di un sistema produttivo, permettendo la descrizione statica delle risorse attraverso listanziazione delle component class (specializzata in sottoclassi specifiche: processor, transporter, storage). Associa inoltre la component class ai flussi di materiali mediante la relazione con la classe operation. Non consente la rappresentazione della dinamica di funzionamento delle risorse.
JR-net è molto simile a MES, per cui si rimanda al riferimento bibliografico relativo.
HOOMA è un metodo di modellazione object-oriented in grado di supportare la descrizione statica delle funzioni attraverso il functional block diagram. Non è in grado invece di rappresentare la dinamica di tali funzioni. Nel sub-system relationship diagram è possibile rappresentare, quindi, i flussi di dati. La descrizione dei dati di archivio è invece permessa dellobject model previsto in HOOMA. Infine, HOOMA prevede due tipi di diagramma per la descrizione dinamica delle risorse: lactivity cicle diagram ACD e lo state transition diagram STD. Con l'ACD sono descrivibili le attività subite dalle entità temporanee del sistema (i materiali da trasformare) e le attività svolte dalle entità permanenti (le risorse di produzione del sito). Con l'STD è possibile descrivere il funzionamento interno di un'entità. La descrizione della dinamica permette infine di rappresentare i flussi di controllo tra le entità del sistema per governare l'esecuzione delle attività.
Proposta di una metodologia per sistemi produttivi distribuiti
La proposta di una metodologia per sistemi produttivi distribuiti si basa sulla analisi condotta dal gruppo di Milano
In essa emergeva, innanzitutto, la disponibilità di diversi metodi formali, ciascuno con le proprie capacità rappresentative, i propri pregi e difetti nella copertura dei diversi aspetti ritenuti fondamentali per descrivere una supply chain di prodotti manifatturieri. Emergeva inoltre una chiara focalizzazione dei metodi su una descrizione "statica" degli aspetti da descrivere di un sistema: pochi metodi (cfr. per esempio IDEF3, HOOMA con STD e ACD) supportano infatti una modellazione dinamica del sistema, in genere la descrizione è condotta con una "vista" di modellazione statica delle funzioni, dei flussi, delle risorse.
La proposta non è peraltro di adottare necessariamente uno dei metodi indicati. E' possibile infatti proporre lo sviluppo di un metodo formale specificatamente disegnato per la descrizione di sistemi produttivi distribuiti.
Per la proposta di un nuovo metodo, si ritiene:
Applicazione della metodologia a una federazione HLA di sistemi produttivi
Nel presente paragrafo si provvede ad applicare la proposta di metodologia allo sviluppo del modello di un sistema produttivo distribuito, quando l'ambito di modellazione è vincolato dall'adozione di HLA, l'architettura standard prescelta nell'ambito del progetto per implementare una simulazione federata di supply chain manifatturiera. L'applicazione qui presentata è da intendersi come una pre-analisi di fattibilità di metodo, non vengono presentati casi applicativi di sviluppo specifici. Innanzitutto, è da notare che il metodo di sviluppo della federazione HLA prevede essenzialmente un object model che specifichi i dati condivisi e scambiati in federazione (i.e., modello FOM). Si ritiene necessario, però, al fine di uno sviluppo completo del modello di federazione, integrare il modello statico FOM con:
una analisi degli scenari di interazione tra i nodi produttivi del sistema, ovvero dei processi attraverso i quali vengono scambiati i dati di federazione tra i federati;
con un STD utile per definire le transizioni di stato del modello di simulazione federato e i relativi eventi/messaggi scambiati con la federazione (nei diversi scenari di interazione di cui al punto 1.); a tal fine, si suppone che il STD sia sviluppato ad un livello "alto", senza dettagliare il funzionamento con STD annidati: infatti, si ritiene di interesse definire il funzionamento del nodo solo in relazione agli eventi/messaggi principali scambiati con la federazione.
Si ritiene che lo sviluppo del modello del singolo federato sia invece indipendente dallo sviluppo del modello di federazione, una volta rispettati i vincoli di specifica dovuti alla partecipazione alla federazione (i.e., FOM, scenari, STD). Con metodi formali specifici, e non necessariamente da definire nel presente documento, è possibile quindi sviluppare il modello del federato.
Possibili strumenti software di supporto alla modellazione
Si citano a titolo di riferimento alcuni strumenti software in grado di offrire la capacità di editing dei diagrammi di modellazione suggeriti come parte componente del metodo proposto.
Gli esempi sono da considerare paradigmatici al fine di giungere ad alcune conclusioni sui tool di modellazione disponibili.
Rational Rose (cfr. http//:www.rational.com) è uno tra gli strumenti commerciali più diffusi in area software engineering; supporta metodi di progettazione object-oriented come UML e OMT; supporta perciò diagrammi di classi, STD e diagrammi per descrivere scenari di interazione.
I pacchetti di implementazione dello standard HLA supportano, oltre alla esecuzione di simulazioni federate, la costruzione di object model secondo un format descrittivo standard (Object Model Template). Il tool specifico è Object Model Development Tool (OMDT) e supporta la generazione di modelli FOM (e altri object model, come SOM e MOM).
Il primo è un esempio di tool progettato per specifiche applicazioni, diverse da quella in esame nel documento; può essere ritenuto uno strumento sovradimensionato, dato che offre la possibilità di descrivere diversi diagrammi di modellazione, non tutti strettamente necessari.
Il secondo esempio di tool fornisce un metodo di
modellazione standard HLA; è da integrare con metodi di descrizione
della "vista" dinamica - e quindi con il supporto di altri tool come
Rational Rose -, se ritenuto necessario, come emerge dal presente rapporto.
Sistemi Organizzativi per Quick Response e Multi-Gestione
La distribuzione spaziale dei processi logistico-produttivi, e il fatto che questi siano caratterizzati da una incompleta integrazione verticale, ha come conseguenza il fatto che le informazioni (e i beni) che passano da un anello allaltro siano processati in maniera fortemente sequenziale: lorganizzazione a valle riceve linformazione solo al termine dellattività di quella a monte. Questo effetto è oltremodo accentuato quando tale flusso attraversa i confini di una società per legare più partner, i cui obiettivi sono spesso discordanti, e le politiche non allineate. Tale approccio sequenziale ha come conseguenza inevitabile la presenza di extra-costi, ovvero di costi che non generano alcun valore, non essendo direttamente percepibili dal consumatore finale; un classico esempio di extra-costo è quello legato al mantenimento di elevati livelli di scorta, al fine di garantire un livello di servizio eccellente, anche a fronte di ritardi ed errori nelle comunicazioni con i fornitori. Lintegrazione tra i soggetti operanti allinterno della stessa supply chain può portare a benefici significativi in termini di vantaggio competitivo a livello dellintera filiera; in particolare, la condivisione di informazioni su livelli di scorte, dati di previsione e trend di vendita, e il coordinamento dei processi di pianificazione può garantire una crescita del valore percepito dal cliente, come conseguenza di un più elevato livello di servizio, e una riduzione delle inefficienze dovute agli elevati tempi di attraversamento, e agli errori dovuti a possibili incoerenze nei piani e nei programmi di produzione e di trasporto dei vari partner.
È stata preoccupazione del team del Politecnico di Milano di verificare se e come un sistema di coordinamento distribuito possa migliorare le prestazioni del processo di pianificazione dei fabbisogni a livello di filiera.
Sistemi Multi-Agente e Gestione della Filiera Logistica
Dallanalisi delle caratteristiche peculiari della filiera logistica tra le quali vanno sicuramente ricordate la distribuzione fisica e logica delle unità produttive e decisionali, e la variabilità nel tempo della struttura della filiera, sia in termini di soggetti che interagiscono gli uni con gli altri, che di intensità di tali interrelazioni si capisce come una metodologia di risoluzione dei problemi distribuita si possa ben adattare a questo contesto. In particolare, cinque sono i fattori che fanno dei sistemi Multi-Agente una metodologia appropriata per risolvere il problema della gestione integrata di una Supply Chain (Green et al., 1997):
Tipologie di Scheduling Innovative con Sistemi Esperti Neuro-Fuzzy
DE, LAquila
La sede dellAquila ha curato come obiettivo primario del programma di ricerca lo sviluppo di un "sistema esperto" capace di ottimizzare le prestazioni di differenti classi di schedulatori-simulatori al variare, nel breve-medio periodo, dello scenario produttivo in cui si trovano ad operare. Al sistema esperto è affidato il compito di scegliere, sulla base di una descrizione fuzzy dello scenario produttivo e della funzione obiettivo, le regole euristiche o i parametri delle regole da impiegare per ciascun modello di coda assegnato alle diverse tipologie di risorse. Utilizzando uno schedulatore basato su regole di carico parametriche, come quello descritto precedentemente, si ottengono infatti schedulazioni caratterizzate da differenti performance variando il valore dei parametri. E possibile quindi selezionare opportunamente i valori dei parametri in funzione della particolare situazione che si sta affrontando per ottimizzare le prestazioni dello schedulatore.
Nellambito del programma di ricerca è stata messa a punto una procedura basata da un lato sullutilizzo di algoritmi genetici (GA) per ottimizzare, in una serie di scenari di riferimento rappresentativi, il valore dei parametri impiegati dallo schedulatore, e dallaltro sullimpiego di reti neurali per correlare sul campo ed autonomamente, sulla base delle migliori corrispondenze tra parametri e scenari di riferimento determinate in sede di ottimizzazione preliminare del sistema, i più opportuni valori dei parametri dello schedulatore al dato scenario di produzione analizzato.
A tal fine è risultato quindi necessario costruire una banca dati che associasse ad ogni scenario i valori dei parametri che forniscono i migliori risultati, ed utilizzare questi ultimi per addestrare la rete neurale. Per la realizzazione di questa banca dati è stato sviluppato un programma basato sugli algoritmi genetici: il concetto è di selezionare, per ogni scenario, un insieme di parametri tra molti possibili valutandoli mediante una funzione di fitness, quali ad esempio la massimizzazione della saturazione del sistema. Scegliendo opportunamente questa funzione, e determinando i parametri che la massimizzano, è possibile individuare una soluzione subottimale al problema di scheduling valido per lo specifico scenario considerato. Ripetendo questa attività per diversi scenari rappresentativi è possibile ottenere un data base di riferimento che associ ad ogni tipologia di scenario produttivo le impostazioni più idonee dello schedulatore ed addestrare mediante tali dati una rete neurale che in tempo reale determini gli effettivi parametri di impostazione dello schedulatore richiesti dalla specifica situazione contingente sulla base dellesperienza precedentemente accumulata, agendo sostanzialmente da classificatore.
Realizzazione del processo di ottimizzazione mediante algoritmi genetici.
E' stata realizzata una implementazione dell'algoritmo genetico indipendente dal particolare problema affrontato e basata sulle tecniche del calcolo parallelo per contenere i tempi di calcolo totali. Più in dettaglio, il programma è parallelo e distribuito, sfruttando larchitettura master-slave, ed è in grado di utilizzare fino a 128 macchine per il calcolo delle funzioni di fitness. Il calcolo della funzione di fitness nel caso affrontato è infatti molto dispendiosa in termini di tempo e di risorse di calcolo (implicando sempre l'esecuzione dello schedulatore) per cui l'implementazione, realizzata in C++, è stata particolarmente curata soprattutto per quanto riguarda la velocità, la robustezza, la portabilità. La funzione di fitness adottata è inversamente proporzionale al numero di jobs in ritardo mentre lo schedulatore utilizza regole di carico basate su un numero di variabile di parametri pari ad un massimo di 12. Data la natura distribuita del calcolo è stata curata in particolar modo la robustezza dell'implementazione dello scambio dei dati la quale avviene su macchine parallele in logica master-slave utilizzando un protocollo TCP/IP.
Lottimizzazione delle regole dello schedulatore viene dunque eseguita "una tantum" in parallelo su reti di calcolatori (tempo necessario circa 12-24 ore) generando popolazioni di schedulatori su cui evolvono le n-ple di parametri. Come ordine di grandezza del problema considerato si è presa in esame la schedulazione di circa 4600 jobs. Il SW permette ovviamente di mantenere ed elaborare statistiche sullevoluzione della fitness nonché di fissare a piacimento i parametri operativi (numero di generazioni, numero di slave, individui della popolazione ecc.).
Più in dettaglio la procedura operativa di ottimizzazione è la seguente:
Realizzazione del processo di selezione automatica dei parametri di schedulazione mediante rete neurale
Sulla base dei risultati ottenuti, è stato svolto lo studio dell'architettura della rete neurale da utilizzare giungendo alla scelta di una topologia feedforward, per quanto riguarda l'organizzazione dei neuroni, e dell'algoritmo di backpropagation, per quanto riguarda l'apprendimento. La procedura applicativa prevede che una volta addestrata la rete neurale con le n-ple di parametri ottimali relative a ciascuno scenario di riferimento il sistema possa essere messo on-line. Fornendo quindi i dati caratterizzanti lo specifico scenario la rete neurale determina i parametri dello schedulatore da utilizzare a partire dai valori dei parametri risultati ottimali per gli scenari di riferimento.
Al fine di generare i dati necessari al confronto delle prestazioni ottenibili con lutilizzo di differenti valori dei parametri e per laddestramento della rete neurale è stato preliminarmente sviluppato, in ambiente SW Arena, un modello di simulazione di una generica realtà aziendale rappresentativa il quale è stato poi utilizzato per generare il lancio di ordini di tale ipotetica azienda.Variando alcuni parametri di ingresso al modello è stato possibile creare set di job appartenenti a diversi scenari di riferimento.
Le simulazioni sono state condotte nellarco di due mesi sfruttando le potenzialità di lavoro distribuito dellalgoritmo genetico e coinvolgendo anche decine di calcolatori. Lalgoritmo genetico è stato utilizzato cercando di ottimizzare il tardiness medio delle schedulazioni prodotte.
La grande mole di dati è stata analizzata utilizzando diversi metodi grafici al fine di estrapolare le informazioni necessarie alla valutazione del comportamento dellalgoritmo genetico e verificarne la bontà.
Successivamente è stato elaborato un software (mediante lo sviluppo di una libreria di classi ANSI C++ fortemente integrata e ottimizzata) che permette laddestramento e la validazione automatica di una rete neurale feedforward di qualsiasi grado in modo distribuito.
In particolare si è scelto di utilizzare una architettura di rete MASTER-SLAVE dinamico. Gli algoritmi di addestramento implementati sono il BACK-PROPAGATION (Batch Update) e il LEVENBERG-MARQUARDT.
FASE I Elaborazione del Training Set e del Validation Set
La creazione di una banca dati per laddestramento e la validazione di una rete neurale è stato il primo passo seguito. Tramite il modello Arena è stato creato un certo numero di set di job. Ogni set è quindi stato elaborato dallalgoritmo genetico fornendo in uscita dei parametri che ottimizzano il TARDINESS medio della schedulazione prodotta dallo schedulatore di prova . In parallelo un altro modulo ha provveduto a estrarre da ogni set di job diversi indici statistici (quali ad esempio la media e la varianza delle quantità e delle date di consegna). La matrice finale è stata così composta dai parametri ottimi di schedulazione (colonne TARGET) e dagli indici statistici (colonne INPUT) e da tante righe quanti i set di job di partenza.
Anche se in un primo momento si è utilizzato un modello Arena nulla vieta come si è fatto in seguito di attingere a dati reali di azienda per riempire il database dei set di job.
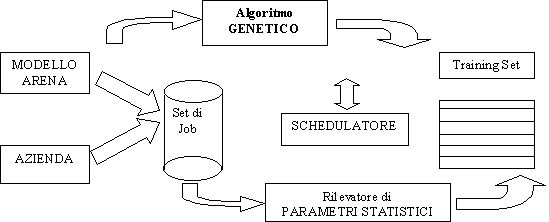
FASE II Addestramento e validazione della rete neurale
Laddestramento della rete neurale è stato portato
avanti tramite il software realizzato in C++. Sono state studiate diverse
strutture di reti neurali variando di volta in volta il numero di neuroni
e di layer. Lobbiettivo fondamentale è stato quello di garantire
oltre che un piccolo errore sul training set anche un buon grado di generalizzazione
valutato su dati sconosciuti alla rete stessa.
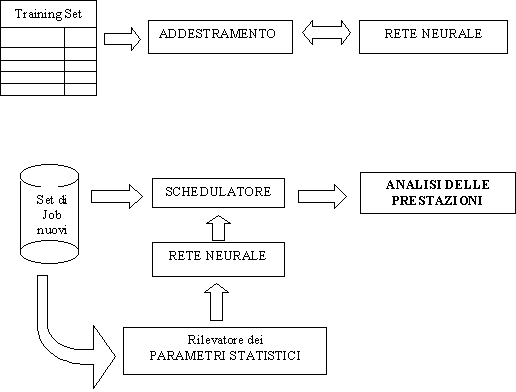
A completamento della fase di sviluppo sono state eseguite due diverse tipologie di prove:
PROVA Tipo 1: ADDESTRAMENTO DI UNA RETE NEURALE CON UN SET DI DATI DI PICCOLE DIMENSIONI
La rete è stata addestrata su 86 set di job relativi a 5 scenari differenti ma con caratteristiche abbastanza simili ed è stata testata su 21 set di job sconosciuti ma facenti parte di uno scenario scelto tra i suddetti cinque. La prova ha portato a risultati facilmente interpretabili e che dimostrano comunque il buon funzionamento della rete neurale su set di job con caratteristiche statistiche particolari. Tali risultati sono poi stati messi a confronto con quelli ottenuti impostando manualmente i parametri su valori attendibili.
PROVA Tipo 2: ADDESTRAMENTO DI UNALTRA RETE NEURALE PIU CAPACE CON SET DI DATI DI GRANDI DIMENSIONI E ANALISI DELLE PRESTAZIONI
La seconda rete neurale creata è stata utilizzata
per individuare i parametri ottimi da utilizzare con lo schedulatore di
prova per 100 set di job completamente sconosciuti. Laddestramento è
stato fatto su una banca dati costituita da 370 set di job. I risultati,
confrontati anche con una soluzione empirica, hanno evidenziato il buono
e in alcuni casi ottimo comportamento in media della rete neurale per quei
casi cosiddetti difficili. La rete neurale è riuscita cioè
a discriminare tra le normali oscillazioni delle condizioni operative (sui
cui ha fornito risultati paragonabili alla soluzione empirica) e le variazioni
di ampiezza maggiore (dove ha mostrato performance migliori).
Vincoli Infrastrutturali
DIP, Genova
I potenziali utilizzatori di queste metodologie comprendono estesamente piccole e medie imprese; a questo riguardo si e deciso di ipotizzare che le infrastrutture hardware e software di riferimento da utilizzare come base di sviluppo fossero compatibili con questa tipologia di utenti.
Le ipotesi sono in effetti risultate confermate durante la fase di sperimentazione ove si sono integrati nella federazione di simulatori riproducenti la catena logistica anche aziende caratterizzate da sistemi informativi molto semplici. Le indicazioni hanno quindi correttamente portato a considerare come riferimento PC in ambiente Windows e reti di comunicazione internet/intranet.
INTEGRAZIONE E DISTRIBUZIONE DEI MODELLI
Protocolli Collegamento per Simulatori
DIP, Genova
Lo sviluppo di standard per il collegamento di simulatori distribuiti ha subito una rapida evoluzione a partire dalla fine degli anni novanta dove da supporto per ovviare a problemi di capacità computazionale e diventato un requirement per lintegrazione di strumenti operanti in modo geografico sulla rete.
Oggi nel settore militare esiste una chiara direzione circa ladozione dello standard HLA; progetti analoghi riguardano sia sperimentazione da parti di centri di ricerca industriali pubblici e privati (i.e. National Institute of Standards & Technology); sulla base di queste considerazioni, e confermando le analisi preliminari condotte prima dell progetto, si e pertanto deciso di condurre una serie di sperimentazioni per valutare la convenienza di additare come riferimento questa soluzione,.
A questo proposito e importante ricordare che lo standard HLA si divide in tre parti; esso risulta infatti composto da regole, OMT e specifiche dinterfaccia.
Declaration Management: forniscono i mezzi alle simulazioni per stabilire le loro intenzioni in merito alla pubblicazione di interazioni ed attributi di oggetti; ed alla condivisione degli aggiornamenti e delle interazioni prodotte da altre simulazioni.
Object Management: permettono alle simulazioni di creare e cancellare istanze di oggetti e di produrre e ricevere interazione ed aggiornamenti individuali di attributi ed.
Ownership Management: abilitano il trasferimento del possesso distanze di oggetti (ed il permesso di modificare tali valori) durante lesecuzione di una federazione.
Time Management: coordinano lavanzamento del tempo logico in rapporto al tempo di wallclock (tempo reale) durante lesecuzione di una federazione.
Date Distribution Management: permettono a grandi federazioni di migliorare lefficienza del meccanismo di distribuzione dei dati riducendo lammontare dei dati trasmessi tra federati.
Larchitettura inoltre supporta la costruzione di simulazioni distribuite su più computers, caratteristica questa assolutamente non obbligatoria.
La sede Genovese ha avuto esperienze con questa tecnologia
a partire dal 1996 ed ha operato come riferimento per il consorzio relativamente
a questa tecnologia proponendola come soluzione di integrazione, trasferendo
competenze con seminari e corsi e fornendo un supporto operativo in loco
ai diversi partners di questo progetto.
DIG, Milano
Nellambito di questa fase, lunità di ricerca di Milano ha provveduto a studi preliminari sulla metodologia ed sulla infrastruttura fornita da HLA.
Lanalisi effettuata ha permesso di identificare nellHLA il protocollo ottimale da impiegare nella stesura di una supply chain elettronica distribuita, grazie alle enormi potenzialità di implementazione presenti nello strumento fornito dal ministero della difesa statunitense.
Lo studio si è sviluppato lungo le direttrici della diretta sperimentazione, favorita da casi industriali fittizi, redatti ad hoc in maniera tale da poter essere riutilizzati come moduli di base per applicazioni maggiormente evolute.
Alcuni studi alternativi sono stati preliminarmente discussi con le altre sedi universitarie, come limpiego di librerie VB, ma sono state immediatamente accantonate, data lindiscussa superiorità dello strumento già presente (HLA ed RTI), corredato da numerosa bibliografia.
Lo sviluppo e limpiego del protocollo scelto è stato condotto in stretta collaborazione con le sedi universitarie coinvolte nel progetto, in particolar modo con la sede di Firenze. Accomunati infatti dalla scelta di impiegare il medesimo strumento di simulazione (Simple++) si è potuto procedere ad uno studio parallelo sia del protocollo HLA che del programma di simulazione stesso.
Linterfacciabilità dei due ambienti informativi (RTI per HLA e Simple++) è stata ottenuta attraverso limplementazione di librerie ad hoc, in prima fase scritte in C++ ed in seguito convertite nel più duttile ambiente Java.
Linfrastruttura è stata più volte testata in estensione wan, tramite la rete internet unificante i due atenei.
DEF, Firenze
In effetti da alcuni anni, le applicazioni di simulazione distribuita basate su HLA come protocollo di comunicazione sono cresciute di numerosità, dimostrando le possibilità di utilizzo dellinfrastruttura RTI-HLA anche in ambito logistico ed, in ogni caso, esternamente al contesto delle applicazioni di natura militare. Simulatori per lanalisi prestazionale di catene logistiche quantunque complesse possono essere implementati con approccio modulare, grazie allassemblaggio delle varie unità della supply-chain. Oltre al vantaggio di consentire un approccio alla modellazione di tipo bottom-up (dallo sviluppo di dettaglio del singolo modello allassemblaggio dellintera rete/struttura), questo approccio permette un certo grado di isolamento dei modelli di simulazione: è infatti permesso lo scambio delle sole informazioni non riservate, mantenendo il livello di security preferito sui dati messi a disposizione. il Main Contractor non ha infatti alcuna visibilità delle informazioni scambiate, se non quella strettamente concessa dai diretti subcontractor, differentemente a quanto può avvenire in simulazioni centralizzate.
Per soddisfare tale prerequisito, RTI-HLA è certamente linfrastruttura più appropriata tra quelle attualmente disponibili: infatti, pur essendo sovradimensionata per il contesto di interesse, i vantaggi acquisiti in termini di scalabilità e modularità dei singoli modelli, nonché la possibilità di distribuire in modo controllato le informazioni, risultano certamente significativi ai fini della presente scelta.
DIMEC, Salerno
La sede di Salerno si e preoccupata di condurre una serie di test comparativi. I protocolli di simulazione distribuita, presi in esame per la futura integrazione del simulatore sviluppato, sono stati essenzialmente due: larchitettura HLA ed unapplicazione, appositamente sviluppata in linguaggio Visual Basic, denominata SYNCRO.
Larchitettura HLA, messo a punto dal Defense Modeling and Simulation Office (DMSO), è stata presa in esame grazie soprattutto alla vastissima diffusione che essa vanta nel mondo ed alle infinite applicazioni svolte sia in ambito militare sia civile, tali da renderla un vero e proprio standard nellambiente della simulazione distribuita.
Lapplicazione SYNCRO, sviluppata presso il Dipartimento di Ingegneria Meccanica dellUniversità degli Studi di Salerno, invece, è nata dallesigenza di utilizzare, soprattutto nella fase iniziale di sviluppo del modello, un sistema molto semplice e trasparente per testare i meccanismi di sincronizzazione e lo scambio delle informazioni in rete.
LHLA si caratterizza per le molte funzionalità avanzate possedute, lelevata flessibilità dimpiego e laffidabilità tecnologica. La possibilità allinterno dellambiente di creare diverse federazioni, la gestione dinamica del tempo, la sicurezza delle connessioni in rete e lassenza di un software centralizzato, offrono la possibilità di svolgere in modo efficace ed efficiente tutte le funzioni necessaria al funzionamento della federazione oggetto del progetto in questione.
Di contro lapplicazione SYNCRO, sviluppata presso il DIMEC, si differenza per il fatto di essere un software unico, e, come tale, deve essere eseguito su uno solo dei computer collegati in rete. Esso offre, per la comunicazione verso lesterno, porte Socket per il collegamento dei federati. Tutte le informazioni sui federati vengono raccolte al momento del collegamento degli stessi allapplicazione e salvate allinterno di un database collegato al programma. Le comunicazioni tra il SYNCRO ed i client, sui quali vengono eseguite le applicazioni di simulazione, avvengono direttamente tramite le suddette porte socket, senza bisogno di eseguire altre applicazioni sui computer locali. Tutti i dati scambiati tra i federati, durante lesecuzione della federazione, vengono memorizzati allinterno del database sulla macchina dove è in esecuzione il software SYNCRO; questa soluzione, in futuro, potrebbe risultare vantaggiosa per lottimizzazione globale dellintera catena di sub-fornitura.
Le valutazioni economiche, in fase di studio, non sono state vincolanti, in quanto sia larchitettura HLA, offerta gratuitamente dalla DMSO statunitense, sia lapplicazione SYNCRO, sviluppata interamente allinterno del DIMEC di Salerno, non hanno comportato esborsi finanziari di alcun tipo.
Le valutazioni affidabilistiche, invece, hanno, ovviamente, avvantaggiato nella scelta il prodotto della DMSO, in quanto, già abbondantemente testato in ambiti ben più impegnativi di quelli attualmente allo studio.
Infine, quindi, la scelta è ricaduta sullarchitettura
HLA, dato, anche, il non avanzato stato di sviluppo del software SYNCRO,
che quindi non poteva essere assunto come standard dal punto di vista tecnologico
in vista della futura implementazione con le altre sedi universitarie.
Scelta del Protocollo
DIG, Milano
La simulazione distribuita consente, per definizione, di realizzare modelli separati, cooperanti in ununica corporazione, ma essenzialmente indipendenti. Il paradigma simulativo distribuito risponde intrinsecamente alle problematiche di information sharing e di dislocazione geografica strettamente presenti in una simulazione in ambito di supply chain, in quanto permette, ad esempio, di creare un modello di simulazione per ogni nodo della filiera produttiva che sia in grado di interagire in ununica simulazione (denominata corporazione/federazione) con i modelli degli altri nodi aziendali (figura sotto).
 Simulazione
distribuita in ambito supply chain, concetto di corporazione/federazione
Simulazione
distribuita in ambito supply chain, concetto di corporazione/federazione
Architetture per una simulazione distribuita
La simulazione distribuita è garantita da due principali archetipi strutturali (o framework), caratterizzati da due visioni in antitesi:
Nello stendere una simulazione distribuita occorre pertanto scegliere quale framework di supporto impiegare. La scelta prevede di norma unanalisi condotta secondo diversi criteri operativi, che vanno dalla stabilità di esecuzione della simulazione distribuita, alla velocità di completamento di un run generale, dalla facilitazione in fase di programmazione dei modelli da connettere, allinteroperabilità che la struttura permette di mantenere a livello di linguaggi di programmazione, alla possibile riusabilità di modelli composti in occasione di altri impieghi.
Non entriamo nel dettaglio dei primi due criteri (stabilità e velocità di esecuzione), aventi una natura prettamente informatica, per i quali esistono trattazioni, peraltro discordi, in letteratura; concentriamo invece lattenzione (e quindi la scelta seguente) sui restanti criteri, partendo dalla facilitazione che una architettura comporta, o meno, in fase di implementazione di una simulazione distribuita.
Se si sceglie di implementare una struttura a rete, impiegando uno dei diversi protocolli PDES, occorre cablare allinterno di ogni modello i processi logici ed informatici responsabili dellinterazione tra i simulatori. Nel momento in cui si modifica la composizione della simulazione distribuita, cioè muta il numero di elementi coinvolti (es. viene meno un fornitore), occorre procedere alla modifica di ogni modello, dato che la connessione è del tipo peer-to-peer e nella modifica, come da esempio, viene meno un point della rete stessa.
Tale procedura si rivela certamente dispendiosa (in termini d tempo e risorse) e non si inquadra correttamente in un mondo applicativo di supply chain, nel quale ad un certo punto si può voler verificare una diversa struttura, ad esempio eliminando un dato fornitore. Ne consegue che larchitettura a protocolli distribuiti non è di utile interesse nel progetto corrente.
Larchitettura centripeta, invece, delega il controllo e la gestione dei partecipanti alla simulazione distribuita ad un processo software centralizzato, che mette a disposizione di ogni modello una serie di servizi necessari allesecuzione della simulazione stessa (in particolare i servizi di sincronizzazione e di consegna dei messaggi tra i nodi coinvolti). Il singolo modello non è interessato nella sua struttura fisica a quali nodi sono connessi in una data simulazione (ovviamente lo è a livello logico, es. deve conoscere il nome del fornitore ) e può pertanto essere modificato, nonché sostituito, in maniera indipendente dalla corporazione.
Quindi si intuisce come il framework centripeto sia preferibile in una simulazione distribuita avente come oggetto una SC, poiché, almeno a livello informatico, permette di eseguire simulazioni distribuite diverse, anche per composizione dei partecipanti, senza che si debba modificare ogni modello.
Una volta dimostrata la preponderanza per il framework centripeto, occorre procedere ad una scelta tra i diversi sviluppi presenti in questambito.
Le architetture centralizzate presenti in letteratura si riferiscono a due sviluppi particolari, uno elaborato in ambiente Java, attraverso librerie appositamente create (Java RMI e Corba) e laltro corrispondente al complesso standard High Level Architecture (HLA) prodotto dal DoD statunitense.
Tra i due prevale, anche a livello di numero di applicazioni che ne fanno uso, indiscutibilmente lo standard HLA, che fornisce un elevato grado di interoperabilità di ambienti simulativi ed una effettiva possibile riusabilità dei modelli. Rimandiamo la trattazione sperimentale di confronto tra i due al prossimo paragrafo, mentre illustriamo la preponderanza di HLA fin dora.
I criteri di interoperabilità e di riusabilità sono gli obiettivi dai quali nasce la stessa idea di implementazione di HLA, come è espressamente dichiarato in fase di project presentation nel sito del DMSO. Questi due criteri risultano di particolare importanza in una simulazione distribuita in un ambito di supply chain. In una federazione HLA che ricostruisce una SC, infatti, ogni nodo aziendale può essere modellizzato ricorrendo allo strumento software (simulatore) ed allambiente hardware preferito da ogni singolo analista (criterio dellinteroperabilità), mentre è possibile, in ogni momento, sostituire un modello con unaltra versione, recuperando righe di codice già scritte, purché vengano rispettate le specifiche di base della federazione (criterio della riusabilità).
Inoltre, HLA nasce espressamente come architettura capace di supportare diversi generi di simulazione parallela e distribuita, dalle simulazioni analitiche (come quelle da adottare in una SC), agli ambienti virtuali complessi. Pertanto, HLA fornisce gratuitamente tutta una serie di servizi necessari allimplementazione di una federazione, attraverso il proprio gestore software Run Time Infrastructure (RTI).
Gli altri ambienti basati su una struttura simile al framework
centripeto non permettono il soddisfacimento dei criteri di interoperabilità
e riusabilità propri di HLA, né tanto meno propongono una
soluzione chiara e precisa per le diverse esigenze di simulazione distribuita,
quindi la scelta di HLA risulta scontata alla luce delle precisazioni ed
osservazioni sovra addotte.
DIP, Genova
Alla luce delle analisi e delle sperimentazioni condotte si e deciso di procedere ovviamente nello sviluppo della rete di simulatori schedulatori sfruttando lHigh Level Architecture sulla base di una serie di considerazioni ed ipotesi:
DEF, Firenze
Orientata la scelta architetturale su HLA, è stato necessario individuare la Run Time Infrastructure (RTI) in grado di fornire il supporto per limplementazione della High Level Architecture. Il Dipartimento della Difesa Statunitense, al momento del lancio di HLA ha ritenuto di fornire direttamente una prima RTI, la versione 1.x, che in breve tempo è arrivata alla release RTI 1.3. Parallelamente è iniziato lo sviluppo da parte di aziende private, legate alla difesa americana e su commissione di questultima, di una RTI cosiddetta New Generation (NG) arrivata sul mercato nel 1998. Entrambe queste RTI sono aderenti alle specifiche HLA 1.3, quelle attualmente in vigore e diventate la base per la norma IEEE che ha definito in ambito civile le specifiche di HLA. La versione NG presenta indubbi vantaggi in termini di gestione multi-threading della comunicazione e di una maggiore efficienza (sulla carta) oltre a poter indirizzare un numero di handle (e quindi di oggetti istanziati nella federazione) basati su interi a quattro bytes invece di due. Inizialmente quindi la sperimentazione di protocollo si è indirizzata alluso della RTI1.3NG-v2. Lo sviluppo è iniziato utilizzando come linguaggio di interfacciamento il C++, per poster realizzare una subroutine di tipo DLL (dynamic link library) in grado di mettere in comunicazione qualsiasi applicazione in ambiente Windows NT, ed in particolare lambiente di simulazione Simple++, con lRTI, in grado di colloquiare solo con C++ o Java. In questa fase, molto onerosa a causa della ripida curva di apprendimento relativa alla tecnologia in oggetto per il gruppo di Firenze, è stata verificata una certa instabilità dellRTI NG, che in effetti, al momento, aveva passato solo i test di convalida e certificazione in ambiente SUN Solaris e non sotto MS Windows NT. Il tutto si traduceva in una serie di errori di debugging, chiaro sintomo di una candidate release non definitiva. Dopo una sperimentazione di alcuni mesi su tale RTI si è quindi deciso, di comune accordo con i partner, ed in particolare con la sede di Genova che aveva già fatto esperienze in proposito, di ripiegare sulla più vecchia, ma più robusta, RTI1.3v7, con la quale, pur mancando delle prestazioni aggiuntive dellNG, si è potuto lavorare con una maggiore stabilità. Si è inoltre deciso di utilizza il linguaggio Java per linterfacciamento, più gestibile del C++. E stato anche valutato lonere per il passaggio alle versioni NG, al momento attuale giunte alla release RTI1.3NGv4, che è risultato piuttosto limitato, andando a toccare la definizione dei tipi di variabile per lhandle e solo alcune chiamate a metodi..
DE, LAquila
Parallelamente al lavoro di sviluppo sul sistema di schedulazione, il gruppo dellAquila è stato avviato uno studio per valutare la fattibilità di una rete di simulatori-schedulatori capaci di rappresentare sistemi industriali complessi: nell'ipotesi realistica di più aziende autonome la scelta di realizzare una pianificazione della produzione mediante il ricorso ad una federazione di simulatori, ciascuno volto a rappresentare le attività di ogni singolo attore, è la più rispondente alle richieste di forte approssimazione dei dettagli nei processi reali, di velocità di risposta e di riservatezza dei dati gestiti. La scelta del protocollo di comunicazione, operata a livello di gruppo nazionale dopo una approfondita analisi di soluzioni od architetture alternative, si è orientata verso la High Level Architecture (HLA), protocollo di comunicazione e standard per la definizione di federazioni di simulatori interagenti sviluppato dal Dipartimento della Difesa USA. Questo protocollo prevede la realizzazione di un agente per ogni simulatore che funga da ambasciatore verso la federazione: tutte le attività di scambio di informazioni, pubblicazioni e sottoscrizioni, avvengono attraverso e per mezzo dell'ambasciatore. Il protocollo HLA è indipendente dal particolare simulatore/linguaggio di simulazione utilizzato conferendo grande flessibilità allo sviluppatore dellapplicazione specifica.
Oltre alla caratteristica di prescindere dallimplementazione software, lHLA mette a disposizione potenti mezzi per la gestione del tempo. La gestione del tempo è un aspetto estremamente interessante ed unico; non esistono infatti, al momento, altri standard dedicati alle simulazioni distribuite, vedi CORBA, che prevedono questo tipo di funzionalità. Al fine di preservare le caratteristiche di flessibilità ed interoperabilità è resa possibile lintegrazione di simulatori con modalità di avanzamento temporale totalmente differenti.
Le caratteristiche fondamentali appena esposte permettono di classificare lHLA come uno strumento estremamente efficace ed innovativo per la realizzazione di un ambiente integrato di simulatori.
In questo modo lHLA è fondamentalmente unarchitettura per supportare simulazioni basate su componenti, dove, i componenti sono simulazioni individuali. Larchitettura inoltre supporta la costruzione di simulazioni distribuite su più computers, caratteristica questa assolutamente non obbligatoria ma importante per le applicazioni previste nel presente programma di ricerca.
Ulteriore vantaggio offerto da HLA è che non si tratta di una applicazione industriale proprietaria recentemente recepito anche dalla IEEE; resta ovviamente qualche dubbio minimale circa la garanzia di disponibilità della RTI a seconda delle connotazioni geopolitiche dei soggetti coinvolti, dal momento che lattuale centro di distribuzione fa capo al Ministero della Difesa Americano; tuttavia a seguito dei correnti sviluppi sembra avviarsi verso una release open source e verso un set di possibili pacchetti commerciali di supporto.
DIMEC, Salerno
Una volta individuato il protocollo High Level Architecture (HLA) come ottimale per la realizzazione di applicazioni di simulazione distribuita, grazie soprattutto alle sue caratteristiche di affidabilità e sicurezza, nonché per la sua diffusione come standard a livello mondiale, si è passati alla sperimentazione operativa delle sue funzionalità.
Si è innanzitutto proceduto con linstallazione del software necessario al funzionamento del protocollo. Tale software, denominato Runtime Infrastructure (RTI), è lo strumento che fornisce i servizi di interfaccia comune tra i federati durante lesecuzione della simulazione distribuita. In particolare si è scelto, di comune accordo con le altre sedi universitarie, la versione 1.3 release 7 di tale software. Per permettere il funzionamento corretto dellinfrastruttura, è stato necessario configurare adeguatamente le variabili di ambiente dei sistemi operativi presenti sulle diverse stazioni hardware.
Per testare la corretta configurazione delle stazioni di lavoro e la corretta installazione dellarchitettura si sono utilizzate le federazioni dimostrative presenti nel pacchetto stesso. Tali test, dopo alcune difficoltà iniziali legate essenzialmente alla non corretta definizione di alcune variabili e allerrata collocazione di alcuni file, hanno dato esito positivo permettendo così di passare alla fase di sperimentazione vera e propria dellarchitettura.
A tale scopo si è fatto ricorso ad una federazione che rappresentasse una semplice supply chain, costituita da due unità produttive, un main contractor ed un sub contractor, che scambiano attraverso HLA informazioni relative alla presenza di ordini. Tale federazione, sviluppata dalluniversità di Genova in collaborazione con quella di Riga, consiste in due modelli di simulazione, uno per ognuna delle due unità produttive rappresentate, realizzati in Arena, da un opportuno file (di estensione .fed, necessario ad ogni federazione utilizzante HLA) il quale definisce le caratteristiche della federazione e il tipo di informazioni scambiate tra i due modelli.
La sperimentazione ha messo in evidenza limpossibilità di federare direttamente tramite HLA modelli di simulazione sviluppati utilizzando il linguaggio Arena. Ciò a causa del fatto che Arena utilizza per le operazioni di interfacciamento con lesterno, il linguaggio Visual Basic for Application (VBA), in esso incluso. Tale linguaggio non permette di utilizzare direttamente le librerie e le classi messe a disposizione da HLA, che invece sono realizzate in linguaggio Java o C++.
Per superare questo limite si è fatto ricorso ad
unapplicazione sviluppata in linguaggio Java dal gruppo di ricerca del
DIP di Genova, in grado di utilizzare le funzioni HLA e di metterle a disposizione
dei modelli Arena attraverso la conversione delle istruzioni ricevute ed
inviate da ognuno dei modelli.
Valutazione Sperimentali
DIP; Genova
Nel corso della ricerca il gruppo di Genova ha condotto una serie di esperienze nel campo dellutilizzazione del protocollo HLA, in particolare ha dato vita ad una serie di esperienze di ricerca finalizzate alla sperimentazione pratica del protocollo stesso in ambito logistico.
Con lesperienza NAVI si è realizzato un dimostratore educational in grado di simulare linterazione di imbarcazioni in un tratto di mare tramite unapplicazione HLA sviluppata in Java® su tecnologia Applet®, tale strumento ha costituito la base per la realizzazione di corsi di formazione per i componenti le altri sedi di ricerca consorziate. Attraverso il pacchetto NAVI si è poi iniziato una serie di esperienze volte a testare la portabilità di una federazione in ambiente WAN/Internet anziché LAN. Tale esperienza è culminata con lesercizio SHOW che ha dimostrato la fattibilità di un simulatore logistico distribuito in Internet e con con il tool HORUS per lintegrazione di componenti non-HLA compliant.
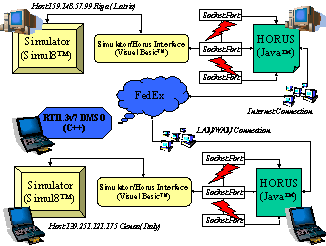
In particolare HORUS consente di separare la parte di modellazione dallo sviluppo della federazione consentendo di concentrare una volta per tutta le funzionalità HLA in un middelware in grado di comunicare con il modello di simulazione attraverso connessioni socket TCP/IP.
La mappatura base di HORUS prevede un albero di oggetti ed attributi che implementano le classi di HLA aggiornate ad ogni step simulativo.
DEF, Firenze
Le alternative possibili sono state testate con lo sviluppo di opportuni layer di comunicazione in ambito RTI-HLA. La scelta della migliore tecnologia per il message-passing è stata indagata, certo non a prescindere della disponibilità di tali features nel/nei software di simulazione. In genere, i sistemi windows-based mettono a disposizione tecnologie basate su Dynamic Link Libraries (DLL), o metodi equivalenti. Analogamente, per linterprocess-communication, è possibile gestire lo scambio dati tramite socket, direttamente su protocollo TCP/IP (questo è certamente vero in SIMPLE++ grazie alloggetto Socket, ed in ARENA con la scrittura di codice tramite leditor Visual Basic for Application, istanziando nello specifico uno o più Win-Socket control). La comunicazione tramite socket deve ovviamente avvenire in modalità listen, in modo che i callback asincroni originati dallRTI possano essere correttamente processati anche durante il simulation run.
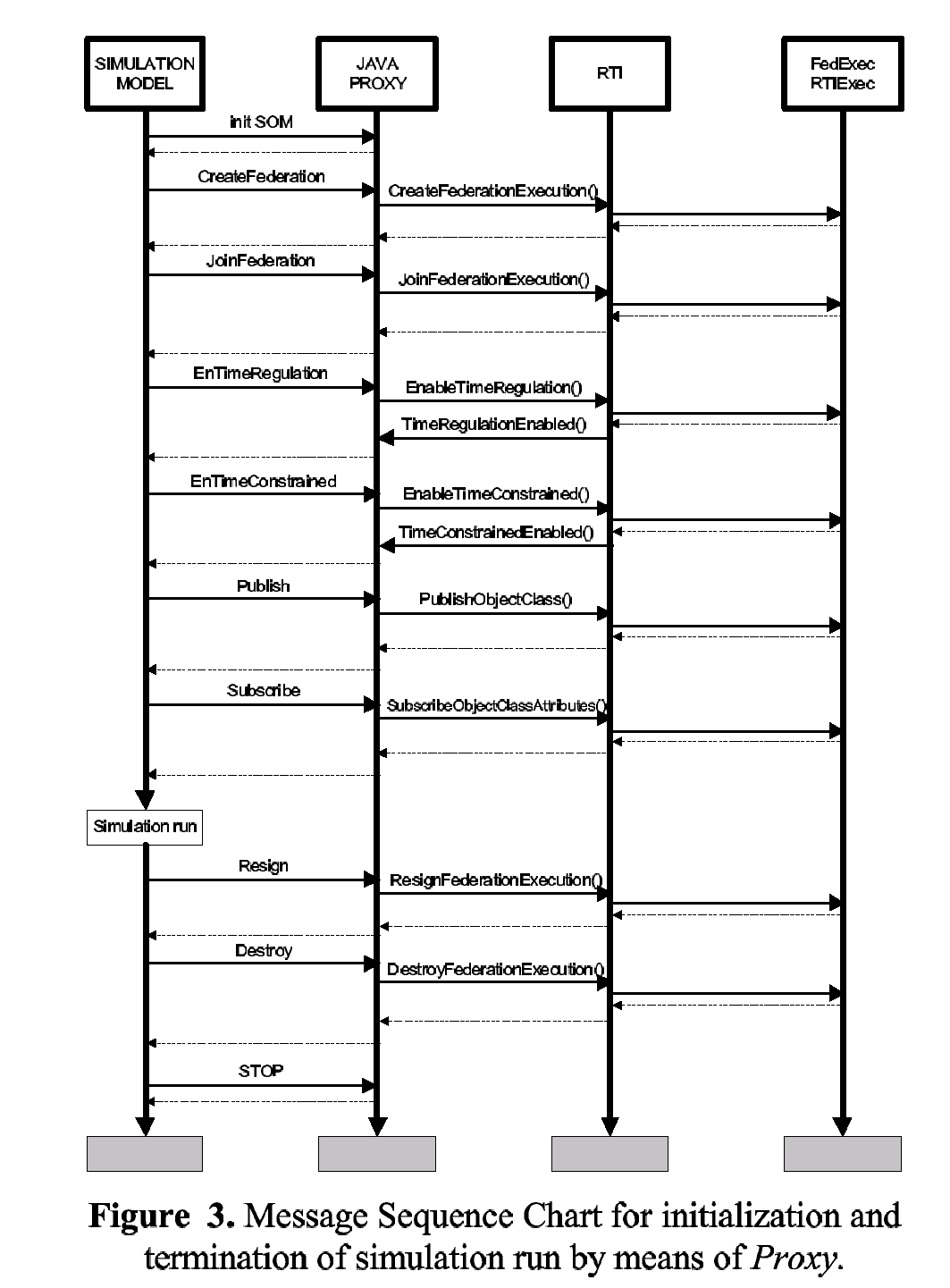
Message Sequence Chart per inizializzare e terminare la simulazione tramite Proxy
La sperimentazione ha consentito di verificare che nella
prima soluzione (sviluppo interfaccia Proxy) la compatibilità tra
infrastruttura HLA e generico simulatore risulta concettualmente più
robusta, ed il risultato finale è facilmente riutilizzabile, mentre
il secondo caso (sviluppo interfaccia delegata), risulta da preferirsi
ai fini del successo del singolo progetto di simulazione distribuita, in
quanto è richiesto un minor lavoro di sviluppo, a discapito però
della riutilizzabilità.
DE, LAquila
Operata la scelta del protocollo ottimale si è passati alla sperimentazione delle possibili modalità di implementazione. In particolare lattività ha riguardato la definizione delle tecniche tramite cui permettere al simulatore del sistema produttivo di colloquiare con altri simulatori, durante lesecuzione della simulazione, secondo il protocollo HLA. Tale attività di studio si è resa necessaria poichè Arena non è ancora direttamente compatibile con il protocollo HLA. Ciò ha richiesto lo sviluppo una procedura ad hoc definita "Ambassador"che fungesse da interfaccia tra il simulatore e lesterno secondo le regole del protocollo HLA e di una apposita architettura logica locale.
E stato inoltre implementato in ARENA un modello di sistema produttivo generico che potesse fungere sia da main contractor che da sub fornitore generico per consentire la verifica delle funzionalità implementate.
Più in dettaglio le problematiche risolte di interfacciamento Arena-HLA sono state le seguenti:
Come già detto lAmbassador è perennemente collegato con i processi esterni e mantiene gli aggiornamenti per il simulatore; mentre la DLL si attiva solamente per richiesta da parte di ARENA per poi disattivarsi al termine del servizio. Il comportamento dell'Ambassador può essere assimilato a quello di un server.
Come per la DLL, anche in questa procedura la modularità
del codice permette l'aggiunta di nuovi oggetti trattati in federazione
con poco sforzo. E' infatti sufficiente inserire delle classi sulla falsariga
di quelle già presenti e farne riferimento nelle funzioni di interfaccia
e nelle callback senza apportare alcuna modifica alla struttura del codice.
In questo modo l'aggiunta di un altro federato, mantenendo ovviamente ARENA
come simulatore, con funzionalità diverse da quelle dell'unità
produttiva comporterebbe, come onere concettuale, la sola ridefinizione
dei nuovi oggetti d'interazione. Onere che ricade nella definizione delle
specifiche e prescinde dall'implementazione del software.
La DLL viene invece attivata nel momento in cui si necessita di un servizio di interazione con la federazione. L'Ambassador andrà ad interrogare ciclicamente la porta dedicata alla trasmissione dei dati con la DLL. Nel momento in cui viene verificata la presenza di un tentativo di connessione l'Ambassador provvederà a rendere disponibile o acquisire i dati del simulatore. Poiché è prevista un'interrogazione ciclica della porta da parte dell'Ambassador, la DLL, nel momento in cui viene ad essere attivata, non dovrà fare altro che tentare di connettersi con il server (assumendo quindi un tipico comportamento da client).
Una volta definite le modalità di implementazione del collegamento tra un generico simulatore realizzato in Arena e lesterno, secondo i requisiti del protocollo HLA, si è passati alla sperimentazione dellarchitettura ideata mediante test di integrazione locale tra più simulatori.
A questo scopo si è ipotizzato che lo scambio dati tra simulatori sia relativo alla lettura/pubblicazione di ordini di acquisto e conferma di produzione eseguita.
E stato inoltre testato il processo di sincronizzazione tra più simulatori implementando la modalità per cui si prevede che tutti i fornitori si colleghino alla federazione e che per ultimo si colleghi il main contractor. Per avviare una federato è necessario, come prima cosa, attivare l'Ambassador. Questo processo, dopo essersi collegato alla federazione, chiederà l'avvio del simulatore. Il modello da simulare deve prevedere, come primo evento, l'ingresso in un blocco EVENT con parametro opportuno. In questo modo l'Ambassador manterrà bloccato il simulatore finché non saranno terminate tutte le procedure di sincronizzazione della federazione, ovvero non si sarà collegato il main contractor. Un volta avviata la federazione, il controllo viene restituito al simulatore, che provvederà a processare il modello.
Per verificare le funzionalità implementate è stato costruito un modello, generico per main contractor e sub fornitori, che prevede:

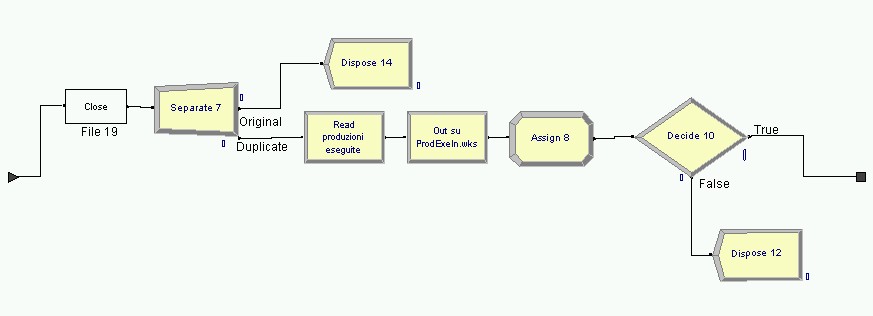
Il modello è in grado di implementare sia il main contractor che i sub fornitori. E' infatti sufficiente agire sul blocco "Create 1" per fare in modo che non vengano create entità e quindi non vengano emessi ordini.
Numerosi test sono stati eseguiti per la verifica pratica delle funzionalità implementate. In particolare sono stati eseguiti tutta una serie di test volti a verificare la stabilità delle connessioni tra le strutture SW in gioco. Un primo livello di test è stato effettuato per verificare il mantenimento dellallineamento temporale tra i simulatori. In questo primo set di test non era previsto lo scambio di dati tra simulatori poiché, oltre allavanzamento temporale, si andava implicitamente a testare anche ladeguatezza della struttura HW implementata. Verificato il mantenimento dellallineamento temporale si è proceduto ad una successiva complicazione del simulatore introducendo lo scambio di dati. E stato quindi introdotto un oggetto con un singolo parametro.
I test si sono sviluppati nel seguente modo:
Nellambito della ricerca dellarchitettura, o protocollo, ottimale da impiegare nella stesura di una simulazione distribuita in un ambiente di produzione e logistica, sono state condotte diverse sperimentazioni presso lunità di Milano, che hanno, più o meno impiegato, le strutture sovra descritte.
A livello di logica a rete si inquadrano i primi studi, condotti in fase di avvio della ricerca, sulla comunicabilità di modelli aziendali costruiti nellambiente di simulazione SIMPLE++. Ricorrendo alla possibilità che tale simulatore ha di scambiare messaggi attraverso porte socket hardware di più calcolatori in una rete a protocollo informatico TCP/IP, sono stati condotti alcuni esperimenti su una piccola SC composta da un solo fornitore e un solo cliente. Il simulatore del cliente è in grado di inviare degli ordini di produzione al simulatore del fornitore, bloccando e sbloccando il proprio orologio di simulazione interno a seconda dei messaggi inviati e ricevuti, mentre allopposto il simulatore del fornitore è in grado di inviare messaggi di produzione eseguita, funzionando in modo contrario al simulatore del cliente. Ovviamente, in una corporazione di siffatto genere non è possibile gestire una vera e propria sincronizzazione tra i simulatori; inoltre tale simulazione è realizzabile solo con due modelli alla volta. Tale sperimentazione è stata però utile per la stesura dellintegrazione del simulatore SIMPLE++ con HLA.
Nellambito delle architetture centripete si inquadrano invece due sperimentazioni: una realizzata in un ambiente Java RMI e laltra corrispondente ad una federazione HLA, poi creata effettivamente nel progetto.
Come già si è detto precedentemente, lambiente Java RMI permette la gestione di più modelli di simulazione, programmati in un ambiente aperto, o direttamente scritto, in Java, come risulta essere il simulatore SILK. Attraverso i livelli di comunicazione permessi da RMI, i modelli di simulazione possono scambiarsi dei messaggi di interazione. In tale ambiente non è però presente un vero e proprio sistema software responsabile della simulazione distribuita, anche se è possibile ricorrere ad una sua implementazione customizzata. La sperimentazione condotta ha dimostrato la complessità di gestione e programmazione di tale ambiente, nel quale neanche esiste un servizio di sincronizzazione temporale, per cui esso è stato lasciato in disparte.
La sperimentazione con HLA ha invece permesso di individuare in tale architettura uno strumento realmente efficace per la conduzione di una simulazione distribuita; HLA fornisce un software di gestione ed uno standard di modellazione effettivamente in grado di garantire linteroperabilità e la riusabilità dei modelli.
HLA permette effettivamente un elevato livello di interoperabilità, come il numero e la diversità dei simulatori impiegati nella ricerca testimoniano. Una volta che i simulatori commerciali prescelti sono stati integrati nel mondo delle specifiche HLA, la federazione instanziata non ha avuto alcun problema di comunicabilità nonostante che siano stati impiegati linguaggi, simulatori ed approcci totalmente diversi.
La stessa riusabilità è stata effettivamente comprovata: ad esempio, più versioni dello stesso modello elaborato dallunità di Milano sono state elaborate e testate senza che non fosse toccata alcuna procedura di connessione con la federazione.
Le sperimentazioni sovra descritte sono state in parte valutate ricorrendo, oltre ai criteri qualitativi e tecnologici precedentemente illustrati, anche ad un analisi quantitativa.
Larchitettura basata su Java RMI è stata sottoposta ad un testing concernete la velocità di esecuzione della simulazione distribuita fra due nodi aziendali. Sono stati confrontati due scenari fisici diversi: uno in cui entrambi i modelli erano residenti sullo stesso calcolatore (simulazione parallela) ed uno in cui ogni modello era dislocato su un calcolatore indipendente posto in una rete LAN (simulazione distribuita). Da questo confronto è emersa una pesantezza di non poco conto tra le due soluzioni, dovuta essenzialmente al tempo di trasferimento dei messaggi in rete.
Una analisi simile è stata condotta, in parte, con la federazione realizzata tramite HLA, ma non si è giunti ad una sostanziale identificazione di ragguardevoli differenze. Tale analisi è stata certamente complicata, pertanto inficiata, dal maggior numero di modelli coinvolti nella simulazione distribuita, la cui attivazione ed instanziazione è stata sempre condotta da operatori umani, soggetti a notevoli errori. Per le osservazioni concernenti la valutazione dei criteri di carattere meramente informatico, come stabilità e velocità si rimanda alla letteratura.
La scelta dellarchitettura HLA è stata pertanto presa soprattutto alla luce delle valutazione qualitative concernenti i criteri di interoperabilità e riusabilità sopra presentati, nonché rispetto alleffettivo vantaggio che una logica centripeta permette di ricavare in fase di modellazione, come sopra dichiarato.
Le sperimentazioni sovra descritte sono state in parte valutate ricorrendo, oltre ai criteri qualitativi e tecnologici precedentemente illustrati, anche ad un analisi quantitativa.
Larchitettura basata su Java RMI è stata sottoposta ad un testing concernete la velocità di esecuzione della simulazione distribuita fra due nodi aziendali. Sono stati confrontati due scenari fisici diversi: uno in cui entrambi i modelli erano residenti sullo stesso calcolatore (simulazione parallela) ed uno in cui ogni modello era dislocato su un calcolatore indipendente posto in una rete LAN (simulazione distribuita). Da questo confronto è emersa una pesantezza di non poco conto tra le due soluzioni, dovuta essenzialmente al tempo di trasferimento dei messaggi in rete.
Una analisi simile è stata condotta, in parte, con la federazione realizzata tramite HLA, ma non si è giunti ad una sostanziale identificazione di ragguardevoli differenze. Tale analisi è stata certamente complicata, pertanto inficiata, dal maggior numero di modelli coinvolti nella simulazione distribuita, la cui attivazione ed instanziazione è stata sempre condotta da operatori umani, soggetti a notevoli errori. Per le osservazioni concernenti la valutazione dei criteri di carattere meramente informatico, come stabilità e velocità si rimanda alla letteratura.
La scelta dellarchitettura HLA è stata pertanto presa soprattutto alla luce delle valutazione qualitative concernenti i criteri di interoperabilità e riusabilità sopra presentati, nonché rispetto alleffettivo vantaggio che una logica centripeta permette di ricavare in fase di modellazione, come sopra dichiarato.
DIMEC, Salerno
Lo sviluppo del modello di simulazione è stato preceduto da una valutazione sperimentale, in primo luogo, del software da adottare per lo sviluppo fisico del modello ed in seguito delle caratteristiche tecniche del modello stesso di simulazione.
Il primo software preso in esame è stato lambiente di simulazione Taylor, già in dotazione al gruppo di ricerca. Le prove condotte, però, hanno evidenziato larretratezza del pacchetto soprattutto dal punto di vista delle possibilità di interfacciarsi con lesterno, dovuta principalmente alla non aggiornatissima versione in nostro possesso.
Tale possibilità, assolutamente necessaria per lo sviluppo di un simulatore in grado di dialogare e di interfacciarsi in rete con altri simulatori, ha portato alla sperimentazione del software Arena della Systems Modelling versione 4. Il software abbastanza recente è in grado di mettere a disposizione dello sviluppatore i più moderni sistemi di programmazione per la personalizzazione dellambiente, infatti, la presenza allinterno dellambiente stesso, del Visual Basic for application, ha consentito di risolvere tutti i problemi di interfacciamento verso lesterno che il progetto richiedeva e di collegarsi alla base dati predisposta.
Una volta scelto lambiente di simulazione, la sperimentazione è proseguita realizzando una prima versione del modello che scrivesse tutte le informazioni scambiate con lesterno in una serie di "file testo", facilmente accessibili da altre applicazioni. Questa soluzione poteva svincolare completamente il sistema da qualunque architettura fosse stata scelta per lintegrazione in rete dei simulatori.
In seguito, poi, si è pensato alla possibilità
di consentire ai modelli di dialogare direttamente in rete intranet/internet
attraverso la predisposizione di porte compatibili con il protocollo TCP/IP
e di delegare il modello Arena stesso alla gestione di tutte le operazioni
di lettura e scrittura dei files direttamente sul computer locale.
Test con altri Gruppi Ricerca
DIP, Genova
Il DIP in qualità di coordinatore del progetto ed in virtu della sua preponderante esperienza nel settore della simulazione e dellimpiego dellHLA ha potuto procedere ad una serie estesa di test e confronti con altri centri di ricerca nazionali ed internazionali con i quali sono attive cooperazioni e progetti.
In effetti il DIP e promotore di una iniziativa di Simulation Networking con aziende Italiane allavanguardia nel settore; tale iniziativa, denominata SIREN, ha consentito di condurre estese sperimentazioni dei modelli sviluppati nel corso del presente progetto in particolare in cooperazioni con Alenia Aerospazio, Società Italiana Avionica, Fincantieri/Catena, Datamat; in queste esperienze sono stati confrontati sviluppi ed il DIP ha avuto modo di promuovere lo sviluppo di competenze HLA in alcune principali aziende italiane.
I risultati ottenuti e gli argomenti trattati allinterno dei meeting e dei seminari SIREN hanno coinvolto anche settori pubblici e governativi ed in particolare vale la pena di segnalare il Centro Operativo Interforze, CETIS, Scuola di Guerra dellEsercito, Arsenale Militare Marittimo di Taranto; lesperienza SIREN con particolare riferimento ad alcuni risultati ottenuti dal DIP nellambito del presente progetto ha coinvolto inoltre soggetti dellindustria tradizionale (i.e. Centro Ricerche Fiat) e della Grande Distribuzione (COOP).
Rappresentanti di tutte queste realtà hanno partecipato a meeting e seminari ove i risultati sono stati condivisi e le metodologie descritte e proposte.
I contatti internazionali da sempre attivi dal DIP con i principali gruppi di ricerca su HLA e sulla simulazione sono risultati molto proficui; a questo proposito vale la pena di sottolineare la sperimentazione del sistema Horus sviluppato nel corso del progetto condotta in stretta cooperazione con la Riga Technical University (Dipartimento di Modelling & Simulation) tramite prove in remoto e con il supporto di ripetuti scambi sia di docenti che di studenti fra entrambe le realtà (i.e. 2 studenti ed un docente Italiano inviati a
Riga e due docenti ed uno studente Lettone in visita presso il laboratorio HLA del Polo Savonese del DIP).
Nellambito di questa cooperazione il DIP ha superato con successo la prima serie di test di Integrazione del sistema SHOW su rete geografica non dedicata (internet) operando con Riga gia nel dicembre 2000 e fornendo una dimostrazione ai partner del consorzio in occasione dellultimo meeting del corrente progetto relativo allanno 2000. Bisogna inoltre ricordare che presso il DIP ha sede un centro del McLeod Institute of Simulation Science (MISS, 19 sedi distribuite in tutto il mondo), la fondazione internazionale che si occupa di promuovere la formazione in questo settore e che negli anni scorsi ha fornito il materiale tecnico didattico al DMSO; in questambito e stato possibile supportare la diffusione di queste competenze anche agli altri partners del consorzio di questo progetto sia tramite seminari organizzati presso il centro HLA DIP, sia con esperti del MISS; questi contatti sono stati un supporto importante anche per convalidare lapproccio metodologio e verificare leffettiva innovatività della proposta impostata.
Il DIP, tramite il suo stretto legame con il Liophant Simulation Club, ottiene inoltre contatti e relazioni con i principali centri di ricerca NordAmericani, in particolare può beneficiare di un framework agreement con il National Center for Simulation (Orlando FL)che coinvolge tutti i principali soggetti attivi del campo HLA; in questambito sono state effettuate visiti e seminari che hanno consentito di verificare gli approcci proposti dal DIP nellambito del corrente progetto e convalidare i risultati.
Test e dimostrazioni sono inoltre state condotte nellambito
di cooperazioni in essere con centri industriali di eccellenza in Nord
America (CAE, Ford Motor Co) e accademici e governativi in Nord Europa
(University of Magdeburg, IFF Fraunhofer Institute); nel corso di tali
collaborazioni sono stati testati gli esercizi NAVI, SHOW ed HORUS.
Sviluppo infrastruttura Internet/Intranet
DIP, Genova
Il DIP custruendo una war room per i test internet ed intranet si e occupata con particolare attenzione della architettura di rete di supporto per il progetto in corso.
Architettura della Rete
Iniziamo con lanalizzare larchitettura che, nel complesso, realizza il generico federato della federazione in via di sviluppo. Il compito del federato, secondo le specifiche di progetto, è di simulare ununità produttiva ed interagire con gli altri federati tramite la struttura prevista dallHLA. Poiché sia ARENA che Simple++, ottimi per la simulazione di processi industriali, non sono compatibili con HLA; è necessario implementare una sorta di interfaccia, figura per realizzare lintegrazione.
Lincompatibilità tra questi tool di simulazione e HLA è dovuta allimpossibilità di "forzare", dallesterno, il flusso di simulazione allinterno di essi.
HLA prevede, infatti, per linterazione tra federati, una logica che può essere riassunta nelle seguenti regole:
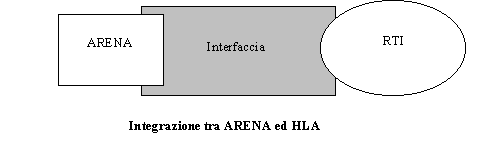
Nel momento in cui si verifica un evento interno, il federato produce un aggiornamento, in federazione, dei dati che lo riguardano. Laggiornamento realizzato tramite le funzioni di interfaccia.
Il federato viene avvisato, dallRTI, della presenza di un aggiornamento su dati di cui aveva dichiarato linteresse. Avviso che perviene al federato per mezzo di callback.
La prima regola è facilmente implementabile; fa infatti parte della logica dei simulatori, lo sviluppare una serie di azioni in seguito al verificarsi di un evento. La seconda regola, che prevede linterruzione dallesterno del flusso di simulazione, non rientra nella logica di essi.
Il simulatore ARENA o Simple++ non sono infatti sensibili ad eventi provenienti dallesterno e di conseguenza un evento quale, ad esempio, larrivo di un nuovo ordine da parte di un cliente non potrebbe essere integrato nel flusso di simulazione.
Vista limpossibilità di interrompere ARENA o Simple++ dallesterno, è necessario che il modello di simulazione esegua uninterrogazione, ciclica, alla ricerca di aggiornamenti dalla federazione. Per fare ciò sono state implementate una serie di primitive, richiamabili mediante laccesso a dei blocchi, dallinterno del modello, che provvedono allinterazione verso lesterno.
Larchitettura implementata prevede che sia una serie di comandi in Visual Basic ad occuparsi dellinterazione con lAmbassador, tramite lutilizzo dei protocolli TCP/IP
E importante sottolineare che il processo che fa da "tramite" tra il simulatore e la federazione è lAmbassador. Tale processo prevede, al suo interno, tutte le funzionalità necessarie ad emettere aggiornamenti in federazione ed a riceverne.
LAmbassador è infatti perennemente collegato con la federazione e provvederà a:
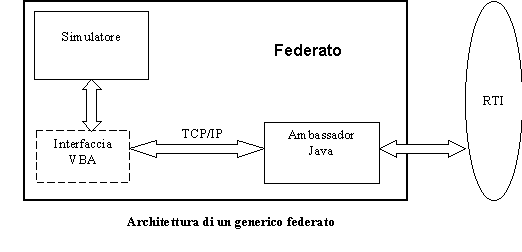
Il DIP ha sviluppato un sito web dedicato al progetto per la diffusione delle informazioni di interesse (programmazione lavori, condivisione fonti) oltre a fornire servizi ftp per la distribuzione del materiale sviluppato.
DEF, Firenze
Vale la pena di verificare nel dettaglio come è stato invece realizzata la comunicazione SIMPLE++ - RTI-HLA. Il federato interagisce con la federazione su una infrastruttura internet/intranet, accedendo ai servizi RTI ed ai metodi di specializzazione di tali servizi tramite un interfaccia codificata in Java. Linterfaccia (come specificato, di tipo proxy) decodifica un messaggio ricevuto dal federato per attivare la relativa funzione RTI, ovvero interpreta il codice messaggio per attivare la corrispondente funzione, quindi trasmette alla funzione gli argomenti trasportati dal messaggio del chiamante; in ritorno, il java code comunica un messaggio codificato che, una volta interpretato, consente al federato di conoscere lesito finale dell'esecuzione della funzione. I messaggi di attivazione dei servizi (con i relativi argomenti richiesti) e i risultati dei servizi (ritorni) vengono inviati/ricevuti dal federato tramite lapertura di comunicazioni socket su porta assegnata e protocollo TCP/IP. Il modello di interazione è rappresentato dall'architettura di figura seguente.
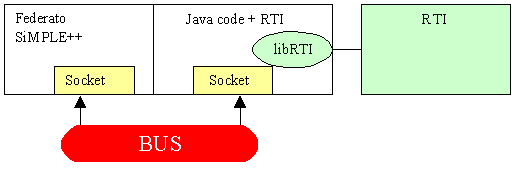
Architettura dellinfrastruttura internet/intranet tra federato (SiMPLE++) e federazione
Nello sviluppo del modello è stata rispettata la volontà di creare una struttura modulare, ove fosse presente un layer dedicato allinterfacciamento con il Java Proxy ed un layer che contenesse la struttura fisica del modello di simulazione.
Grazie a questo approccio, è sufficiente sostituire il frame contenente il modello del sistema produttivo, per riutilizzare larchitettura in una nuova federazione, purché siano seguite delle precise specifiche, secondo cui, dopo inizializzazione della federazione, lattore locale (federato) passa in stato di running. Questo stato è sospeso ad intervalli regolari, in base ad un Time Step assegnato (nelle prove sono stati impiegati intervalli pari ad una settimana lavorativa).
A ogni step viene attuata la connessione del federato alla federazione, tramite la chiamata di un metodo del simulatore che sospende il clock ed apre il socket di comunicazione con il Proxy. Segue quindi lUpdate delle informazioni elaborate dal simulatore durante la permanenza nel cono dombra della federazione (ad esempio, invio delle informazioni relative alle spedizioni in corso). Terminata questa fase, viene richiesto il permesso per lavanzamento nel tempo, che consente di scatenare il metodo di CheckUpdated (verifica degli aggiornamenti degli oggetti e delle interazioni di interesse). Al termine della ricezione degli aggiornamenti, il clock di simulazione è fatto partire nuovamente.
DE, LAquila
Allo scopo di simulare linterazione tra simulatori in ambiente fisicamente distribuito, i simulatori dei vari siti aziendali sono stati istallati su differenti PC collegati per mezzo di una rete LAN presso il Dipartimento di Energetica dellUniversità di LAquila.
In un passo successivo, in cui era necessaria una visibilità a livello di rete Internet, la rete locale è stata aperta verso lesterno tramite collegamento al server di Facoltà. In particolare durante tutta la durata del progetto di ricerca sono state utilizzate le seguenti risorse HW:
| N° | Descrizione | Quantità |
| 1 | PC Athlon 750 Mhz | 4 |
| 2 | HUB 8 porte | 1 |
Le risorse in questione hanno permesso di simulare una SC con un numero di componenti adeguati a valutare leffettiva risposta del simulatore sviluppato. Si è voluto infatti sottoporre il simulatore ad un carico di lavoro che si avvicinasse il più possibile alla realtà e per fare ciò è risultato indispensabile tener conto di un numero adeguato di clienti/fornitori nonché di tutte le problematiche relative alla distribuzione della SC.
DIMEC, Salerno
Per lintegrazione del modello di simulazione in rete è stata scelta la seguente metodologia:
1. Sperimentazione delle porte di comunicazione su computer locale.
Tale sperimentazione è stata condotta utilizzando per le prove piccoli software sviluppati in Visual Basic che utilizzassero le porte socket per la connessione e lo scambio dati.
La rete internet è servita come supporto fisico dello svolgimento della federazione HLA progettata. Limpiego della rete internet, o meglio, limpiego del protocollo TCP/IP, che permette lesistenza della rete, è infatti intrinsecamente inserito nelluso di HLA.
Il file RTI.RID prevede, nel caso di un esecuzione in rete WAN, di specificare lindirizzo IP della macchina ove risiede il processo logico RtiExec.exe, responsabile della gestione e dello sviluppo fisico di una federazione HLA. Quindi il protocollo IP, responsabile dellindirizzamento dei computer, è necessario in una federazione HLA.
Inoltre, il protocollo IP è necessario per il mantenimento della comunicabilità tra il simulatore SIMPLE ++ ed il servizio di integrazione fornito dal Java proxy, in quanto la connessione avviene tra porte socket, in teoria, anche di più computer, per lindirizzamento delle quali occorre specifica lIP address del calcolatore su cui risiede il proxy.
La rete internet ha inoltre consentito lutilizzo continuo di infrastrutture per la comunicazione a distanza (chat dedicate, servizi ftp, incontri Netmeeting) che si è mantenuto tra le diverse sedi, anche per fasi di mera esecuzione delle federazioni (testing monitorato a distanza).
DIMEG, Bari
Limplementazione HLA è sviluppata secondo unarchitettura ad oggetti basata su codici come C++ o Java che non consentono lintegrazione diretta in ambiente HLA di moduli VBA. Si sono pertanto studiate le possibilità di integrazione, in un ambiente di programmazione ad oggetti, di simulatori non "HLA compliant" (come quelli in ARENA®) e di simulatori "general purpose". Si è pervenuti alla definizione di unarchitettura di integrazione basata sullo scambio di dati mediante unità di trasmissione standardizzate, dette "sockets". Le "sockets" consentono la trasmissione dei dati in codice binario in maniera indipendente dallarchitettura logica, ad oggetti o procedurale, dei diversi simulatori interagenti. Il modello di architettura sviluppato per lintegrazione HLA del modulo di simulazione in ARENA® consente lintegrazione dei simulatori con moduli esterni di qualsiasi tipologia , purché in grado di trasmettere dati mediante "sockets". Per lintegrazione di simulatori "general pur pose", non abilitati alluso di "sockets", è stata adottata una soluzione diversa basata su file di dati opportunamente gestiti.
DPGI, Napoli
Ai fini della realizzazione di una efficace integrazione
del modello di simulazione allinterno dellintera federazione, si è
proceduto, dal punto di vista metodologico in modo analogo alla sede di
Salerno seguendo la stessa procedura.
Sviluppo Interfacce in Java
DIP, Genova
Le interfacce in Java® realizzate hanno consentito di implementare in HLA uno strumento software denominato HORUS (Hla Operative Relay Using Sockets) in grado di poter gestire la parte dichiarativa e di run time della federazione stessa.
Attraverso la tecnologia Sockets qualunque tool di simulazione in grado di gestire una connessione sockets viene ad essere integrato nellarchitettura federativa. Infatti attraverso la lettura e scrittura su socket il tool di simulazione viene ad essere aggiornato sui valori degli attributi delle classi HLA.
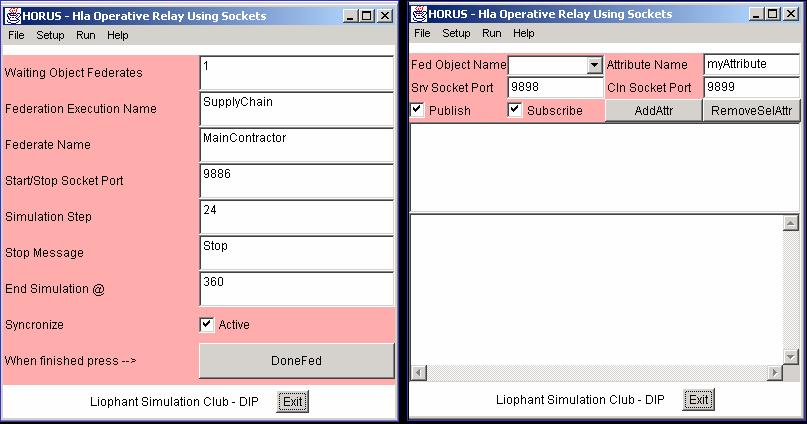 La
gestione del tempo del simulatore viene sincronizzata con la federazione
mediante il controllo remoto dellavanzamento temporale su una porta socket
opportuna. Su questa connessione è presente il Time Advance Grant
a cui il modello è autorizzato a sincronizzarsi.
La
gestione del tempo del simulatore viene sincronizzata con la federazione
mediante il controllo remoto dellavanzamento temporale su una porta socket
opportuna. Su questa connessione è presente il Time Advance Grant
a cui il modello è autorizzato a sincronizzarsi.
Allinterno del tool vengono ad essere dunque mappati tutti gli oggetti relativi alle classi HLA sensibili per la federazione. La sincronizzazione allistante iniziale (o tempo zero) è ottenuta mediante la registrazione di opportuni Synchronization Point .
Mentre le procedura Setup consente di configurare lesercizio di simulazione il menù run permette di lanciare e controllare la federation execution. Il setup è suddiviso in tre sotto-menù: Federation, per la definizione dei controlli di start/stop e sincronizzazione, Object per la definizione delle classi di oggetti HLA e Attribute per la gestione delle pubblicazioni e sottoscrizioni.
Lesperienza accumulata in NAVI e SHOW è stata qui riassunta in una forma facilmente accessibile e resa disponibile anche per utenti non particolarmente competenti in HLA programming.
La metodologia è stata testata con lesperienza SHOW attraverso la ridefinione dellarchitettura funzionale di SHOW stesso, in questo modo la parte di gestione dellHLA di SHOW è stata trasferita in HORUS consentendo di poter realizzare un interessante trade-off tra gli approcci classico e HORUS.
DEF, Firenze
Per lutilizzo di simulatori non HLA-compliant, è
stato necessario realizzare un interfaccia Java (Proxy) per la comunicazione
fra i servizi RTI e i modelli di simulazione tramite protocollo TCP/IP.
Il simulatore comunica con il Proxy, che può risiedere sulla stessa
macchina dove risiede il modello di simulazione, come pure su una macchina
dedicata. La comunicazione avviene attraverso socket, tra Proxy e modello
in modalità sincrona, e tra Proxy ed Ambassador in modalità
asincrona (per la ricezione dei messaggi di ritorno dalla federazione).
Lintento è stato quello di sviluppare un interfaccia che si adattasse
ad ogni possibile scenario simulativo (massima flessibilità), e
per questo motivo la compliance con HLA è stata delegata
alla responsabilità del modello di simulazione, e non del Proxy
(per così dire, linterfaccia è trasparente, e si
occupa della decodifica dei messaggi ricevuti dal simulatore al fine di
attivare la relativa funzione RTI e di ritornare l'esito dellesecuzione
al simulatore). Di seguito sono riassunte le function RTI che il
proxy è capace di interpretare, con relativa sintassi in chiamata
ed in ritorno. Tali specifiche sono state sviluppate in collaborazione
con la sede di Milano.
| Funzione RTI | sintassi OUT | sintassi IN | Note |
| CREATE | "CreateFederation, FederationName, FedFile" | "ExecValue, Command, Message" | sia in caso di creazione FedExec, sia in caso di FederationExecutionAlreadyExists exception il valore di ritorno è 0 se il comando viene eseguito correttamente |
| "string, string, string" | "integer, string , string" | ||
| --- | "-1, CreateFederation,
Error Code" execution failed
"0, CreateFedereation " otherwise |
||
| JOIN | "JoinFederation, FederationName, FederateName" | " ExecValue, Command, Pointer, Message" | |
| "string, string, string" | "integer, string , integer, string" | ||
| "-1, JoinFederation,
213, Error Code" execution failed
"0, JoinFederation, 213" otherwise |
|||
| RESIGN | "ResignFederation, pointer" | "ExecValue, Command, Message" | pointer è il valore di ritorno in interazione JOIN |
| "string, integer" | "integer, string , string" | ||
| "-1, ResignFederation
, Error Code" execution failed
"0, ResignFederation " otherwise |
|||
| DESTROY | "DestroyFederation, FederationName" | "ExecValue, Command, Message" | |
| "string, string" | "integer, string , string" | ||
| --- | "-1, DestroyFederation,
Error Code" execution failed
"0, DestroyFederation" otherwise |
||
| ENTIMECONSTR | "EnTimeConstrained, pointer" | "ExecValue, Command, Message" | pointer è il valore di ritorno in interazione JOIN |
| "string, integer" | "integer, string , string" | ||
| "-1, EnTimeConstrained,
Error Code" execution failed
"0, EnTimeConstrained " otherwise |
|||
| ENTIMEREG | "EnTimeRegulation, pointer, Time, Look ahead" | "ExecValue, Command, Message" | pointer è il valore di ritorno in interazione JOIN |
| "string, integer, double, double" | "integer, string , string" | ||
| Pointer è il valore di ritorno in interazione CREATE | "-1, EnTimeRegulation,
Error Code" execution failed
"0, EnTimeRegulation" otherwise |
||
| ENASYNCHRONOUSDELIVERY | " EnAsynchronousdelivery, pointer" | "ExecValue, Command, Message" | pointer è il valore di ritorno in interazione JOIN |
| "string, integer" | "integer, string , string" | ||
| "-1, EnAsynchronousdelivery,
Error Code" execution failed
"0, EnAsynchronousdelivery " otherwise |
| PUBLISH | "Publish, pointer, tipo_class, nome_class, attrib1, " | "ExecValue, Command, Message" | |
| "string, integer, integer, string, string, " | "integer, string , string" | ||
| "-1, Publish,
Error Code" execution failed
"0, Publish " otherwise |
pointer è
il valore di ritorno in interazione JOIN
Tipo_class = 1 per object_class, Tipo_class = 2 per interaction_class Per Nome_Class e Attrib1 cfr.specifiche FOM+ estensione riportata in doc corrente |
||
| SUBSCRIBE | |||
| "Subscribe, pointer, tipo_class, nome_class, attrib1, " | "ExecValue, Command, Message" | ||
| "string, integer, integer, string, string, " | "integer, string , string" | ||
| "-1, Subscribe,
Error Code" execution failed
"0, Subscribe " otherwise |
Pointer è
il valore di ritorno in interazione CREATE
Tipo_class = 1 per object_class Tipo_class = 2 per interaction_class Per Nome_Class e Attrib1 cfr.specifiche FOM |
||
| SYNCRO
- 1 di 2
SYNCRO - 2 di 2 |
"RegisterSynchronizationPoint, pointer, ReadyToStart, fed1, fed2,...,fedn" | "ExecValue, Command, Message" | un istanza della classe Manager Federates gestisce lato RTI la lista dei federati richiesti per l'attivazione della simulazione |
| "string, integer, string, string, ..., string | "integer, string , string" | ||
| --- | "-1, RegisterSynchronizationPoint,
Error Code" execution failed
"0, RegisterSynchronizationPoint " otherwise |
||
| "SynchronizationPointAchieved, pointer, ReadyToStart" | "ExecValue, Command, Message" | ||
| "string, integer, string" | "integer, string , string" | ||
| --- | "-1, SynchronizationPointAchieved,
Error Code" execution failed
"0, SynchronizationPointAchieved " otherwise |
||
| PUBLISH AND SUBSCRIBRE | "PublishAndSubscribe, pointer " | "ExecValue, Command, Message" | |
| "string, integer " | " integer, string" | ||
| UPDATE | "Update, pointer, stato_object, federate_time, nome_class, nome_object, attrib1, " | "ExecOK, Message" | |
| "string, integer,
integer, string, string, tipo_attrib1,
"
Per tipo_attrib1 cfr. specifiche FOM + estensione riportata in doc corrente |
"integer, string" | ||
| Pointer è
il valore di ritorno in interazione CREATE
Stato_object =0 Or 1 Or 2 Or 3 (se riga da cambiare Or modificata Or nuova Or eliminata) Per Nome_Class, Nome_object e attrib* cfr. specifiche FOM + estensione riportata in doc corrente |
"-1, Error
Code" execution failed
"0" otherwise |
||
| TAR | "TimeAdvanceRequest, pointer, requested_time" | "ExecValue, Command, TimeGranted, Message" | Il requested_time è il fine giorno successivo a cui il simulatore chiede di avanzare |
| "string, integer, double" | "integer, string, double, string" | ||
| "-1, TimeAdvanceRequest,
45.2, Error Code" execution failed
"0, TimeAdvanceRequest, 45.2" otherwise |
Il TimeGranted è il fine giorno successivo a cui il simulatore può avanzare: è string da convertire in double | ||
| INITIALIZE SOM | "InitialzeSOM, pointer, " | "ExecValue, Command, Message" | |
| "integer, string" | |||
| SENDINTERACTION | "SendInteraction, pointer, fdtime,nomemessaggio, nome_object,attrib1, " | "ExecValue, Command, Message" | |
| "string, integer,
double, string, string, tipo_attrib1,
"
Per tipo_attrib1 cfr. specifiche FOM + estensione riportata in doc corrente |
"integer, string" | ||
| CHECKUPDATED | "CheckUpdated, pointer " | " ExecValue, Command, Message" | |
| "string, integer" | "integer, string" | ||
| "-1, CheckUpdated,
Error Code" execution failed
"0, CheckUpdated, t, stato_object, nome_class, nome_object, attrib1, value, ... " otherwise |
t: 2 object
1 interaction, 0 fine update
stato_object: 1 ,2, ,3 Per Nome_Class, Nome_object e attrib* cfr. specifiche FOM + estensione riportata in doc corrente |
||
| OWNERSHIPDIVESTITURE | "OwnershipDiv, pointer,nome_object " | " ExecValue, Command " | Cede "incondizionatamente" la proprietà delloggetto |
| "string, integer" | "integer, string" | ||
| "-1, OwnershipDiv,
Error Code" execution failed
"0, OwnershipDiv" otherwise |
|||
| OWNERSHIPACQUISITION | "OwnershipAcq, pointer,nome_object " | " ExecValue, Command " | Acquista la proprietà delloggetto |
| "string, integer" | "integer, string" | ||
| "-1, OwnershipAcq,
Error Code" execution failed
"0, OwnershipAcq" otherwise |
| QUERYLBTS | "QueryLBTS,pointer " | " ExecValue, Command, ",",LBTS" | Serve a richiamare LBTS della federazione |
| "string, integer" | "integer, string,",",double" | ||
| "-1, QueryLBTS,
Error Code" execution failed
"0, QueryLBTS " otherwise |
|||
| FILTER | "Filter,pointer,federate_name " | " ExecValue, Command " | Inizializza
la filtrazione dei messaggi in base a federate_name;
se federate_name è = " * " riesco a vedere tutti i messaggi della federazione |
| "string, integre,string" | "integer, string " | ||
| "-1, Filter,
Error Code" execution failed
"0, Filter" otherwise |
|||
| INIPW | "Inipw,str_pw " | " ExecValue, Command " | Inizializza la crittazione |
| "string, string" | "integer, string " | ||
| " | "-1, Inipw,
Error Code" execution failed
"0, Inipw " otherwise |
||
| TICK | "Tick, Tmax, Tmin" | "ExecValue, Command, Message" |
DIG, Milano
Non essendo il simulatore SIMPLE++ sviluppato HLA compliant, è stato, necessario rendere lambiente di simulazione compliant alle specifiche HLA sviluppando linterfaccia necessaria; tale processo di linking è stato eseguito, per lappunto, con la scrittura di un programma in Java, funzionante da proxy dei servizi HLA connesso allambiente di simulazione attraverso dei socket di interscambio messaggi.
Un codice modulare è la chiave per costruire una struttura flessibile che massimizza linteroperabilità. Ogni modulo deve svolgere una ben definita funzione. In questo modo cambiamenti sullo specifico modulo non influiscono sul resto del codice. Questa concezione modulare è stata perseguita nellimplementazione dellinterfaccia, sia dalla parte del simulatore che del programma proxy.
Il federato SIMPLE++ interagisce con la federazione di simulazione mediante servizi RTI e metodi di specializzazione dei servizi RTI codificati in codice Java. I servizi di interazione vengono eseguiti in Java code:
Il Java code decodifica il messaggio ricevuto per attivare la funzione da eseguire; ovvero, interpreta il codice messaggio per attivare la corrispondente funzione, quindi trasmette alla funzione attivata gli argomenti trasportati dal messaggio;
Il Java code esegue la funzione (laddove necessario, con la chiamata di servizi RTI, importati da libRTI); ritorna, quindi, un messaggio con appropriati argomenti, come risultato dell'esecuzione della funzione.
I messaggi di attivazione dei servizi (con i relativi argomenti richiesti) e i risultati dei servizi (ritorni) vengono inviati/ricevuti dal federato SIMPLE++ a mezzo di oggetti socket (oggetti SIMPLE++ di interfaccia per connessione TCP/IP su socket hardware).
Il messaggio IN/OUT attraverso socket è una stringa con un codice messaggio e un insieme di argomenti trasportati dal messaggio. Il federato SIMPLE++ provvede quindi a gestire l'invio e la ricezione dei messaggi attraverso i propri socket: ovvero, chiama l'esecuzione di servizi con un messaggio in OUT e attende ritorni per modificare il proprio stato interno da messaggi in IN. Il modello di interazione è rappresentato dall'architettura di figura seguente.
Dal lato del simulatore, esso è stato da subito concepito con la medesima struttura modulare, realizzando una architettura a doppio Frame, uno deputato allinterfacciamento con HLA ed uno delegato allinserimento del modello del federato. Questa modalità è stata perseguita nellottica delle successive fasi del progetto corrente, dove e stato necessario aggiungere maggiori livelli di dettaglio al modello della realtà aziendale. In questa logica, modulare, cosiddetta a "morsetti", basterà sostituire il frame contenente il modello del federato, senza la necessità di dover riscrivere i metodi che si occupano dellinterfacciamento a HLA. Dovendo rendere SIMPLE++ HLA compliant si è deciso di creare unarchitettura di interfacciamento la più generale possibile, e non legata al case study in questione.
Nellimmagine riportata, rappresentate il frame
principale sviluppato in SIMPLE++, si distinguono chiaramente i due morsetti
del simulatore: linterfaccia con HLA in IO_Management ed il modello
di simulazione in Plyform (azienda modellizzata da Milano nella
ricerca).
Allinterno del frame di interfaccia IO_management si distinguono tutti i metodi (funzioni) ed oggetti necessari alla comunicazione con il Java code. Per come è stata implementata la federazione, a time stepped, la comunicazione con il Java, e quindi con RTI, è stabilita dal simulatore soltanto a dati passi temporali di simulazione. Sono stati eseguiti esperimenti di federazioni con passo giornaliero o settimanale di comunicazione.
Nel frame si distinguono chiaramente loggetto socket, che rappresenta il socket hardware di comunicazione, ed una serie di sottoframe responsabili della gestione di tutti i messaggi in input ed output (gestione_socket) e delle chiamate (funzioni_rti, evidenziato).
Frame di interfaccia SIMPLE++ - Java
Sperimentazione Preliminare
DIMEG, Bari
In occasione del meeting del 3 e 4 aprile 2001, svoltosi presso la sede del Dipartimento di Ingegneria Meccanica e Gestionale (DIMEG) del Politecnico di Bari, sono stati testati i simulatori delle sedi di Bari (Sub Contractor di primo livello) e Genova (Main Contractor e Sub Contractor di secondo livello) interagenti nellambito di una federazione HLA. In particolare è stata testata lintegrazione del federato general-purpose HLA compliant (sviluppato dalla sede di Genova) e del simulatore ARENA (realizzato dalla sede di Bari) mediante lutilizzo di sockets in ambiente VBA. Tali test sono stati condotti sia in "locale" su calcolatori opportunamente predisposti ed operanti sulla rete intranet del DIMEG sia in remoto tra le sedi di Bari e di Genova su rete Internet.
In luglio si è testato la federazione di simulatori completa ed operante in maniera distribuita presso tutte le sedi.
DE, LAquila
La sede dellAquila, prima di iniziare la progettazione e quindi limplementazione della shell di simulazione relativa alle specifiche finali riguardante una supply chain complessa nellambito dellindustria aeronautica è stata verificata la compatibilità tra lambiente HLA ed una serie di simulatori distribuiti sviluppati autonomamente dalle varie sedi partecipanti alla ricerca. Tale verifica è stata eseguita facendo riferimento al caso di studio ipotetico di una azienda dedita allassemblaggio di Personal Computer che si avvale della collaborazione di quattro sub fornitori di primo livello e due sub fornitori di secondo livello come illustrato nella figura seguente. Il prodotto finito è offerto al cliente finale in 72 configurazioni, che derivano direttamente dallabbinamento delle diverse tipologie di componenti.
A ciascun partecipante alla ricerca è stato associato un fornitore o subfornitore ed affidato lincarico di sviluppare il modello di simulazione corrispondente avendo preliminarmente definito le specifiche comuni di comunicazione (tipo e formato dati, modalità gestione sincronizzazione ed avanzamento temporale ecc). La sede di LAquila ha sviluppato il simulatore relativo al produttore del componente Hard Disk.
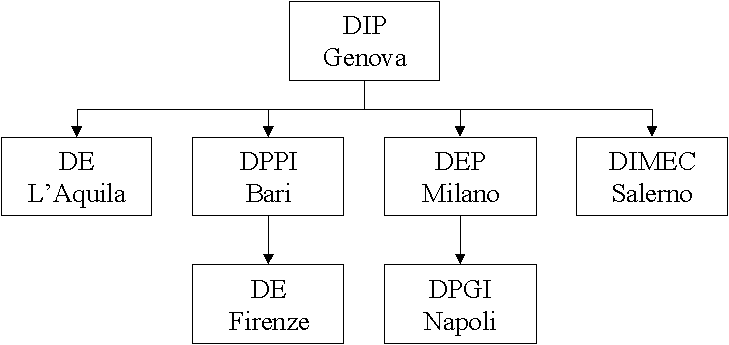
Le classi di oggetti previste sono state tre: Piano di produzione, Ordine di acquisto, Produzione eseguita. E stata inoltre prevista la possibilità di inviare messaggi (Accettazione Ordine e Sollecito Consegna) tra i vari simulatori, con un codice identificativo del destinatario. Operativamente lemissione di ordini di acquisto da parte del main contractor si riflette nella successiva emissione di ordini di acquisto ai livelli inferiori della catena logistica e nella emissione di conferme di produzione eseguita generando il processo iterativo di scambio di informazioni tra simulatori.
La gestione del tempo è stata prevista necessariamente ad eventi discreti con ogni federato strettamente conservativo (Time Regulating e Time Constrained).
Lavanzamento del tempo è stato definito con passo temporale fisso di un giorno, con evento di sincronizzazione alle ore 00.00 di ciascun giorno.
Nel gennaio 2001 si è proceduto con successo alla
verifica di tale struttura mediante integrazione di più simulatori
in rete locale avvenuta presso la sede di Genova, in particolare dimostrando
la sincronizzazione con il main contractor, la corretta scoperta delle
pubblicazioni/sottoscrizioni, e la corretta gestione dellavanzamento temporale.
DIG, Milano
Presso la sede Milanese la sperimentazione della federazione HLA, prima di essere eseguita di concerto con lintera federazione creata tra tutte le sedi coinvolte nella ricerca, è stata innanzitutto eseguita di concerto con luniversità di Firenze. La collaborazione tra i due atenei è stata approfondita e continua, dettata della necessità di impiegare il medesimo simulatore commerciale SIMPLE++.
In particolare, lo sforzo che ha coinvolto non poco tempo delle due sedi è stato concentrato sulla creazione di un sistema con il quale rendere lambiente di simulazione integrato allo standard HLA.
Nella ricerca di quale sistema adottare per rendere SIMPLE++ connettibile con HLA è stata condotta una prima sperimentazione nel quale si è tentato di creare una connessione tra RTI e SIMPLE++ ricorrendo alla stesura di librerie dinamiche redatte in C++. Questa sperimentazione non ha dato esiti positivi, probabilmente inficiata da instabilità presenti nel software RTI (NG 1.7) in dotazione, ripreso dal sito del DMSO.
A tale fase di insuccesso sono seguiti i primi esperimenti positivi, eseguiti come verifica della comunicabilità che si può realizzare tra due processi SIMPLE++ separati tramite la connessione eseguibile su porte socket. Da questi esperimenti si è conclusa la modalità successivamente adottata per realizzare il proxy di connessione ad HLA.
Lintegrazione SIMPLE++ HLA è stata alla fine realizzata ricorrendo ad un programma proxy redatto in Java, illustrato nei prossimi capitoli.
Una volta che il simulatore scelto da entrambe le università
è stato reso stabilmente HLA compliant, si è proceduto
allesecuzione di diversi test di verifica e validazione. Tale fase è
stata eseguita in primo approccio ricorrendo ad un emulatore di messaggi
scritto in Visual Basic e quindi, in seguito, è stata instanziata
una micro federazione tra i soli simulatori costruiti da Milano e Firenze,
eseguita in modalità distribuita su rete WAN.
Costruzione Sim/Sched di Diverse Realta` Industriali:
Piaggio AeroIndustries, OMA, Geven, Magnaghi, Plyform, Salver, Sirio Panel
DIP, Genova
Come già accennato nellambito del programma di ricerca teso ad implementare un modello di simulazione/schedulazione distribuito per una supply chain complessa si è scelto di fare riferimento al caso della Piaggio Aeronautica. Successivamente alla fase di analisi e sviluppo della soluzione proposta, i modelli di simulazione sono stati inseriti nella federazione creata con tutti gli altri enti comprendenti le aziende Piaggio (quale Main Contractor), OMA, Geven, Magnaghi, Plyform, Salver, Sirio Panel, direttamente coinvolte nella dimostrazione, oltre a soggetti, analoghi a CGF (Computer Generated Forces), rappresentativi di fornitori di secondo livello (i.e. Piaggio Kit) o altre realtà (i.e. P&W); ovviamente nel seguito tutti i valori riportati riferiti alle diverse aziende coinvolte sono stati alterati per garantire la riservatezza delle informazioni.
Il simulatore GG Piaggio rappresenta lintero impianto della Piaggio AeroIndustries S.p.a., presente a Genova Sestri , per quanto riguarda la linea di produzione del P180.
La produzione del P180 coinvolge gli stabilimenti Piaggio di Finale Ligure e Sestri Ponente. Il processo produttivo di singoli componenti avviene a Finale Ligure mentre lassemblaggio definitivo del velivolo termina a Genova Sestri.
Il P180 risulta essere composto da circa 25000 part number, di cui il 50% viene prodotto interamente a Finale mentre unaltra grande parte, corrispondente a circa il 45% di tutti i part number, viene acquistata dallesterno.
Ovviamente un così gran numero di pezzi acquistati allesterno equivale ad un gran numero di fornitori, che per Piaggio risultano essere sia italiani sia esteri. Da ciò deriva un problema di non lieve importanza, ovvero il problema della gestione dei pezzi/flusso di informazioni relativi alla supply chain dellazienda.
Le caratteristiche complesse dei fornitori di tale azienda sono state il motivo per cui la Piaggio è risultata idonea a diventare il case studied del progetto. Infatti la Piaggio AeroIndustries S.p.a. è risultata la scelta migliore per lo sviluppo di uno step davanzamento, dal momento che è risultata ottima la localizzazione geografica dei sub fornitori dellazienda, rispetto ai diverso partner universitari partecipanti al progetto stesso.
Le sue funzioni allinterno della federazione sono particolari, in quanto Main Contractor esso ha il compito di sincronizzare la federazione aspettando tutti i federati che sono necessari per il suo processo produttivo.
Piaggio produce attualmente quasi tutte le parti del P180 escluse quelle in materiale composito. Tra i principali elementi che terziarizza si hanno lo stabilizzatore, fatto dalla Salver, gli equilibratori posteriori, e i pannelli copri motori. Il processo produttivo risulta abbastanza complicato, esso si divide sostanzialmente in 6 macro fasi di lavorazione.
Le prime si svolgono in parallelo e sono la lavorazione della fusoliera (il corpo centrale), del bagagliaio, delle ali e della cabina piloti. Queste fasi si svolgono sostanzialmente in un unico capannone su 4 linee di produzione separate.
Una volta completate queste lavorazioni si passa allassemblaggio delle parti principali (Stazione 8), questa fase è una delle fasi fondamentali per la vita dellaereo, è qui che inizia a prendere corpo il P180. La Stazione 8 di fatto è una serie di cavalletti sui quali si posizionano le ali, il tronco centrale, la coda e la cabina piloti. Una volta posizionati questi cavalletti vengono fatti combaciare e le parti vengono assemblate per formare quello che è il primo abbozzo del velivolo.
Questa fase avviene in un capannone separato e da qui in avanti il P180 si muoverà su carrelli allinterno di questo capannone. Successivamente vengono finite le lavorazioni degli interni, vengono assemblati i motori, il carrello e la strumentazione. Le ultime due fasi si effettuano in capannoni separati e sono la verniciatura e le prove di volo. Allinterno di queste macro fasi si hanno una serie di lavorazioni intermedie, chiamate stazioni. Le stazioni complessivamente sono circa 50, al loro interno si hanno per ciascuna una serie di job a formare in tutto circa 230 fasi.
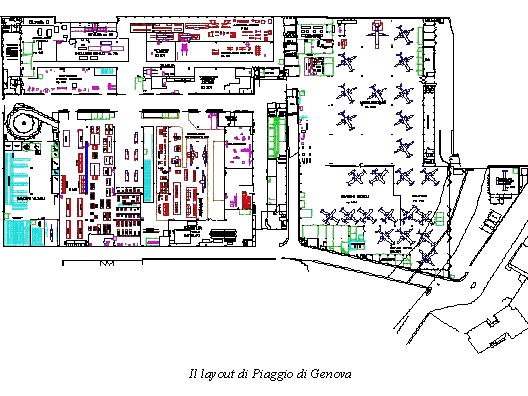
Dettagli della Produzione
Come già accennato, per ragioni di riservatezza nel seguito del documento tutti i valori quantitativi legati alla produzione del P180 sono stati alterati mantenendone comunque la coerenza intrinseca.
Il P180 è il prodotto di punta della Piaggio AeroIndustries. Il piano di produzione per i prossimi tre anni prevede un incremento di produzione fino alla realizzazione di 3 velivoli al mese. Questo incremento sarà graduale infatti nellanno in corso verranno prodotti da giugno a novembre 10 velivoli complessivi.
| Velivolo | Consegna Linea Volo |
| 510502 | 18/07/2011 |
| 610513 | 04/08/2011 |
| 610526 | 20/09/2011 |
| 510535 | 28/10/2011 |
| 510544 | 13/11/2011 |
| 610553 | 27/12/2011 |
| 610562 | 11/10/2012 |
| 610572 | 25/10/2012 |
| 610581 | 09/11/2012 |
| 510591 | 23/12/2012 |
Le date riportate in tabella sono relative alla consegna dei velivoli alla linea volo cioè prima della fase di collaudo, prevista a Sestri Ponente.
Analisi Distinta Base del P180
E stata considerata la Distinta Base, ricavata dal Sistema Informativo Aziendale e riportata su foglio elettronico Excel e relativa al velivolo 1058. In tale documento figurano, oltre al numero identificatore di ciascun part number e la relativa denominazione, i dati, più interessanti, per lanalisi dei tempi relativi ai cicli tecnologici di produzione:
Livello: compreso tra 1 e 14. Il livello 1 identifica lassieme finale, che viene assemblato a Sestri Ponente. I livelli superiori identificano i vari sottoassiemi.
Quantità: indica la quantità di part number assemblati in un velivolo.
TC: classifica il part number secondo il seguente criterio:
Materiale grezzo;
Materiale lavorato conto terzi cui Piaggio fornisce anche lattrezzatura;
Parti dacquisto;
Parti interamente prodotte da Piaggio.
Val1: indica da quale velivolo è iniziato lutilizzo del part number considerato.
Val2: indica fino a quale velivolo è stato o verrà utilizzato il part number.
PR: indica la provenienza del part number: -Fin -> Finale Ligure -Gen -> Genova
DE: indica il reparto prevalente di produzione (es.: LL= reparto formatura lamiere; CN= reparto macchine a controllo numerico).
LT: lead time.
ANT: indica quanti giorni prima della data di consegna deve essere lanciato in produzione il part number.
Nella precedente tabella è riportato un estratto della Distinta Base del velivolo 610581, dove sono rappresentati in verde i macroassiemi di assemblaggio:
Macroassiemi di Assemblaggio di Livello 2
In totale si hanno 32 macroassiemi di livello 2, tra cui vi sono le 17 stazioni di assemblaggio del P180. Di queste 17 stazioni, dodici hanno lo scalo in cui vengono assemblati tutti i particolari relativi alla stazione stessa, mentre gli altri cinque sono "senza scalo". Le stazioni con lo scalo sono quelle più critiche, in quanto occorre il completamento di tutte le operazioni relative alla stazione stessa prima di potere passare a quella successiva.
Le stazioni 4, 5, 6, 7, 8b sono quelle senza scalo e sono quelle più prossime alla consegna del velivolo completato. In queste stazioni si ha una maggiore libertà sulla sequenza delle operazioni di assemblaggio.
Occorrerà verificare quali variabili risultano essere più importanti e quali meno.
I macroassiemi riportati in azzurro sono sottoassiemi delle stazioni delle ali (STAZ15). In particolare, quelli aventi numero pari vanno assemblati nella stazione 80STAZ15ALADS, mentre quelli aventi numero dispari nella stazione 80STAZ15ALASN (rispettivamente ala destra e sinistra).
Il processo di assemblaggio e le operazioni delle 17 stazioni dovranno essere studiate ed analizzate più in dettaglio nello stabilimento di Sestri Ponente per potere disporre dei dati necessari al proseguimento del progetto (es.: risorse, tempi, metodi, ecc.).
Il part number 80BA0001-809, ovvero il P180 completato, viene visto come un assieme di livello 1, e richiede 92 giorni per il suo completamento, pertanto tutti i sottoassiemi di livello 2 dovranno essere disponibili 92 giorni prima della prevista realizzazione del velivolo.
Alcune stazioni non presentano lead time. Questo potrebbe essere dovuto al fatto che tali stazioni vengono considerate completate una volta che siano stati assemblati tutti i suoi sottoassiemi, oppure perché queste vengono semplicemente considerate come stazioni logiche.
Questo andrà verificato.
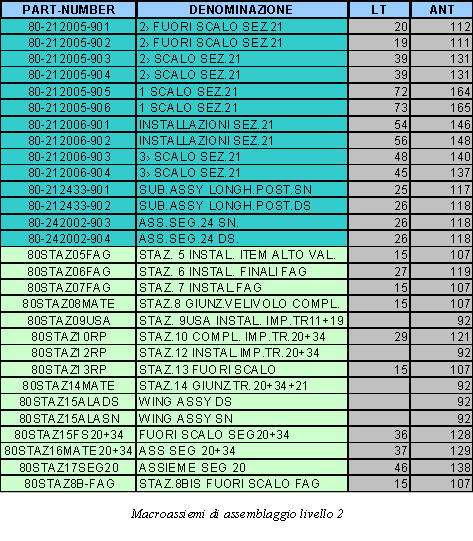
Le altre stazioni hanno invece un lead time compreso tra 15 e 46 giorni. Naturalmente, i part number relativi alle stazioni aventi lead time maggiore dovranno essere disponibili prima dei part number relativi alle stazioni aventi lead time minore.
Le stazioni 80STAZ15ALADS (ala destra) e 80STAZ15ALASN (ala sinistra) richiedono una maggiore attenzione sia in fase di assemblaggio che in fase di produzione, perché presentano macroassiemi di livello 2 che verranno assemblati con lala. Anche questo punto sarà verificato e approfondito nel seguito.
Macroassiemi di assemblaggio di livello 3
In totale si hanno 1003 sottoassiemi di livello 3, che sono riportati nel file livelli3.xls. Questo file è costituito da 17 fogli elettronici, ciascuno dei quali rappresenta una stazione di assemblaggio. Per ogni stazione sono elencati i relativi part number.
Le stazioni aventi un maggiore numero di sottoassiemi di livello 3 risultano essere 80STAZ15ALADS (ala destra), 80STAZ15ALASN (ala sinistra), 80STAZ16MATE20+34 (tronco centrale + bagagliaio + ali).
Si riporta, ad esempio, il foglio relativo alla stazione 80STAZ05FAG, avente solamente 7 sottoassiemi di livello 3.
Come si vede dal grafico, la maggior parte dei part number viene prodotta interamente da Piaggio (TC3), e unaltra grande parte viene acquistata dallesterno(TC2). Sono invece pochi i materiali grezzi (TC0) e quelli lavorati conto terzi (TC1).
A fronte del previsto aumento della produzione, si sta verificando un carico di lavoro eccessivo nelle linee di produzione, pertanto si sta pensando di aumentare notevolmente il numero di part number di tipo TC1, riducendo la quantità di part number di tipo TC3.
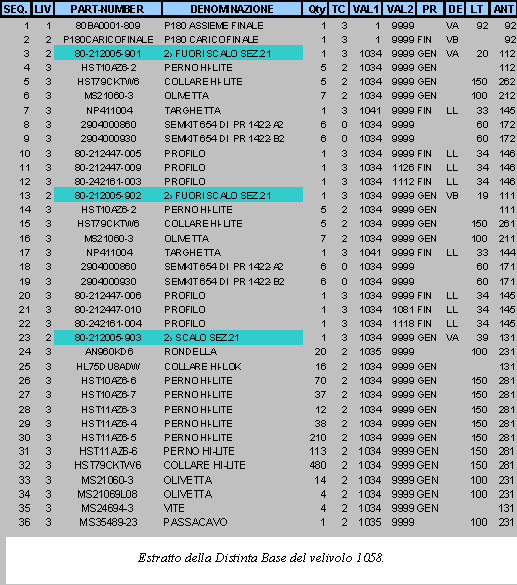
Il Modello di Simulazione
Il ciclo di simulazione di GG si riassume in 4 fasi :
ordini letti da un file (generalmente ordini di clienti diversi da quelli presenti nella federazione di HLA) o ordini inviati dall RTI per il federato in questione, nel caso di PIAGGIO non essendoci livelli superiori della catena di fornitori questa opzione di ricezione ordini è di fatto inutile.
Descrizione del Simulatore
La struttura dati della simulazione consiste in 5 Hashtable: Magazzino. Lista Ordini, ListaOrdiniOut, ListaPF, ListaRisorse.
Magazzino : caricata allinizio dal file Magazzino.txt (Default) e modificata ad ogni inizio di lavorazione contiene tutti gli elementi ("Item") presenti a magazzino con key il nome dellelemento.
ListaOrdini : caricata allinizio dal file Ordini.txt (Default) contiene tutti gli ordini non ancora finiti del processo, gli ordini sono inseriti con key lId dellordine.
ListaOrdiniOut : viene creata durante la simulazione, contiene tutte le richieste di pezzi in uscita dallo stabilimento.
ListaPF : contiene tutti gli ordini in stato "Finito" viene creata e aggiornata durante la simulazione.
ListaRisorse : caricata allinizio di simulazione dal file Risorse.txt (Default) e mai più aggiornata, contiene la lista delle risorse disponibili al sistema produttivo.
Le prime quattro liste vengono ad ogni ciclo passate alla classe che gestisce le comunicazioni con RTI in modo da poter scorrere la lista degli ordini in uscita (per inviare ordini agli altri federati), aggiungere ordini alla ListaOrdini aggiornare la lista Magazzino in caso di arrivo di prodotti finiti, ed eventualmente inviare prodotti finiti.
Al primo ciclo di simulazione vengono riempite le Hashtable del magazzino, degli ordini e delle risorse.
Leggendo dal file Ordini.txt si possono leggere gli ordini rappresentati con: Codice Ordine, Nome dellordine, Data di consegna.
Alla lettura di ciascun ordine viene creato un oggetto "Order" con i campi: Nome, Id, DataConsegna. Questo Ordine viene automaticamente messo in stato "preDormiente". Gli stati disponibili per ciascun ordine sono "preDormiente", "Dormiente", "Attivo", "Finito".
Analogamente per la ListaRisorse ed il Magazzino: si legge dal file il nome risorsa, il numero, lindisponibilità (predisposizione della risorsa a guastarsi) e si creano tanti oggetti "Resource" quanto il numero indicato con campi Nome e indisponibilità. Tali risorse verranno inizialmente messe nello stato "Libera". Gli stati disponibili per ciascuna risorsa sono "Libera", "Occupata", "Guasta".
Leggendo dal file Magazzino.txt si ottengono nome e numero dei pezzi presenti, si crea unistanza "Item" per ogni pezzo che conterrà Nome del pezzo e Quantità presente allo stato zero. Si processano a questo punto anche gli ordini provenienti dal file Forecast.txt, essi rappresentano ordini che potrebbero verificarsi, perciò leggendo dalla probabilità di accadimento tramite estrazione di numero random, si decide se creare lordine letto o meno. In modo del tutto analogo si processano anche gli ordini gia in lavorazione letto dal file WorkInProcess.txt. Tali ordini vengono creati e messi in stato attivo allinizio della simulazione. Per sapere quale fase di lavorazione si sta svolgendo si legge la data di fine prevista di ciascuna fase dal file, si confronta con la data odierna. Se la data di inizio simulazione è maggiore della data letta dal file, allora la fase sarà in stato "Finito", altrimenti la fase potrebbe essere in lavorazione o ancora da attivare, quindi se la differenza tra la data attuale e la data di fine fase è maggiore della durata della fase stessa allora la fase è ancora da attivare.
Il caricamento di un ordine (qualsiasi esso sia) prevede la creazione immediata delle "Fasi" di lavorazione. Ciascuna fase ha una durata diversa dalle altre, lista di predecessori, settimana di inizio ed utilizza risorse e componenti specifici. Tali dati vengono letti dal file FasiDiLavorazione.txt
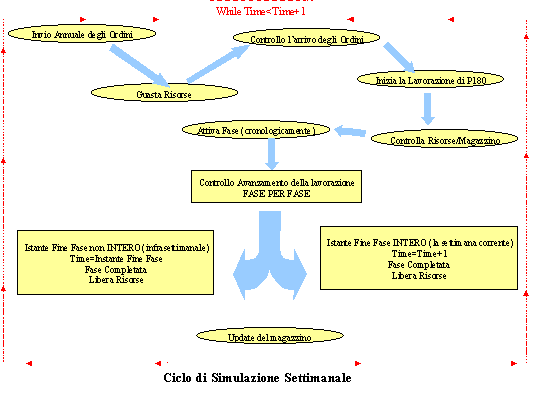
Loggetto "fase" contiene al suo interno tre Hashtable, una per gli "Item" (osia pezzi a magazzino) utilizzati una per le risorse ed una per i predecessori. La durata viene calcolata mediante estrazione da una Gaussiana di cui volta per volta si n fornisce media e scarto quadratico.
Ciclo per ciclo, una routine provvede a sfogliare tutte le risorse presenti nel sistema, ad estrarre un numero random e, in funzione alla loro indisponibilità, a mettere tali risorse in stato di "Guasto".
Inoltre vengono creati gli ordini dei semilavorati per le lavorazioni che si effettueranno allinterno dellanno successivo a quello in corso. La routine di creazione di ordini in uscita dal sistema controlla prima tra la ListaOrdiniOut se un ordine per la stessa lavorazione (confrontando il codice ordine) sia già stato inviato, poi procede al backward scheduling per fissare la data di prevista consegna degli ordini in funzione delle diverse fasi di lavorazione, prendendo come anticipo la "SicurezzaOrdini" .
Si procede anche a controllare se tra gli ordini in uscita inviati qualcuno è stato "cosegnato". Tale controllo si basa esclusivamente sulla data di prevista consegna dellordine: alla sua creazione si provvede ad estrarre un numero dalla gaussiana con media la settimana di prevista consegna e come sigma la somma tra SigmaSistematico dei fornitori e Sigma del fornitore stesso. Il numero ottenuto sarà leffettiva settimana di consegna del semilavorato. Settimana per settimana questa data viene confrontata con il tempo attuale, se è maggiore o uguale allora lordine viene consegnato effettivamente, cioè viene eliminato dalla ListaOrdiniOut, e il prodotto viene inserito nel magazzino.
Discorso a parte sono gli ordini con fornitore compreso tra quelli simulati con HLA. Se il fornitore è uno dei federati allora il simulatore provvederà a trasformare lOrdine da simulare in un oggetto HLAOrdine in modo tale da inviarlo allintera federazione. Il fornitore distribuito provvederà a ricevere e processare tale ordine. Finita la lavorazione il sub fornitore emette un HLAPF (oggetto della nostra federazione che rappresenta il prodotto finito) che avrà come ID quello dellordine di partenza. Il simulatore GG Piaggio raccoglierà questo prodotto finito e inserirà il codice a magazzino.
Lo step successivo è quello di controllare gli ordini caricati allinterno della "ListaOrdini" che si trovano ancora in stato "preDormiente". Se listante attuale meno la data di consegna differiscono di 46 settimane (tempo necessario per produrre un P180) più una "SicurezzaProduzione" (che rappresenta il numero di settimane di anticipo cautelativo per I iniziare il processo di un ordine) lordine viene messo in stato "Dormiente" e viene aggiornato il frame di interfaccia aggiungendo un aereo rosso.
Viene sfogliata nuovamente la ListaOrdini cercando solo tra gli ordini "Dormienti" si trova il primo in ordine cronologico da consegnare e se sono verificati i vincoli sulle Risorse e sugli Item presenti a magazzino si attiva la prima fase di lavorazione possibile effettuando sia il decremento del magazzino per gli Item usati sia loccupazione delle risorse utilizzate sia laggiornamento del frame di interfaccia aggiungendo un aereo giallo (ordine in stato "Attivo").
Poiché potrebbero esserci più ordini da consegnare nella stessa settimana il ciclo precedente viene ripetuto tante volte quando sono gli ordini presenti.
Una volta attivati gli ordini necessari GG controlla tra gli ordini caricati lo stato di avanzamento. In particolare ordine per ordine, fase per fase si fa un confronto tra listante di attivazione della fase e listante attuale: se tale differenza è maggiore del tempo di lavorazione della fase allora la fase viene messa in stato "Finito". Si aggiornano i dati relativi alle risorse e si effettua un controllo sulle fasi relativa allordine che si sta processando: avendo completato una fase si potrebbe passare allattivazione della fase successiva.
Un ultimo controllo verifica se qualche ordine si trova con tutte le fasi in stato "Finito", se ciò accade lordine viene considerato completato, si procede quindi alleliminazione dellordine dalla lista ordini e al suo inserimento nella lista prodotti finiti.
DEF, Firenze
Lanalisi dei processi produttivi del fornitore associato
allunità operativa di Firenze (Sirio Panel, SP) ha portato ad identificare
nel Control Panel (CP) il prodotto più rappresentativo della realtà
aziendale in questione. Il prodotto è caratterizzato da una distinta
base (DB) mediamente composta da sei livelli. Si è dunque reso necessario
analizzare e codificare le numerose referenze presenti nelle distinte di
produzione, e dopo le doverose semplificazioni, la DB è stata ridotta
a 3 livelli, dove i codici di ciascun livello rappresentano nello specifico
i principali gruppi di fabbricazione e/o di acquisto.
La successiva analisi delle tecnologie di fabbricazione
e del processo produttivo ha portato ad identificare quattro principali
reparti di lavorazione:
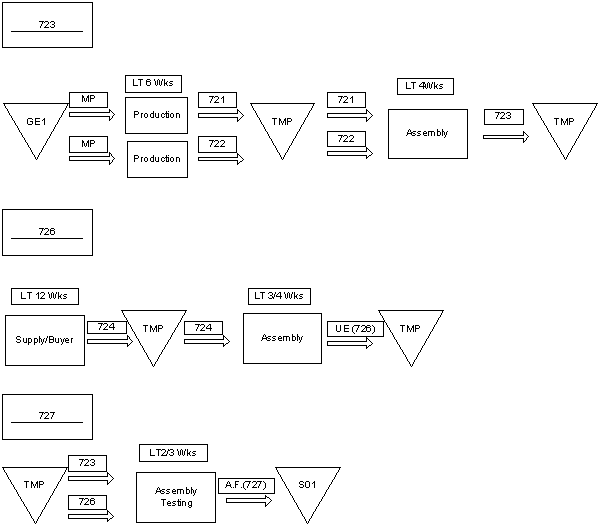
Processo semplificato di fabbricazione di un control panel.
Dalla flowchart è possibile notare che i codici che costituiscono input ai flussi rappresentati possono derivare da picking di magazzino, e in tal caso si tratta di codici gestiti a riordino, piuttosto che di codici espressamente ordinati a fabbisogno (come ad esempio, la componentisca che va a costituire lunità elettronica del pannello di controllo, specifici in numero e tipologia per ciascuna commessa).
La modellazione del sistema produttivo così descritto, in ambito SiMPLE++ 7.0, ha chiaramente richiesto la formalizzazione delle procedure impiegate in SP (Sirio Panel) per la gestione degli Shop Order internamente ai reparti di fabbricazione ed assemblaggio. La logica prevede la generazione degli ordini di lavorazione a partire dallesplosione della distinta, tempificando il lancio in produzione nei singoli reparti degli item che fanno parte della commessa sotto programmazione. In assenza di strumenti più raffinati per lottimizzazione della produzione, il modello sviluppato è stato caratterizzato da uno schedulatore/pianificatore che rappresenta al meglio il comportamento del programmer di SP, che utilizza il modulo MRP del gestionale BAAN IV. La struttura è stata poi predisposta per interagire con linterfaccia Java, funzionante da proxy dei servizi HLA.
DIMEC, Salerno
La Geven S.r.l. di San Sebastiano al Vesuvio (NA), presente sul mercato da circa 15 anni, si occupa essenzialmente della realizzazione di tre categorie di prodotti:
1. poltrone per impiego navale
2. poltrone per impiego aeronautico
3. poltrone per impiego ferroviario.
Tralasciando queste ultime, data la trascurabile incidenza sul fatturato, si devono subito evidenziare alcune notevoli differenze tra le prime due tipologie, differenze legate principalmente ai requisiti tecnico-qualitativi cui devono rispondere, ben più elevati nel campo aeronautico, dove sono previsti controlli da parte degli organismi preposti sulla base di specifiche norme (JAR21, JAR145) ed è necessario eseguire tutta una serie di prove e collaudi secondo le modalità prescritte, producendo adeguata documentazione che comprovi "laeronavigabilità" del prodotto. Tali differenze si traducono sia sotto laspetto strettamente produttivo, che sotto il profilo della gestione degli ordini dei clienti.
Le poltrone di tipo aeronautico vengono distinte, in base alle caratteristiche costruttive, in poltrone di tipo 16 G e di tipo 9 G. Le prime rispettano dei requisiti normativi legati a standard di sicurezza più elevati.
I mobili o interiors sono prodotti per clienti aeronautici e sono allestimenti interni per aeromobili (mobiletti, armadi, ecc).
Gli accessori sono prodotti per clienti aeronautici, navali e ferroviari come parti sciolte e ricambi per poltrone già realizzate.
La produzione delle poltrone
Senza voler entrare nel dettaglio, si può dire che le parti componenti una generica poltrona sono prodotte per la maggior parte allinterno; solo alcune sono dacquisto, come ad esempio le parti elettriche.
Il processo produttivo consiste in una prima fase di fabbricazione di tutti i componenti che giungono, infine, alla fase di assemblaggio.
Il flusso dei materiali risulta piuttosto caotico e prevede lattraversamento di più reparti, alcuni dei quali anche più volte nel corso dello stesso ciclo.
I reparti di produzione attraverso cui fluiscono i materiali si possono individuare in:
01 OFFICINA MECCANICA OF.M.
02 TERMOFORMATURA TF
03 CARPENTERIA CA
04 INIEZIONE POLIURETANO IN.PO.
05 STAMPAGGIO SCHIUMATI ST.SC.
06 TAPPEZZERIA TAP
07 CUCITURA CUCI
08 LAVORAZIONI ESTERNE LAV.E.
09 MONTAGGIO MON.
Per quanto riguarda il prodotto aeronautico il reparto ST.SC. si occupa SOLO di applicare delle strisce di velcro sulla struttura metallica e sugli schiumati, che sono approvvigionati allesterno in quanto lazienda non ha la tecnologia adatta per questo tipo di lavorazione. Per le poltrone navali invece tale reparto si occuperà anche della produzione di schiumati.
Si possono individuare tre tipologie di materiali che attraversano i vari reparti per confluire nellarea del montaggio finale:
In tali schemi, sono individuati i percorsi tipo seguiti dai diversi materiali. In realtà per ogni differente versione di prodotto tali flussi possono variare, anche in maniera considerevole, con ripetuti passaggi attraverso gli stessi reparti fino a giungere al montaggio finale.
Il modo con cui le risorse umane vengono impiegate non segue regole facilmente schematizzabili; il responsabile della Produzione può infatti disporre della massima flessibilità spostando gli operatori tra i diversi centri di lavoro in funzione delle circostanze contingenti. Il numero di risorse umane destinato ai vari reparti viene cioè scelto di volta in volta, a seconda dellurgenza della commessa o della sua dimensione, per cui tali parametri risultano difficilmente codificabili. Quando, ad esempio, si arriva al momento finale del montaggio, che è possibile solo quando tutti i componenti sono disponibili, generalmente quasi tutti gli operai della fabbrica vengono spostati in questa area..
Più semplice è la realizzazione degli interiors che impegna il solo reparto falegnameria e presenta caratteristiche più o meno artigianali.
Modalità di acquisizione e gestione degli ordini
Relativamente alle modalità di acquisizione e gestione degli ordini, cè da dire che la Geven è unazienda che opera esclusivamente su commessa. Il primo passo delliter, che porta infine al lancio degli ordini di produzione, consiste in una richiesta di offerta formulata dal cliente per la fornitura di un certo quantitativo di prodotto con le caratteristiche specificate. A questa richiesta dofferta, lUfficio Commerciale risponde con unofferta, specificando, in primo luogo, la disponibilità a soddisfare le richieste del cliente, il prezzo della fornitura (almeno in maniera approssimata) ed una possibile data di consegna. Nel formulare lofferta, lUfficio Commerciale si avvale della collaborazione dellUfficio Tecnico, che si occupa di eseguire una progettazione di massima del prodotto da realizzare, e degli uffici Programmazione e Ingegneria di Produzione che hanno il compito di valutare la fattibilità e il prezzo della commessa, compatibilmente con il carico di lavoro dei vari reparti e con le criticità di approvvigionamento delle materie prime.
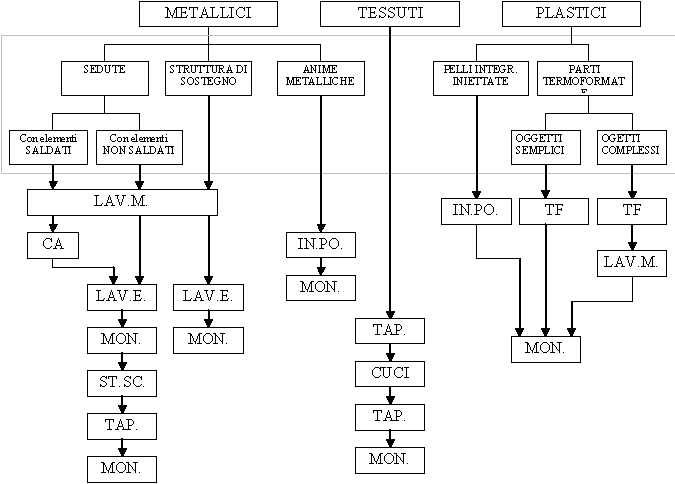
Schema semplificato del flusso di materiali
Questa fase può risultare più o meno complessa a seconda delle circostanze che si presentano; infatti può accadere che la richiesta del cliente possa essere soddisfatta utilizzando un prodotto già esistente, al quale si devono apportare solo poche modifiche. In tal caso, lattività di progettazione di massima risulta abbastanza agevole, così come è facile stimare i costi ed i tempi di realizzazione. Diverso è il discorso nel caso in cui sia necessario realizzare un prodotto completamente nuovo che, nel caso di poltrone di tipo aeronautico, comporterebbe una nuova omologazione e quindi tutta una complessa procedura da seguire. In tal caso, è necessario dettagliare maggiormente la fase di progettazione di massima, facendo una stima dei materiali occorrenti, contattando eventuali fornitori per lacquisizione delle materie prime, definendo quale possa essere limpegno dei centri di lavoro per arrivare infine a formulare correttamente lofferta.
Può anche accadere che la richiesta del cliente sia di realizzare un prodotto secondo un suo progetto, nel qual caso lUfficio Tecnico dovrà esaminare il progetto per definire i fabbisogni di materiali e quindi fare una stima dei costi e dei tempi di produzione.
Se lofferta viene accettata, inizia la fase di contrattazione in cui si devono definire compiutamente tutti i parametri legati alla commessa. Anche in questa fase intervengono gli uffici Commerciale, Programmazione e Ingegneria di Produzione che, attraverso una serie di confronti con il cliente e successive modifiche che tengano conto delle esigenze di entrambe le parti, arrivano infine alla stesura di un documento che definisce la commessa in tutti i suoi dettagli.
A questo punto si procede allapertura della commessa; lUfficio Tecnico si occupa della definizione di tutti i disegni, a partire dai quali si andranno a definire i cicli di lavorazione, mentre lUfficio Acquisti provvede allacquisizione dei materiali necessari. Terminata questa fase, si passa quindi alla realizzazione vera e propria del prodotto. Come già accennato, nel caso della produzione di parti aeronautiche è necessario mantenere la documentazione relativa a tutte le singole fasi del ciclo produttivo e a tutti i singoli componenti impiegati (compresi i fornitori ed i lotti di provenienza) per poter poi risalire ad ogni dettaglio utile nel caso in cui si verificassero guasti o malfunzionamenti di qualunque tipo.
Rapporti con Main Contractor Piaggio
Per quanto riguarda i rapporti con Piaggio, cè da dire che i suoi ordini rappresentano una quota variabile tra il 5 e il 10% del fatturato complessivo. Tali ordini sono relativi alla fornitura di "shipset", ossia di set completi di poltrone per singolo velivolo, ed arredi, questi ultimi da realizzarsi su progetto del cliente.
Essi vengono gestiti secondo le modalità precedentemente descritte.
Per la simulazione dellattività produttiva della ditta Geven S.r.l., partner industriale dellUniversità di Salerno nellambito del progetto corrente, si è fatto ricorso, come già detto, al linguaggio Arena versione 4.
Nel modello Arena sono sostanzialmente distinguibili due parti principali facilmente individuabili. La prima riproduce laspetto fisico dellazienda; essa comprende la modellazione dei reparti produttivi, con i singoli macchinari e le risorse in essi presenti. Ogni reparto riceve le entità da processare, esegue le operazioni secondo le modalità ed i tempi indicati dallentità stessa sotto forma di variabili o attributi. Una volta completate le operazioni nel reparto, lentità viene spedita al reparto successivo secondo quanto dettato dal suo ciclo di lavorazione.
Il secondo macroblocco del modello è quello che riproduce laspetto di gestione logica delle informazioni necessarie allazienda per portare avanti le attività di produzione. Allinterno di questa parte, sicuramente più complessa della prima, vengono gestite le informazioni riguardanti gli ordini di produzione. Sulla base dei nuovi ordini, che vengono acquisiti dal modello tramite lettura dalle porte socket, degli ordini ancora in corso di completamento, delle date di consegna richieste e delle disponibilità di materiali e risorse, il modello, utilizzando le informazioni presenti nel suo database tecnologico, invia ai reparti produttivi le entità da processare fornendo ad ognuna di esse tutte le informazioni necessarie alla lavorazione nel singolo reparto. Al completamento di ciascuna fase produttiva, le entità processate nei reparti produttivi ritornano nel blocco logico dove viene aggiornato lo stato di avanzamento della lavorazione; se esse devono subire ulteriori lavorazioni ricevono, sotto forma di attributi, le nuove informazioni necessarie prima di essere rinviate ai reparti produttivi, altrimenti vanno ad incrementare il contatore dei pezzi completati. Al raggiungimento delle quantità richieste viene generato il messaggio output relativo alle produzioni eseguite.
Il modello prevede anche la gestione del magazzino materie prime, con aggiornamento delle scorte in giacenza e, quando necessario, lemissione di ordini di acquisto ai fornitori.
In realtà il modello Geven, oltre al simulatore Arena, prevede per il suo funzionamento, lutilizzo di un database tecnologico, scritto in Access, e di una serie di fogli di calcolo Excel. I moduli realizzati sono integrati tra loro grazie a codici scritti in Visual Basic (VBA) in grado di effettuare la necessaria migrazione dei dati.
Nel database Access sono presenti tutte le informazioni relative alle distinte base dei prodotti Geven, i cicli di lavorazione per ognuno dei componenti di tali distinte,
Il database Access viene utilizzato per linserimento delle distinte base relative ai prodotti Geven e dei cicli di lavorazione per ognuno dei componenti presenti nelle distinte. I cicli vengono definiti inserendo lesatta sequenza delle operazioni sulle macchine, indicando le risorse ed i materiali necessari, specificando i tempi ciclo e di setup di ogni operazione.
Sono inoltre presenti le informazioni riguardanti le quantità di materie prime necessarie alla realizzazione dei componenti e i relativi valori di giacenza a magazzino.
Al ricevimento di un ordine Piaggio, il modello Geven crea automaticamente, utilizzando i dati presenti nel database, una serie di fogli di calcolo Excel, che riportano per ogni commessa le quantità e i codici dei componenti necessari a realizzarla ed in cui vengono aggiornate man mano le quantità effettivamente realizzate.
La logica di funzionamento del Modello Geven realizzato è schematizzata nella figura seguente:
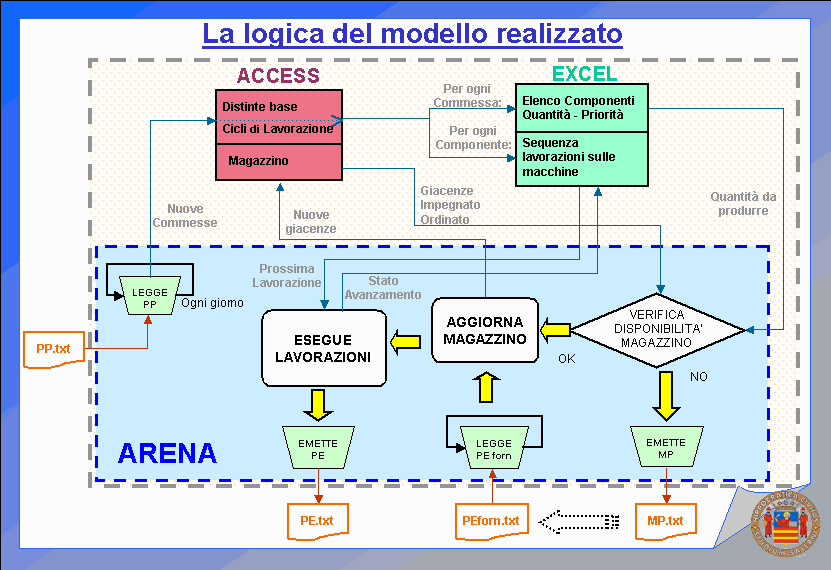
Il modello realizzato ricalca in maniera abbastanza fedele il funzionamento reale dellazienda Geven, sia per quanto riguarda la gestione dei flussi fisici (realizzazione dei pezzi) che per laspetto logico di acquisizione delle commesse e di pianificazione degli approvvigionamenti e delle lavorazioni da effettuare.
Il modello di simulazione è stato sviluppato a seguito di ripetute visite presso gli stabilimenti della ditta Geven. Tali visite hanno consentito di approfondire ed analizzare attentamente le caratteristiche degli impianti e dei macchinari e di comprendere nel dettaglio i processi produttivi.
Tale studio ha consentito di sviluppare il modello utilizzando blocchi funzionali che rappresentassero limpianto in modo del tutto analogo allo stabilimento reale. Tale corrispondenza è stata realizzata sia in termini di flusso produttivo, sia in termini di layout dellimpianto, infatti, il ciclo produttivo allinterno dei diversi reparti ed il flusso logico delle informazioni necessarie alla produzione (lettura distinta base, verifica disponibilità di magazzino, ecc.) seguono in modo pedissequo le reali fasi produttive della ditta Geven.
La riproduzione per molti versi fedele dellimpianto ha
semplificato la successiva fase di raccolta delle informazioni relative
ai prodotti realizzati dallazienda per la ditta Piaggio. In seguito, le
distinte base ed i cicli di lavoro sono stati inseriti nel database del
modello di simulazione per una verifica generale del corretto funzionamento
dei molti moduli inseriti nel progetto. Una volta verificata la bontà
del modello di simulazione, si è proceduto alla verifica e alla
validazione delle informazioni relative ai prodotti realizzati. Dopo alcune
difficoltà, relative soprattutto alla corretta trascrizione dei
molti dati inseriti, si è potuto notare una certa corrispondenza
tra il funzionamento dellazienda simulata e quello dellazienda reale.
DE, LAquila
AllUniversità di LAquila è stato assegnato il compito di provvedere allo sviluppo di un modello di simulazione per un particolare subfornitore Piaggio (la OMA di Foligno) ed allintegrazione di tale simulatore nel modello complessivo della supply chain.
Sono state quindi compiute numerose visite presso lo stabilimento OMA per acquisire le informazioni necessarie allo sviluppo di tale attività. Lazienda OMA opera una produzione per commessa di componenti per aeromobili utilizzando una struttura produttiva di tipo job shop cui si affianca un piccolo sistema di lavorazione flessibile (FMS).
Per quanto riguarda le modalità di gestione, partendo da un portafoglio ordini viene effettuata inizialmente una programmazione aggregata della produzione di tipo sostanzialmente manuale e successivamente tramite un sistema MRP si pianificano gli ordini di lavoro verso linterno e gli ordini di acquisto delle materie prime verso i fornitori. Allatto dellinizio del rapporto di collaborazione non veniva impiegato alcun metodo formale di schedulazione automatizzato. Successivamente è stato introdotto un sistema computerizzato di schedulazione a capacità infinita agganciato alloutput del sistema MRP.
Durante lesecuzione della programmazione MRP si ha una aggregazione degli ordini per lo stesso part number ed allordine risultante viene assegnata una data di consegna (alla successiva fase di lavorazione) che è pari alla più vicina delle date di consegna dei vari ordini aggregati. Nel piano di produzione vengono indicati, per ogni ordine, la data di consegna e la quantità richiesta. I tempi di consegna sono dellordine di un anno e per questo motivo non si necessita di una schedulazione molto spinta. Le informazioni di feedback necessarie per il controllo avanzamento della produzione provengono dai vari centri di lavoro dove loperatore con lausilio di una penna ottica provvede a segnalare le date effettive di inizio e fine lavorazione di ogni singolo ordine.
In tale scenario si è provveduto inizialmente a sviluppare un modello di simulazione semplificato, in ambiente Arena, che accettasse in input da un lato gli ordini di produzione od assemblaggio già pianificati dal sistema MRP e dallaltro gli ordini di provenienza HLA relativi alla federazione in esecuzione. Questi ultimi venivano preventivamente esplosi internamente al simulatore tramite le relative distinte base. Lazienda in questione produce per il cliente Piaggio soltanto un assieme e nella fattispecie la barra di comando di un particolare velivolo e questo assieme è composto di 30 componenti.
La pianificazione degli ordini di provenienza HLA viene dunque eseguita in sovrapposizione ad un piano di produzione prefissato dallazienda.
Il modello simula lintero iter a cui è sottoposto ogni singolo ordine gestito dallazienda, dal momento in cui entra fino al momento in cui esce dal sistema produttivo.
Lentità ordine impegna il materiale necessario alla produzione o allassemblaggio e di seguito le risorse che sono preposte a realizzarlo secondo una sequenza propria di ogni tipo di codice. I componenti prodotti confluiscono in un magazzino centrale da cui vengono prelevati sulla base degli ordini di assemblaggio.
Le informazioni strutturali (distinta base) sono organizzate opportunamente in files ad accesso diretto mentre gli ordini provenienti da MRP vengono letti da files ad accesso sequenziale. Tale metodo di rappresentazione della distinta base è comunque molto oneroso e difficilmente leggibile quando il cresce il mix di prodotti assortiti dallazienda (e con esso il numero dei part number diversi da gestire) .
Per quanto riguarda invece le informazioni anagrafiche dei vari codici, esse sono memorizzate su variabili interne al modello.
Avendo assunto tale criterio di modellizzazione del sistema
produttivo risulta di conseguenza che in corso di simulazione non è
possibile riflettere i cambiamenti avvenuti nella programmazione aggregata
che ha dato luogo alla programmazione dei fabbisogni MRP utilizzata in
input dal simulatore. Per quanto riguarda quindi gli ordini di provenienza
dalla federazione Piaggio si otterrebbero utili informazioni riguardo al
rispetto alle date di consegna previste per i vari ordini, il grado di
saturazione delle risorse ecc. solo per quegli ordini pervenuti prima della
data di inizio della simulazione ovvero per i quali sia stato possibile
inserirli nella programmazione aggregata. A partire dallinizio della simulazione
gli unici nuovi ordini entranti nel sistema sarebbero dunque quelli provenienti
dalla federazione HLA. Tale circostanza sarà oggetto in futuro di
particolare attenzione poiché rappresenta un limite significativo
alla validità della simulazione dovuto alla specifica realtà
della azienda in oggetto, la quale, sebbene estenda la sua pianificazione
e quindi la programmazione MRP su periodi lunghi (dellordine di 24 mesi),
potrebbe ovviamente essere costretta a rielaborare in corso dopera tale
programmazione a scapito degli ordini dei clienti che risultino meno rilevanti
per OMA in termini economici (Piaggio contribuisce a meno dell1% del fatturato
OMA) ed hanno tempi di attraversamento limitati e quindi possono essere
frequentemente rischedulati. Tali cambiamenti operati dal management aziendale
non si risentirebbero allinterno del modello di simulazione.
DIMEG, Bari
Lazienda Salver è specializzata nella lavorazione di materiali compositi per lindustria aeronautica. Lintera produzione è costituita da due tipologie di pezzi:
Vengono prodotte su commessa. Lazienda, come la maggior parte delle aziende aeronautiche per forniture sia militari sia civili, lavora con commesse generalmente, ma non necessariamente, ripetitive.
In Fg.1 è riportata una schematizzazione del processo produttivo delle parti semplici.
Il materiale di partenza è costituito da rotoli di un composito preimpregnato, immagazzinato in 3 celle frigorifere di grandi dimensioni che costituiscono il cosiddetto "magazzino freddo". Limpiego di celle frigorifere per lo stoccaggio dei preimpregnati è indispensabile per preservarne le caratteristiche chimico-fisiche. I rotoli vengono prelevati secondo le esigenze di produzione e spostati mediante transpallet in un frigorifero di dimensioni ridotte adiacente ai reparti di produzione, in cui sostano per un tempo variabile da 1¸ 3 settimane in base allo scheduling di produzione.
Per la realizzazione di alcuni profili alari, si impiegano pannelli di honeycomb come elemento di rinforzo strutturale. I fogli di honeycomb vengono tagliati, impacchettati e quindi identificati (parametri d ingresso e lotto di produzione).
Il materiale preimpregnato e (eventualmente) lhoneycomb vengono inviati assieme allattrezzatura di lavoro ad un reparto di lavorazione ad atmosfera controllata CR (Clean Room), climaticamente isolato dal resto della struttura dello stabilimento. Prima dellentrata in CR, gli attrezzi richiedono unoperazione di pulitura dalla resina polimerizzata residua dei processi precedenti. In seguito, si ricopre lattrezzatura con uno strato di materiale distaccante al fine di evitare danneggiamenti nel momento della separazione dalla stessa del pezzo lavorato.
Nella Clean Room si eseguono le seguenti operazioni:
La Salver dispone di tre autoclavi:
Per il 67% delle parti semplici, il ciclo di cura è contraddistinto dai seguenti parametri:
Per il 70% dei part-number, la sformatura è seguita da operazioni di controllo ad ultrasuoni (manuali o automatiche), necessarie per verificare la corretta polimerizzazione e lomogeneità del ciclo di cura (realizzato tramite feedback dei dati acquisiti da plc on-board). I controlli ad ultrasuoni di tipo manuale vengono eseguiti allinterno della Salver e richiedono circa unora. Lazienda si sta attrezzando per eseguire anche i controlli automatici che attualmente vengono commissionati ad unazienda sita a Foggia. Considerando le spedizioni di invio e consegna, tale operazione richiede circa una settimana.
Il controllo è seguito dalle operazioni di contornatura e foratura, di durata trascurabile se effettuate in sede, realizzate in circa 3 giorni se commissionate ad esterni.
La successiva fase di verniciatura viene eseguita quasi sempre in sede; essa richiede 3-4 h. La durata delloperazione è fortemente influenzata dallomogeneità delle caratteristiche cromatiche dei pezzi, vista lentità dei tempi di set up per il reparto verniciatura.
Il ciclo produttivo si conclude con le fasi di controllo dimensionale (tempo richiesto 1 h) e immagazzinamento del prodotto finito.
In Tabella sono riportate le fasi in cui si è scomposto il processo produttivo con le relative durate.
Tabella: Fasi del processo produttivo delle parti semplici
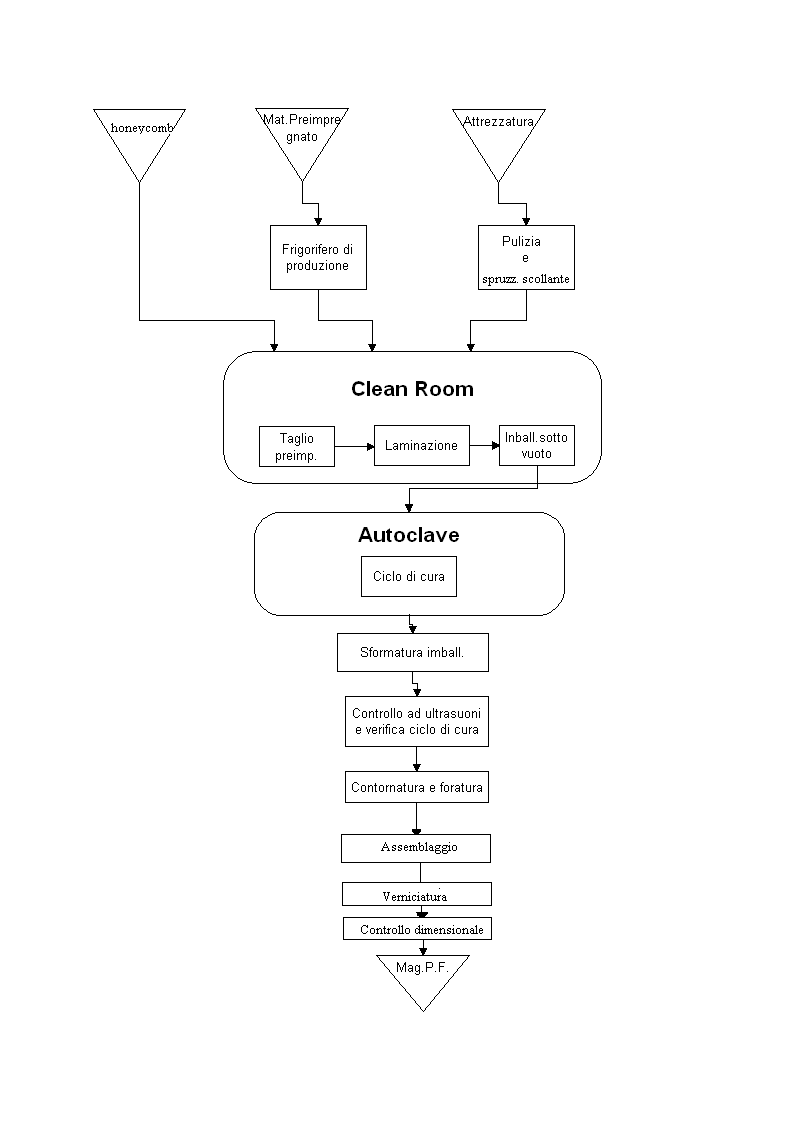 Schematizzazione
del processo produttivo delle parti semplici
Schematizzazione
del processo produttivo delle parti semplici
2) parti complesse
Le parti complesse sono sottogruppi strutturali aeronautici, ottenuti dallassemblaggio di parti in materiali compositi con parti metalliche.
Le parti in materiali compositi provengono dalla produzione di parti semplici dellazienda stessa. Si utilizzano due tipi di parti metalliche, approvvigionati entrambi da fornitori esterni:
Di seguito è descritta la produzione in Salver dello stabilizzatore di coda, uno dei componenti che lazienda fornisce a Piaggio. In termini di parti semplici, esso è costituito da:
Lunica condivisione riguarda il ciclo di cura, svolto in 3 autoclavi gestite da operatori specializzati ed utilizzate anche per altre produzioni. Lazienda assicura che lautoclave è sempre disponibile per la produzione dello stabilizzatore.
Il processo produttivo può pertanto essere schematizzato
attraverso una serie di fasi, svolte in altrettanti reparti diversi, a
ciascuna delle quali corrispondono risorse ben determinate in termini sia
di uomini sia di attrezzature.
Descrizione del processo produttivo dello stabilizzatore del P180
Il materiale viene prelevato da magazzino e tagliato in un apposito reparto da 2 operai che non svolgono altre fasi del processo produttivo dello stabilizzatore. Tale operazione è realizzata separatamente per fasciame superiore e fasciame inferiore e non è richiesta per le altre parti semplici. Il tempo necessario è molto ridotto (16 ore/uomo per stabilizzatore); pertanto non sussistono problemi ad assicurare la disponibilità della manodopera richiesta.
2.1 Prelievo e registrazione preimpregnato
2.2 Prelievo attrezzatura e trattamento con distaccante
2.3 Taglio preimpregnato e laminazione
Il preimpregnato e le attrezzature vengono prelevati dagli stessi 4 operai che svolgono la laminazione in "clean room". La laminazione viene realizzata su tutte le tipologie di parti semplici dello stabilizzatore. Per i fasciami, dovendo sovrapporre al preimpregnato il pannello di honeycomb prima di laminare, sussiste un vincolo di precedenza tra la fase 1 e la fase 2.3.
Il prelievo del preimpregnato avviene una sola volta per tutti i tipi di parti semplici presenti in uno stabilizzatore.
Il prelievo e la preparazione delle attrezzature, il taglio del preimpregnato e la laminazione vengono svolti dando priorità ai due fasciami, in quanto linizio della fase 3 è vincolato alla fine della fase 2 su entrambi. Le dimensioni delle parti non consentono a più di 2 persone di lavorare contemporaneamente sullo stesso fasciame; pertanto i due fasciami vengono realizzati in parallelo da 2 squadre di 2 operai ciascuna. Il taglio del preimpregnato e la laminazione richiedono molto più tempo per il fasciame inferiore. Per far cominciare prima la fase 3, la squadra che realizza il fasciame superiore, prima di cominciare il fasciame, realizza alcune parti (bordi dentrata) per quello inferiore. La squadra che si occupa del fasciame superiore finisce comunque prima e passa alle centine (le centine hanno priorità su TIP e FENCE perché vanno in assemblaggio). Una volta pronto anche il fasciame superiore, le due squadre realizzano assieme TIP e FENCE.
Il taglio del preimpregnato e la laminazione sono sottoposti ad un vincolo di durata massima in quanto il preimpregnato non può essere tenuto più di 200 ore fuori dal frigorifero finché non viene reso stabile dal ciclo di cura in autoclave. Tali operazioni assumono per i fasciami una durata tale da vincolare ad eseguirle in modo continuativo. Questo si traduce nella necessità di rinviarne linizio alla settimana successiva tutte le volte che il calendario di produzione le farebbe cominciare dopo il martedì o in presenza di festività infrasettimanali.
Gli addetti alle autoclavi si occupano anche di introdurre i pezzi nei sacchi prima delloperazione e di estrarli al termine.
I pezzi vengono introdotti in autoclave sulle attrezzature di taglio e laminazione; disponendo di una sola attrezzatura per ciascun tipo di pezzo, linizio della fase 2 è vincolato alla fine della fase 3 per lo stabilizzatore precedente.
Sui fasciami viene commissionato un controllo non distruttivo ad Alenia (FG). La spedizione avviene mediante una cassa dedicata. Per le centine, il controllo a ultrasuoni viene effettuato direttamente in Salver. Gli addetti al controllo non distruttivo in Salver sono 3 e si occupano di tutte le produzioni dellazienda; è sempre assicurata la disponibilità della risorsa richiesta per lo stabilizzatore. Per TIP e FENCE, le dimensioni ridotte consentono di effettuare esclusivamente il controllo dimensionale (fase 5.2).
5.1 Trimmatura e foratura
5.2 Controllo dimensionale
Queste operazioni vengono svolte su tutti i tipi di parti semplici da 2 operai dedicati.
I due fasciami vengono assemblati a mezzo delle centine in un apposito reparto da 2 operai dedicati ed entrambi in grado di realizzare tutte le operazioni di assemblaggio. Tale fase può essere suddivisa in due sottofasi: assemblaggio "in bianco" e assemblaggio "su scalo". Pertanto si possono avere in assemblaggio 2 stabilizzatori contemporaneamente, uno in ciascuna sottofase.
Il semilavorato in uscita dallassemblaggio, TIP e FENCE vengono sottoposti ad un controllo finale, eseguito generalmente di 2 operatori in 16 ore. Le prime operazioni di controllo (circa 4 ore di durata) vengono effettuate sullo scalo di assemblaggio. Sussiste quindi un vincolo di precedenza tra linizio dellassemblaggio "su scalo" e la fine del controllo per lo stabilizzatore precedente.
Dei 7 addetti ai controlli su prodotti in uscita e materiali in ingresso, 2 sono abilitati ad operare sullo stabilizzatore. E sempre assicurata la loro disponibilità in relazione alla produzione dello stabilizzatore.
Attualmente non sussistono problemi di indisponibilità di manodopera.
In tabella sono riportate le risorse dedicate alle diverse fasi del processo produttivo dello stabilizzatore.

Tabella: Manodopera utilizzata per il processo produttivo dello stabilizzatore
Manutenzione delle attrezzature
Sussistono esigenze di manutenzione per le attrezzature di taglio e laminazione, per le autoclavi e per lo scalo di assemblaggio. In generale, più che una manutenzione di tipo preventivo, si tende ad effettuare delle verifiche periodiche.
Le maschere di taglio e laminazione vengono sottoposte ad un controllo visivo dopo ogni utilizzo. Gli interventi a seguito di eventuali danneggiamenti riscontrati in tali controlli o da Piaggio sul prodotto finito, se non sono tali da rendere impossibile la produzione, vengono effettuati quando il reparto è fermo per impossibilità di eseguire taglio e laminazione in modo continuativo.
Per le autoclavi, lazienda sta passando da una politica di manutenzione a guasto ad una di tipo preventivo. Si cerca di intervenire quando lautoclave non serve, vale a dire quando il reparto taglio e laminazione è fermo. Durata e frequenza degli interventi (rispettivamente 1 giorno e una volta ogni 6 mesi per manutenzione preventiva) sono comunque tali da non determinare una consistente indisponibilità della risorsa. Pertanto la manutenzione delle autoclavi è da escludere come causa eventuale di discontinuità del flusso produttivo.
Lo scalo di assemblaggio viene controllato 1 volta allanno. Tale operazione richiede circa 2 giorni e viene svolta quando lo scalo è libero, generalmente tra venerdì e sabato. Essa non causa quindi nessuna indisponibilità della risorsa.
In tabella: è presentato uno schema delle attrezzature utilizzate in ciascuna fase del processo produttivo dello stabilizzatore; si può ritenere per tutte che la disponibilità sia unitaria.

Tabella: Attrezzature utilizzate per la produzione dello stabilizzatore del Piaggio Avanti P180
Set-up degli impianti
Utilizzando attrezzature dedicate, il set-up consiste in operazioni (es. prelievi, preparazione, ) ripetute per ogni stabilizzatore e che pertanto sono state introdotte nel ciclo di lavoro. Per le autoclavi, unica attrezzatura condivisa con altre produzioni, il set-up consiste nellimpostazione del ciclo di cura; eventuali cambi di produzione non influenzano la durata di questa operazione. Non sussistono quindi interruzioni del processo produttivo descritto causate da set-up.
Standard qualitativi nel processo produttivo dello stabilizzatore del Piaggio Avanti P180
La produzione dello stabilizzatore del Piaggio P-180 è sottoposta ad elevati standard qualitativi che vanno anche oltre le norme specifiche per il settore aeronautico.
In tale contesto si inserisce il concetto di autoqualità in linea: a partire dalle fasi di taglio e laminazione, ogni operatore è direttamente responsabile del proprio output; ciò avviene tramite controlli dopo ogni fase di lavorazione (controlli "point to point"). Se non vengono riscontrati difetti, loperatore appone un suo timbro personale che attesta lesito del controllo. In caso di difetti, si richiede al cliente una "concession" per mandare avanti il pezzo o per rilavorarlo. Sono quindi possibili due tipi di interventi sui difetti:
In figura è riportato il diagramma di processo relativo alla realizzazione in Salver dello stabilizzatore di coda del P180; in tabella sono indicate le attività.
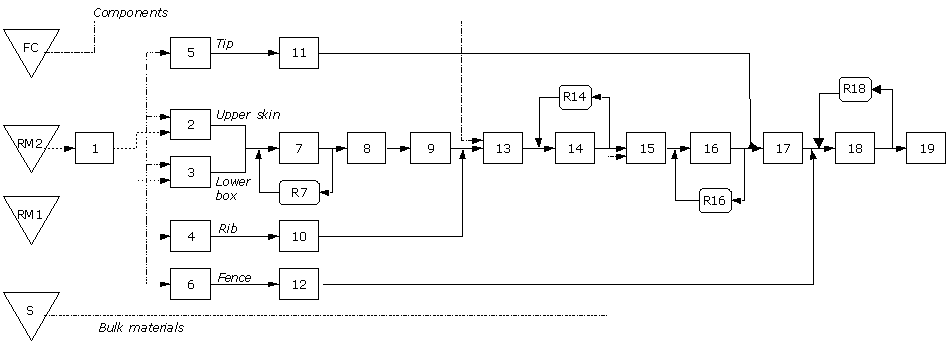
magazzini
rilavorazioni
Diagramma di processo dello stabilizzatore del P180
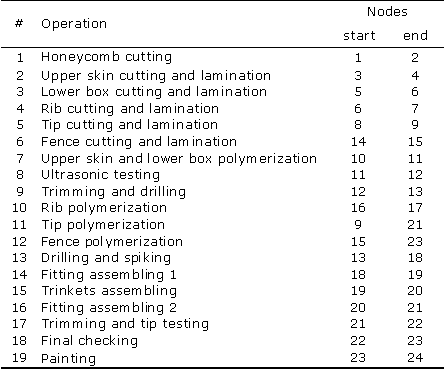
Tabella: Attività del processo produttivo dello stabilizzatore
Si è fatto riferimento al piano di produzione in tabella, relativo ad un orizzonte temporale di un anno.

Tabella: Piano di produzione annuale dello stabilizzatore
Le date di consegna sono espresse in termini di giorni lavorativi.
I vincoli tecnologici fra le attività del k-esimo stabilizzatore sono rappresentate nel reticolo PERT in figura. Sono inoltre indicati i vincoli di precedenza fra le attività di due stabilizzatori successivi causati da disponibilità limitata delle attrezzature.
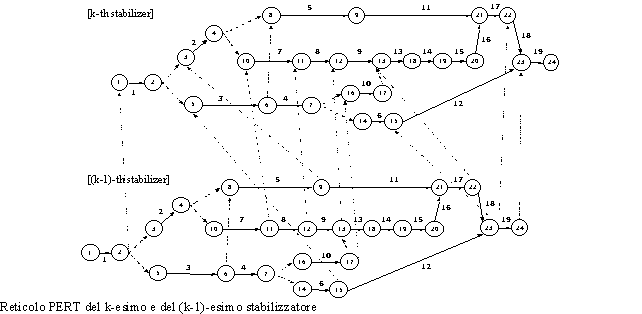
Nella tabella che segue sono riportate le durate minima e massima dellattivita ed i corrispondenti costi diretti (valori alterati per motivi di riservatezza come gia accennato).

Tabella: Durate delle attività e corrispondenti costi diretti per il processo produttivo dello stabilizzatore
Sulla base dei dati forniti, si è formulato il problema di schedulazione e di ottimizzazione dellallocazione delle risorse secondo lapproccio elaborato dallunità di ricerca e precedentemente illustrato.
Il modello di simulazione "Salver"
Il modello simula un processo produttivo costituito da sei macrofasi, ciascuna da numerose fasi di lavoro elementari. La suddivisione in macrofasi di attività elementari consente di semplificare il monitoraggio dello stato di avanzamento della produzione di ciascuno stabilizzatore.
Le macrofasi considerate sono:
I magazzini materie prime sono schematizzati attraverso blocchi che generano gruppi di entità (quantità prelevata) con frequenza costante. I materiali sono portati a bordo linea e resi disponibili per la produzione, quando richiesti. I materiali costituiscono una coda e sono prelevati con disciplina FIFO quando i tre server del reparto di taglio e laminazione, che lavorano rispettivamente il fasciame inferiore, quello superiore e le centine, comunicano a monte la disponibilità ad eseguire nuove lavorazioni. Per il fasciame superiore, la presenza di controlli a valle può determinare rilavorazioni. In ogni postazione di taglio e laminazione non è ammesso più di un pezzo per volta per limiti di attrezzatura disponibile. Un nuovo pezzo può entrare nel reparto di taglio e laminazione se la stazione successiva che esegue in autoclave il ciclo di cura si rende disponibile.
Sono state omesse le operazioni di pulizia delle attrezzature, di inserimento dei pezzi su attrezzatura nei sacchi, di messa sottovuoto dei pezzi e di caricamento in autoclave in quanto operazioni che richiedono manodopera non critica e sono effettuate in tempi ridotti e mascherati da attività più lunghe. Le autoclavi lavorano su tre turni giornalieri mentre il restante processo produttivo è realizzato su due turni.
I controlli non distruttivi sono eseguiti da un fornitore esterno e, pertanto, hanno durata fortemente variabile. Il server corrispondente a questa operazione è caratterizzato da un tempo di servizio distribuito secondo una funzione di probabilità discreta, ottenuta sulla base delle rilevazioni effettuate. Questa operazione non può essere eseguita su più di un pezzo per volta in quanto è unica lunità di carico speciale per la spedizione dei pezzi al controllo non distruttivo.
Nellassemblaggio le operazioni manuali richiedono un tempo stocasticamente variabile e non assicurano una uniforme qualità. Stazioni di controllo rilevano gli scarti con predefinita probabilità. Gli scarti sono inviati a rilavorazioni a monte.
Lapprovvigionamento del kit di assemblaggio Piaggio e delle minuterie avviene con lead time variabili secondo distribuzioni di probabilità ricavate da dati storici. In assenza di minuterie o componenti approvvigionati lassemblaggio è interrotto per dare inizio allassemblaggio del successivo stabilizzatore eventualmente disponibile in coda.
Lassemblaggio consiste di tre fasi principali e sequenziali. Ciascuna fase ha durata assegnata dallo schedulatore sulla base delle risorse allocate. Lo scalo di assemblaggio è risorsa limitata e non più di uno stabilizzatore per volta può essere assemblato.
l simulatore è in grado di fornire per ogni stabilizzatore:
DIG, Milano
Il modello è una versione semplificata della realtà produttiva, che ricostruisce però i comportamenti e le problematiche di massima, al fine di rimanere aderente con la realtà.
La realtà è riprodotta nei suoi tre reparti produttivi (laminazione, polimerizzazione, finitura), che sono considerati come semplici risorse produttive. Lunica risorsa critica è la laminazione, sulla quale si basa tutta la programmazione della produzione. I reparti seguenti sono invece delle risorse che fanno spendere del tempo T alla produzione.
Nel modello entrano due tipi di ordini di produzione, quelli provenienti da Piaggio e quelli derivanti dagli altri clienti. I primi arrivano come oggetti dalla federazione HLA, i secondi sono invece generati stocasticamente, in modo tale da riprodurre il mix produttivo reale. In particolare gli ordini extra Piaggio sono riassumibili in 6 categorie, qui di seguito riportate in tabella. La definizione di tali categorie deriva da quanto si è potuto osservare in azienda.
| Codice | Descrizione |
| unitario | Sono ordini di produzione di un solo componente |
| seriale12 | Sono produzioni seriali di 12 componenti (pannelli a nido dape) |
| seriale24 | 24 componenti (come sopra) |
| seriale36 | 36 componenti (come sopra) |
| multiplo2 | Sono ordini di più esemplari dello stesso part number |
| multiplo3 | Idem |
| multiplo5 | Idem |
Ordini extra Piaggio
Gli ordini provenienti da Piaggio sono invece, per ipotesi semplificatrice, tutti corrispondenti ad un intero ship set del velivolo P180, denominato cockpitkit. Sono tutti elementi da eseguire, in numerosità differente, in materiale composito. Per ipotesi, ogni ship set richiesto corrisponde a 40 part number diversi. Per ogni part number, anche se richiesto in numerosità maggiore dellunità, si ipotizza che lazienda generi un singolo odp.
Per ipotesi semplificatrice, il materiale fibroso impiegato è sempre il medesimo per ogni prodotto. La quantità di materia prima che ogni codice necessita è espresso in termini di metri di tessuto. Data lindisponibilità di dati specifici, il valore unitario è estratto da una funzione casuale. Il magazzino parte da una situazione di pieno ed il sistema di approvvigionamento è a livello di riordino. Lintervallo di interarrivo tra un ordine di acquisto e leffettiva consegna della merce è pari a 8 settimane.
La gestione della produzione avviene su un orizzonte di pianificazione mensile, rispetto alla sola risorsa di laminazione. Per rispettare la metodologia perseguita in azienda, lordinamento degli ordini avviene per date di consegna previste. La schedulazione viene controllata ogni giorno ed ogni inizio settimana, quando il modello si apre alla federazione. Gli ordini ricevuti, sia Piaggio che extra, vengono a questo punto analizzati, per la determinazione dei tempi di produzione e la verifica della disponibilità di materie prime, poi sono inviati al reparto. Quelli che si trovano ad avere meno di una settimana alla consegna sono considerati come urgenze, gli altri sono inseriti nel piano totale. Ad ogni inizio mese l80% delle ore di laminazione è destinato al soddisfacimento degli ordini normali, mentre è mantenuto un 20% di monte ore apposta per le urgenze. Nel caso non vi siano urgenze, lintera produttività mensile è riempita da ordini a scadenza programmata.
Gli ordini inviati alla produzione sono trasformati in odp/entità che fluiscono allinterno dei reparti nellordinamento loro assegnato in fase di programmazione.
Quando un odp è terminato passa alla spedizione. Gli odp di ordini extra Piaggio sono eliminati, mentre quelli di Piaggio, quando sono presenti tutti e 40 quelli riferiti ad un solo ordine, sono accomunati in un unico oggetto di "produzione eseguita" da rispedire a Piaggio.
La realtà Plyform è stata modellizzata con il simulatore ad oggetti SIMPLE++. Utilizziamo di seguito le specifiche del simulatore per illustrare il modello.
Il frame Plyform
Il modello dellazienda, contenuto nel frame Plyform, ricostruisce la realtà nei suoi tre reparti (laminazione, polimerizzazione, finitura), ognuno dei quali modellizzato in un sottoframe. I tre reparti sono oggetti ereditati da un unico padre, ma differiscono negli attributi specifici (produttività, risorse..).
Un frame di reparto produttivo
Nel generico frame di reparto si distinguono la sosta logica momentanea degli odp in circolo (buffer_in), il buffer di immissione alla risorsa produttiva (buffer), la risorsa produttiva (resource) modellizzata come un multi processore, in grado di rappresentare più unità di lavoro in parallelo, un buffer logico di disimpegno (buffer_out). I metodi regista_xxx sono responsabili delle operazioni di tracing della produzione di passaggio nel reparto (registrate nella tabella prod_reparto), mentre il metodo di routing è il responsabile della trasmigrazione del singolo odp lavorato alla prossima postazione.
La gestione della produzione (gestione dei magazzini, invio in reparto di un ordine) è modellizzata secondo le logiche dellazienda nel frame Programmazione e nei subframe interni.
Frame programmazione
In Programmazione si distinguono gli oggetti (gen_portafoglio e lettura_ordini) responsabili della lettura degli ordini arrivati sia dalla federazione, che generati stocasticamente, ripresi dal frame Data_vision in IO_management. La lettura degli eventuali ordini arrivati è eseguita ogni giorno di simulazione (time_gen_portafoglio). Gli ordini sono copiati in ordini_in_arrivo ed analizzati in genera_portafoglio. Questultimo metodo è responsabile della determinazione dei tempi di produzione di ogni prodotto e del lancio della procedura di verifica di disponibilità dei materiali (frame gestione_magazzino). In questultimo sottoframe è riprodotta la funzione di approvvigionamento, sia per quanto riguarda il riordino di magazzino materie prime che per quanto concerne la possibilità di produrre un ordine.
Quando gli ordini hanno a disposizione materia prima allora viene attivato il metodo ok_ordini che genera leffettivo portafoglio degli ordini eseguibili (ordini_eseguibili) e quindi attiva il metodo di generazione degli odp (forma_odp) e calcola le urgenze (flag_urgenze). Un ordine è considerato urgente se la differenza fra data di consegna richiesta ed istante di simulazione attuale è minore della settimana.
Gli ordini provenienti da Piaggio sono divisi, nel frame P180, in più odp, contraddistinti da un solo identificativo ordine.
Se non ci sono urgenze, la schedulazione della produzione avviene soltanto ogni 4 settimane (time_gen_odp): gli odp sono ordinati per data di prevista inizio lavorazione (calcolata come data di consegna tempo di prevista produzione) e come tali inviati alla laminazione, dopo che è stata creata unentità avente gli attributi di ognuno di essi. Le entità/odp sono logicamente accodate in buffer_out e spostate al reparto di laminazione con invio_produzione. La schedulazione della produzione avviene fino a saturazione del livello di produzione prevista per il mese (max_cap_rep) espressa come monte ore disponibile.
Se ci sono urgenze invece il processo di generazione delle entità/odp viene attivato senza dover attendere listante di inizio mese. Gli odp urgenti sono subito spostati al reparto, anche se non possono scavalcare produzioni già in corso. Il livello massimo di odp urgenti accettati è pari a max_cap_rep_urg ore di lavorazione (sempre in laminazione) per mese. Qualora questo livello sia superato lurgenza non viene considerata e viene posta in schedulazione per il prossimo mese.
Il frame Spedizione in Plyform è loggetto responsabile della registrazione della produzione eseguita e della comunicazione degli ordini Piaggio eseguiti alla federazione. View è un oggetto implementato per eseguire unattività di tracing della simulazione, utile allutente.
Ogni passaggio di ordini e produzione eseguita da e verso Piaggio, provenienti quindi dalla federazione, è realizzato nel frame di IO_management. Questa scelta si inquadra nella logica dei morsetti di cui abbiamo già parlato.
DPGI, Napoli
Lazienda Magnaghi opera nel campo della progettazione e costruzione di sistemi idraulici e carrelli di atterraggio per velivoli militari e civili. Fu fondata nel 1923 come "Magnaghi & CO.", con sede a Milano. Ha seguito lo sviluppo tecnologico dellaeronautica italiana e nel 1935, aprendo una filiale a Napoli, ha rappresentato una parte considerevole del contributo produttivo per lAeronautica Militare Italiana.
Negli anni 1945/49, vengono costituite la "Magnaghi Oleodinamica S.p.A." con stabilimenti in Milano e Brugherio e la "Magnaghi Napoli S.p.A." con stabilimento in Napoli.
Attualmente esistono solo gli stabilimenti di Brugherio e Napoli, con il nome di "Magnaghi Aerospace S.p.A.", sui quali sono articolate tre divisioni operative: la Divisione Carrelli (Landing Gears) nello stabilimento di Napoli, la Divisione Idraulica nello stabilimento di Brugherio e la Divisione Product Support, operante nellarea di entrambi gli stabilimenti.
La struttura organizzativa Magnaghi, che vede coinvolte le tre divisioni, è rappresentata nella figura seguente.
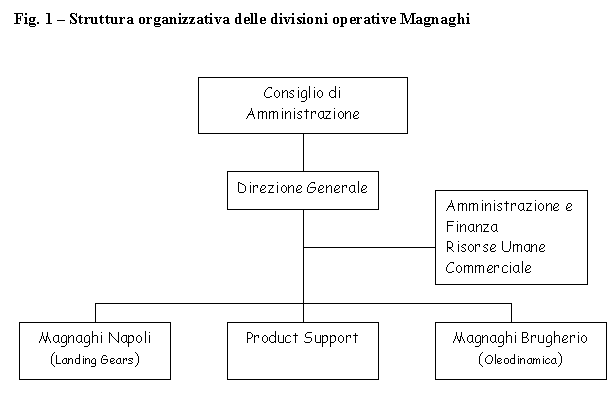
Dal momento che è stato sviluppato un simulatore per lazienda "Magnaghi Aerospace Napoli", di seguito ne riportiamo alcune informazioni di carattere generale.
Lazienda realizza Carrelli di atterraggio, Ammortizzatori ed Accessori Idraulici (serbatoi carburante, tubi di scarico e prodotti in lamiera).
La produzione è su commessa e la sua organizzazione è di tipo job-shop.
In particolare, la commessa Piaggio, per il carrello modello P180, è costituita da 24 serie annue; ognuna di esse si compone di 2 carrelli principali e di un azionatore. Il lead time medio di produzione è di sei mesi, quello commerciale (dallordine alla consegna) di dodici. Lincidenza sul fatturato è di circa 8-10%.
Lorganigramma funzionale dellazienda è schematizzato in figura 2
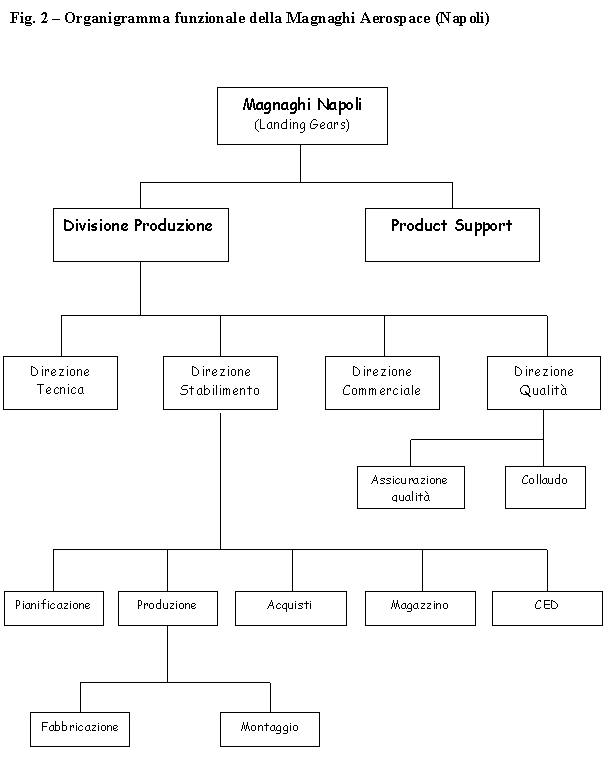
Lazienda Magnaghi è suddivisa in dieci reparti produttivi; il numero, la tipologia delle macchine e i centri di lavoro, in essi distribuiti, sono di seguito riportati.
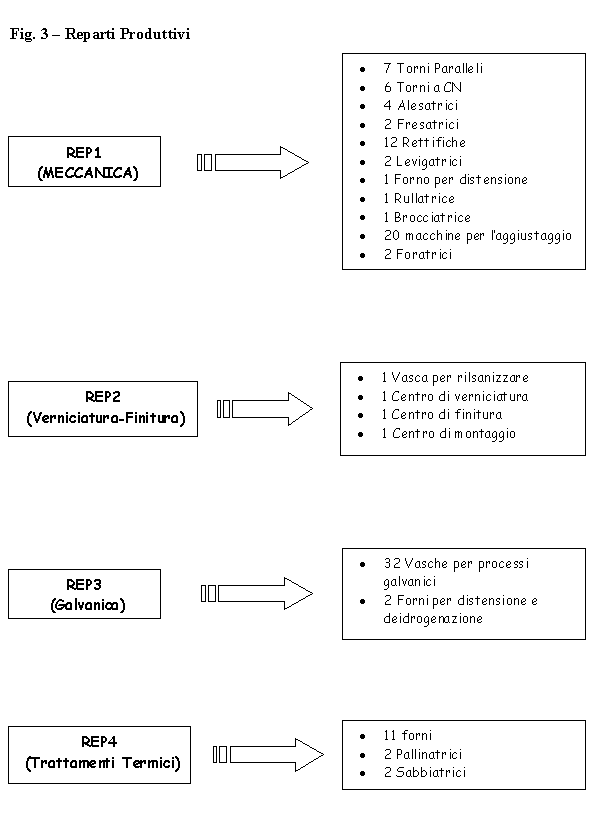
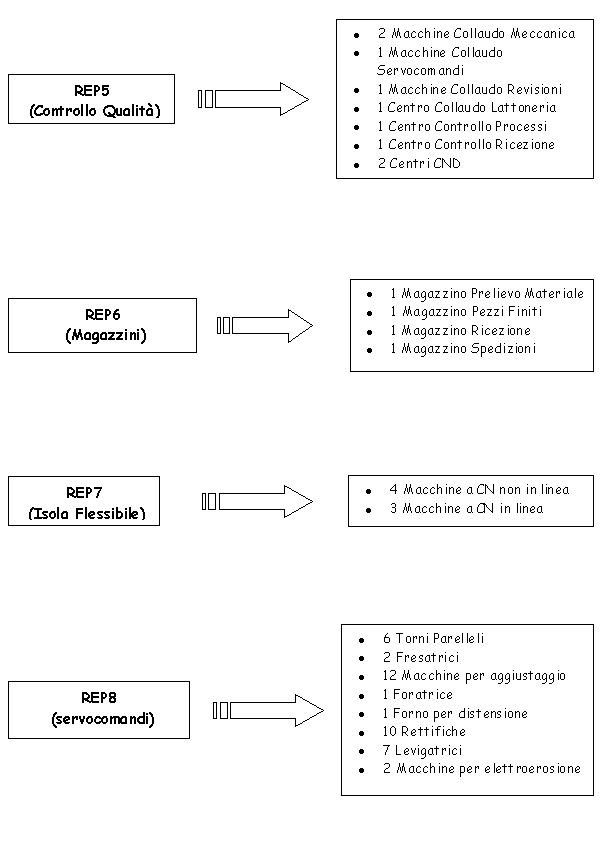
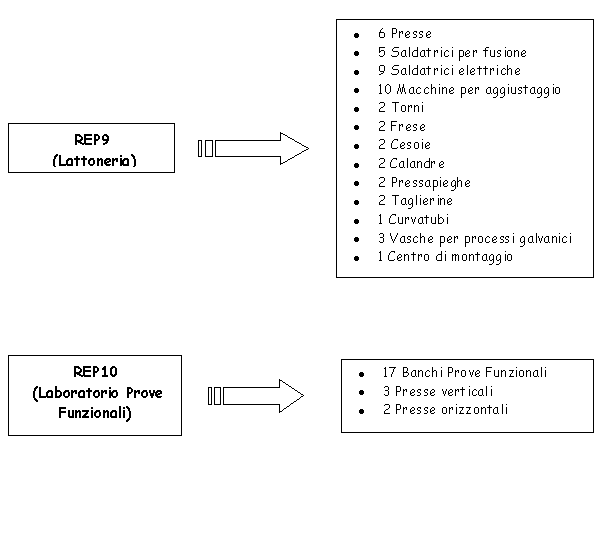
Le fasi tipiche del ciclo di produzione di un carrello sono riportate in figura.
Per la simulazione dellattività produttiva della ditta Magnaghi Aerospace S.r.l., partner industriale dellUniversità di Napoli, si è fatto ricorso, come già detto, al linguaggio Arena versione 4.
Lo sviluppo di un modello di simulazione in linguaggio Arena, si articola in due fasi sostanzialmente distinte ma interagenti.
Inizialmente è necessario riprodurre fisicamente lazienda attraverso lo sviluppo, appunto, di un modello fisico della stessa. Tale fase comprende la modellazione dei reparti produttivi, con i singoli macchinari e le relative risorse a disposizione. Ogni reparto riceve le entità da processare (secondo i criteri meglio delineati nel modello logco di cui in seguito), esegue le operazioni secondo le modalità ed i tempi indicati dallentità stessa sotto forma di variabili o attributi. Una volta completate le operazioni nel reparto, lentità viene spedita al reparto successivo secondo quanto dettato dal suo ciclo di lavorazione (anchesso meglio descritto nel modello logico).
La seconda fondamentale parte del modello di simulazione è mirato alla fedele riproduzione dellaspetto di gestione logica delle informazioni necessarie utili ai fini dellesecuzione della produzione, quali gestione priorità, regole di instradamento, logiche di schedulazione sulle singole macchine o tra reparti, etc.. .. In questa sezione del simulatore, generalmente più articolata e complessa della prima, vengono gestite, tra laltro, le informazioni riguardanti gli ordini di produzione.
Il modello sviluppato provvede allinvio ai singoli reparti produttivi e/o alle singole macchine le entità da processare fornendo ad ognuna di esse tutte le informazioni necessarie alla lavorazione nel singolo reparto. Ciò avviene attraverso lanalisi di informazioni circa i nuovi ordini, acquisiti tramite lettura dalle porte socket, circa gli ordini in corso di completamento, nonché circa le rispettive date di consegna e delle disponibilità di materiali e risorse, e attraverso una apposita utilizzazione delle informazioni presenti nel database tecnologico del modello.
Al completamento di ciascuna fase produttiva, le entità processate nei reparti produttivi ritornano nel blocco logico dove ne viene aggiornato lo stato di avanzamento; se devono subire ulteriori lavorazioni ricevono, sotto forma di attributi, le nuove informazioni necessarie prima di essere rinviate ai reparti produttivi, altrimenti vanno ad incrementare il contatore dei pezzi completati. Al raggiungimento delle quantità richieste viene generato il messaggio output relativo alle produzioni eseguite.
Il modello prevede anche la gestione del magazzino materie prime, con aggiornamento delle scorte in giacenza e, quando necessario, lemissione di ordini di acquisto ai fornitori.
In realtà il modello Magnaghi Aerospace, oltre al simulatore Arena, prevede per il suo funzionamento, lutilizzo di un database tecnologico, scritto in Access, e di una serie di fogli di calcolo Excel. I moduli realizzati sono integrati tra loro grazie a codici scritti in Visual Basic (VBA) in grado di effettuare la necessaria migrazione dei dati.
Nel database Access possono essere inserite tutte le informazioni relative alle distinte base dei prodotti, nonché i cicli di lavorazione per ognuno dei componenti di tali distinte,
Il database Access viene utilizzato per linserimento delle distinte base relative ai prodotti e dei cicli di lavorazione per ognuno dei componenti presenti nelle distinte. I cicli vengono definiti inserendo lesatta sequenza delle operazioni sulle macchine, indicando le risorse ed i materiali necessari, specificando i tempi ciclo e di setup di ogni operazione.
Sono inoltre presenti le informazioni riguardanti le quantità di materie prime necessarie alla realizzazione dei componenti e i relativi valori di giacenza a magazzino.
Ultima considerazione riguarda il ruolo degli attributi, tipicamente associati alle entità che "fluiscono" nel modello. Con il programma Arena, infatti, il sistema da simulare è descritto in termini di flussi di entità attraverso le risorse. Ad ogni entità è possibile assegnare un certo numero di attributi, che specificano le caratteristiche proprie dellentità stessa quali il tempo necessario per una lavorazione o la data di consegna. E possibile poi definire delle variabili che costituiscono parametri globali del modello, in quanto dipendono dallo stato del sistema (ad esempio il numero di entità presenti in una coda o il tempo corrente del sistema).
Nella sezione logica del modello si gestisce larrivo di commesse con cadenza giornaliera da parte dei clienti, organizzando la produzione secondo la priorità di ciascun ordine.
Linput alla produzione è dato dalla lettura giornaliera del file Piano di Produzione (PP), nel quale sono riportati gli eventuali nuovi ordini in arrivo. In presenza di nuove commesse, viene interrogato il database aziendale, in formato MS Access, dal quale si traggono le informazioni sulle quantità e caratteristiche tecniche di ciascun item della commessa. Se non vi è disponibilità a magazzino,viene emesso il file di testo Ordine di Acquisto (MP) ai fornitori ed in seguito si provvede al riordino ed aggiornamento del magazzino.
Le informazioni di ciascun item della commessa vengono trascritte in due files in formato Excel. Nel primo file, "Elenco Componenti", sono elencati i componenti della commessa e, per ciascuno di essi, le quantità necessarie a soddisfarla.
Nel secondo file, "Fogli di lavoro", sono indicate in ordine sequenziale le lavorazioni che ciascun componente deve subire.
Le entità di ciascun tipo sono generate nelle quantità indicate nella distinta base e vengono inviate alle lavorazioni definite dal proprio foglio di lavoro.
Al termine di ogni lavorazione, ogni entità interroga il foglio di lavoro per conoscere la lavorazione successiva. Il numero di componenti, che hanno completato le lavorazioni, è memorizzato nel file "Elenco Componenti".
Quando viene completata la commessa, viene emesso il file Produzione Eseguita (PE) destinato al cliente.
Il formato dei files PP, PE, MP per lo scambio di informazioni con gli altri componenti della Supply Chain è stato prescelto in modo da essere immediatamente interfacciabile con gli altri simulatori sviluppati dagli altri partners. La logica di funzionamento del modello è riportata nella figura presentata nel seguito.
Il modello realizzato ricalca in maniera abbastanza fedele il funzionamento reale dello stabilimento di Napoli della Magnaghi Aerospace, sia per quanto riguarda la gestione dei flussi fisici (realizzazione dei pezzi) che per laspetto logico di acquisizione delle commesse e di pianificazione degli approvvigionamenti e delle lavorazioni da effettuare.
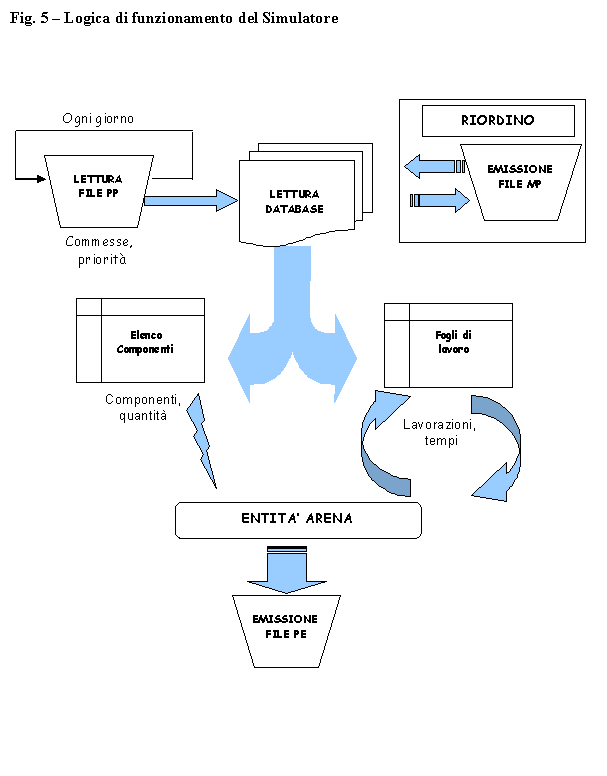
Convalida Sim/Sched di Diverse Realta` Industriali:
Piaggio AeroIndustries, OMA, Geven, Magnaghi, Plyform, Salver, Sirio Panel
DIP, Genova
Passo fondamentale prima di eseguire la convalida di un qualsiasi modello di simulazione è quello di calcolare landamento dellerrore sperimentale. Lerrore sperimentale rappresenta quello che si può definire il "rumore di fondo" del modello, ossia quel distacco fisiologico dalla realtà che si vuole rappresentare dovuto alla stocasticità.
Una qualsiasi estrazione di numeri da una distribuzione dà origine ad una popolazione campionaria che, più il numero di estrazioni è elevato, tanto più tale popolazione risulta simile al campione di partenza.
Le prime estrazioni da una distribuzione potrebbero dare valori ben lontani dalla distribuzione stessa. Il calcolo dellerrore sperimentale (Mean Square Pure Error) consente di visualizzare proprio questa discordanza.
Ciò significa che i primi periodi di una qualsiasi simulazione stocastica daranno sempre valori non significativi della realtà che si vuole rappresentare.
Per evitare quindi di considerare nellanalisi di convalida dati che potrebbero sfasare le osservazioni la letteratura propone diverse alternative. Scuole di pensiero americane vorrebbero assegnare alla simulazione in partenza un periodo di start up del sistema (deciso a priori) in cui non raccogliere dati e iniziare a considerare la storia del sistema dallistante successivo a quello di fine dello start up. Tuttavia questo metodo comporta come inconveniente principale quello di dover stimare a priori il tempo di start up, con conseguente rischio di spreco di dati (e quindi di tempo) o, ben peggio, il rischio di considerare dati validi valori in cui il simulatore avrebbe dovuto ancora assestarsi.
Alternativa alla definizione di un tempo di start up è quella di calcolare, punto per punto, landamento dellerrore sperimentale e vedere in che periodo di tempo si stabilizza. Lerrore sperimentale infatti non sarà mai nullo, o meglio, per tempi di simulazione infiniti esso tenderà a zero: essendo per definizione la simulazione finita, diremo che ciascun simulatore ha un suo errore sperimentale caratteristico, il "rumore di fondo" appunto, sempre diverso da zero. Come gia accennato tale errore ha landamento della classica "curva a ginocchio", ossia elevato nei primi periodi di simulazione, sempre più basso, fino a stabilizzarsi, allavanzare del tempo.
Una volta noto listante di tempo in cui lerrore è considerevolmente basso e stabile, si possono considerare validi i dati da quel punto li in poi.
Definiamo "MSPE", o errore sperimentale, allistante t-esimo la somma dei quadrati degli scostamenti dalla media, di una certa funzione obiettivo calcolata nel tempo t, di ogni singolo lancio di simulazione.
![]()
dove abbiamo:
n: numero di run di simulazione
x(t): valore della variabile x al tempo t del lancio i-esimo
| :valor medio della variabile x al tempo t sugli n lanci |
Occorre innanzitutto definire una funzione obiettivo su cui voler calcolare lerrore, eseguire un numero di lanci sufficientemente elevato per calcolare un valore della varianza significativo e raccogliere per ciascun lancio, per ciascun intervallo di tempo significativo (costante) il valore di tale funzione obiettivo.
Nel nostro caso la funzione obiettivo considerata è stata la produzione di aerei. Avendo in uscita informazioni sulla data di uscita di ogni singolo aereo è stato necessario calcolare, settimana per settimana, un valore cumulativo che rappresentasse il numero di aerei prodotti fino ad un certo punto.
La figura seguente illustra landamento, nellarco del periodo di tempo da noi considerato (156 settimane), della produzione di aerei. Normalizzando questi dati si è ottenuto per ogni settimana, per ogni run, il numero di aerei prodotti per settimana.
Calcolando per ogni run lo scostamento dalla media di questo valore si ha una stima dellerrore sperimentale.
Bisogna osservare che la produzione del nostro simulatore inizia attorno alla 45-esima settimana, questo è dovuto al fatto che i run sono stati fatti partendo da magazzino vuoto e con limpianto completamente scarico.
Landamento dell MSPE che si è in questo modo ottenuto è rappresentato in figura. Come si può notare si hanno due picchi ed un assestamento attorno alla 134-esima settimana. Ciò vuol dire che avrà senso raccogliere dati rappresentativi la produzione di Piaggio dalla 134-esima settimana in poi.
La curva ha inizio dalla settimana 49 in quanto nelle
settimane precedenti la produzione è nulla. Questo perché
si è deciso di partire con il magazzino vuoto e nessun aereo nella
linea di produzione.
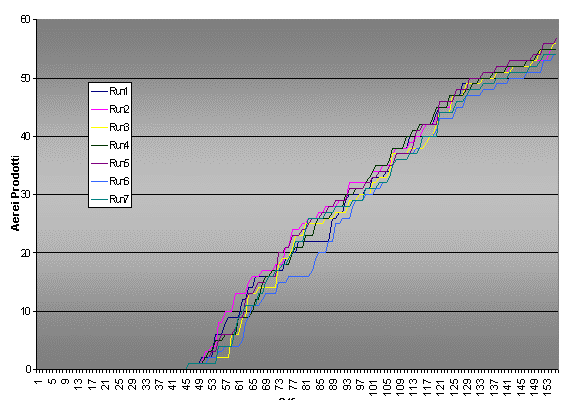
SETTIMANE
Andamento Produzione Piaggio P180
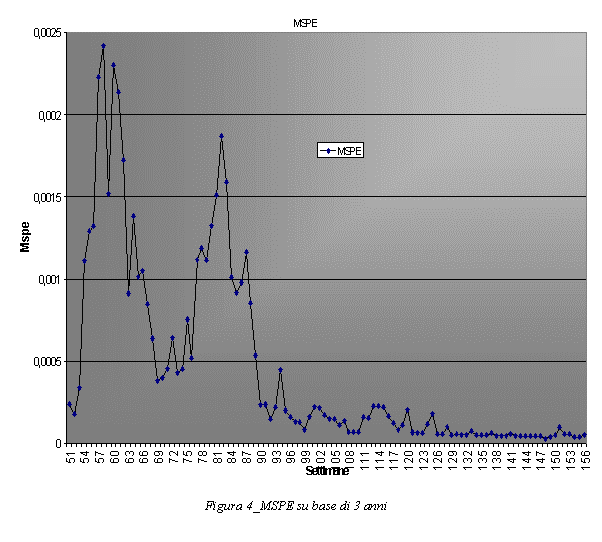
MSpE su base di 3 Anni
DEF, Firenze
La convalida del modello è stata impostata sulla rispondenza tra i Lead Time medi di fornitura rilevati con quelli derivanti dal modello di simulazione. Lanalisi dei LT medi nelle varie fasi del processo produttivo di SP ha consentito di determinare il percorso critico della fornitura, e di concentrare lattenzione sulle fasi appartenenti a tale percorso. Tra queste, quella più critica non risulta interna al processo produttivo di SP, in quanto la realtà produttiva dispone di elevata flessibilità operativa che consente di far fronte a situazioni di massimo carico di lavoro e di saturazione interna dei reparti, avendo da tempo stabilito accordi di outsourcing con fornitori qualificati che operano nelle vicinanze dello stabilimento. Al contrario, le principali criticità di SP sono da ricercare nel contesto dellapprovvigionamento della componentistica elettronica di base, che è gestito in modo centralizzato dal procurement Marconi per tutta le referenze normalizzate in seno al gruppo di appartenenza. Ciò porta a forte variabilità sui tempi di approvvigionamento di determinati componenti, richiedendo una specifica caratterizzazione nel modello di simulazione. Per questa finalità, è stata condotta una analisi dello storico delle forniture dellultimo anno, che ha consentito prima di evidenziare e raggruppare in famiglie la componentistica più critica in approvvigionamento, e di valutare laffidabilità di ciascun singolo fornitore espressa come rispetto delle date di consegna. Questo approccio permette di rappresentare le condizioni di aleatorietà presenti intrinsecamente nel processo di approvvigionamento del codice componente in modo certamente più robusto.
DE, LAquila
I test preliminari di convalida eseguiti con la prima versione del simulatore hanno avuto esito soddisfacente. In particolare si è proceduto alla simulazione di un piano di produzione semplificato che si estendesse per un arco temporale dellordine dei 36 mesi. Si è poi provveduto alla modifica del simulatore per consentirne linterfacciamento con altri simulatori secondo il protocollo HLA e le modalità operative precedentemente sviluppate. Tale modello "HLA compliant" è stato testato con successo in rete locale simulando la ricezione di ordini di produzione provenienti da Piaggio e la loro corretta evasione dimostrandone la possibilità di integrazione allinterno di una federazione dimostrativa che rappresentasse lintera supply chain Piaggio.
Lesperienza maturata nel corso della creazione del modello preliminare, lo stretto contatto con i tecnici OMA ed alcune modifiche gestionali introdotte in azienda hanno tuttavia richiesto successive significative modifiche allimpostazione del modello per renderlo più aderente alla realtà dellazienda alla luce delle seguenti problematiche insorte nella fase di modellazione preliminare:
Le modifiche principali hanno comportato:
La fase di verifica e validazione, sebbene ancora in corso di svolgimento, ha dato già buoni risultati in virtù anche dello sforzo iniziale di riprodurre, il più possibile, in maniera precisa il processo produttivo Geven. In particolare i risultati ottenuti relativi ai tempi di produzione delle commesse Piaggio, rispecchiano in linea di massima i tempi di produzione reali, ciò è stato frutto della scelta di simulare allinterno del modello stesso anche lattesa delle materia prime necessarie alla produzione. Il modello, infatti, opera in fase di lettura dellordine del cliente unesplosione di tutti i componenti di cui il processo produttivo necessita fino alle materie prime. Se tali materie prime non sono disponibili a magazzino emette degli ordini di acquisto nei confronti dei fornitori e mette in attesa tali prodotti. Il modello simula un tempo di attesa per larrivo di questi materiali e, non appena il magazzino viene riempito, sblocca i prodotti e li lancia in produzione.
Tale sistema, come già detto, ha consentito di ottenere una sufficiente corrispondenza tra la produzione simulata e quella reale.
DPGI, Napoli
La fase di sviluppo e realizzazione del modello di simulazione è stata proceduta da numerose visite condotte presso la sede napoletana della Magnaghi Aerospace. Le stesse fasi di sviluppo del simulatore sono state periodicamente accompagnate da visite presso lo stabilimento mirate alla verifica delle assunzioni fatte in fase di realizzazione nonché alla acquisizione di ulteriori informazioni. Lo scopo delle varie viste, durante le quali di aveva modo sia di approfondire alcuni aspetti di carattere logistico e gestionale con i vari responsabili della produzione e della pianificazione, sia di osservare in situ landamento delle varie lavorazioni, era di approfondire ed analizzare attentamente le caratteristiche degli impianti e dei macchinari e di comprendere nel dettaglio i processi produttivi.
Tale studio ha consentito di sviluppare il modello utilizzando blocchi funzionali che rappresentassero limpianto in modo del tutto analogo allo stabilimento reale. Tale corrispondenza è stata realizzata sia in termini di flusso produttivo, sia in termini di layout dellimpianto, ovvero in altre parole si è tenuto conto della specifica realtà produttiva in esame modellando in termini quanto più realistici possibile sia la parte fisica che quella logica. Nel modello sviluppato, il ciclo produttivo allinterno dei diversi reparti ed il flusso logico delle informazioni necessarie alla produzione (lettura distinta base, verifica disponibilità di magazzino, ecc.) seguono in modo stringente le reali fasi produttive della Magnaghi.
La riproduzione per molti versi fedele dellimpianto ha semplificato la successiva fase di raccolta delle informazioni relative ai prodotti realizzati dallazienda per la ditta Piaggio. Nel corso del lavoro di sviluppo del modello si è proceduto allinserimento di un numero limitato di dati nelle varie tabelle descritte in precedenza. In particolare, si è proceduto allinserimento dei dati relativi alla distinta base del carrello del P180 Piaggio, ed ai cicli di lavorazione dei singoli particolari. Per quanto invece riguarda gli altri modelli attualmente in produzione, non si è potuto procedere ad un inserimento esaustivo stante la mole dei dati occorrenti. Ciò non inficia la validità del modello, per due ordini di motivi. Primo, laddove rivolesse far girare il modello avendo a disposizione i dati reali non cè alcun impedimento a provvedervi, in quanto la flessibilità conferita al modello consente qualsivoglia aggiunta o inserzione. Secondo, alfine di simulare in modo corretto la produzione nello stabilimento, si è provveduto ad inserire dati fittizi che riproducessero, in modo semplificato, le operazioni che si svolgono nello stabilimento. La fase di verifica ha consentito di garantire un soddisfacente allineamento tra il processo reale e quello simulato.
DIG, Milano
Il DIG ha curato la convalida del simulatore/schedulatore Plyform. Il modello della realtà Plyform, implementato per la federazione, è stato ufficialmente presentato allazienda nella sua interezza, sia in modalità esecutiva stand alone, sia nellesecuzione di una federazione globale (eseguita localmente). Da questo incontro si è ottenuta la convalida da parte della direzione aziendale delleffettiva corrispondenza tra modello realizzato e logica gestionale perseguita in azienda.
Il modello soddisfa le tempistiche medie di riferimento della produttività aziendale, la logica di gestione degli approvvigionamenti e i criteri di pianificazione di medio e di programmazione operative di breve. Rispetta altresì le procedure di gestione delle urgenze mantenute nelle contrattazioni aziendali ed i criteri di allocazione delle risorse produttive perseguiti in caso di re-scheduling della produzione a seguito di improvvise richieste.
I tempi inseriti sono stati ponderati secondo una valenza percentuale mediamente espressa in un mese di produzione, dato che non sono stati forniti dati di maggiore dettaglio.
La convalida a livello di federazione è stata eseguita secondo le ipotesi limitative del caso di studio progettato, mantenendo come riferimento le indicazione dellazienda Plyform. A tale livello occorre segnalare la discrepanza che si è notata tra le informazioni garantite dal nodo fornitore in confronto a quelle percepite dal nodo cliente, leggibile, ad esempio, nelle date di consegna effettive delle produzioni. La differenza rilevata nelle discussioni è stata comunque attribuita al fatto che le imprese coinvolte sono ancora in fase ampiamente conoscitiva e lo stesso oggetto della produzione (velivolo P180) è tuttora in fase di refining collaborato tra le due aziende. Questa situazione crea da un lato incomprensioni in fase di comunicazione e dallaltro inficia la validità di dati da inserire in un modello decisamente semplificativo della realtà.
Considerando già limplementazione futura richiesta
in WILD , nella quale occorrerà entrare nel dettaglio delle singole
leve operative disponibili in ogni nodo aziendale per assolvere le esigenze
eventuali di ri-pianificazione, è al momento in corso unulteriore
analisi approfondita della realtà Plyform, finalizzata allottimizzazione
dello scheduling locale.
Integrazione Sim/Sched di Diverse Realta` Industriali
DIP, Genova
Il DIP ha svolto il ruolo di responsabile dellintegrazione generale del sistema fornendo supporto alle sedi per procedere nei test complessivi e conducendo ricerche per identificare criteri e metodologie di supporto.
Indici di Performance della Federazione
Dovendo testare un simulatore composto da M federati possono essere molteplici le tecniche.
Si possono individuare coefficienti per la federazione o per il singolo federato. Per quanto riguarda quelli della federazione essi sono utili per testare la velocità di comunicazione della rete utilizzata, quelli su di un singolo federato danno idea dellottimizzazione del federato rispetto gli altri simulatori.
Per valutare le performance gli indici proposti sono:
Naturalmente tali indici verranno calcolati su un set di prove N, numero di replicazioni della simulazione. Ciascuna replicazione dovrà avere gli stessi dati di partenza e dovrà essere eseguita con le stesse modalità.
Performance della Federazione
Si definisce r indice di performance della federazione il seguente rapporto:
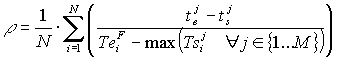
dove definiamo:
N= numero di lanci.
M= numero di federati.
![]() = tempo reale
di fine simulazione per la federazione nel lancio i-esimo.
= tempo reale
di fine simulazione per la federazione nel lancio i-esimo.
![]() = tempo reale
di inizio simulazione per il federato j-esimo nel lancio i-esimo.
= tempo reale
di inizio simulazione per il federato j-esimo nel lancio i-esimo.
![]() = tempo simulato
di fine simulazione per il federato j-esimo.
= tempo simulato
di fine simulazione per il federato j-esimo.
![]() = tempo simulato
di inizio simulazione per il federato j-esimo.
= tempo simulato
di inizio simulazione per il federato j-esimo.
Esso misura quanto tempo si riesce a simulare nellunità di tempo reale.
Se si suppone che un lancio duri 156 settimane al numeratore ci sarà 156-0 cioè il tempo di fine simulazione meno listante iniziale (quasi sempre 0).
Il denominatore di fatto coincide con la durata effettiva della simulazione, infatti non è altro che la differenza tra listante finale della federazione e listante in cui lultimo federato si è unito ad essa.
La funzione che compare al denominatore cioè il ![]() rappresenta listante di inizio della simulazione. In realtà listante
di inizio viene identificato con listante in cui la federazione ha raggiunto
il sincronismo. Ci può essere differenza significativa infatti tra
listante in cui lultimo federato ha preso parte alla federazione e listante
in cui la federazione si è sincronizzata e quindi parte con la simulazione.
Questa differenza se si eseguono lanci in rete locale, o in reti private
è poco apprezzabile ed è quindi corretto stimare listante
di inizio della simulazione con listante di unione dellultimo federato.
Se per la comunicazione avviene usando per esempio internet tale differenza
potrebbe essere significativa, e lo diventa tanto più la durata
della simulazione è breve.
rappresenta listante di inizio della simulazione. In realtà listante
di inizio viene identificato con listante in cui la federazione ha raggiunto
il sincronismo. Ci può essere differenza significativa infatti tra
listante in cui lultimo federato ha preso parte alla federazione e listante
in cui la federazione si è sincronizzata e quindi parte con la simulazione.
Questa differenza se si eseguono lanci in rete locale, o in reti private
è poco apprezzabile ed è quindi corretto stimare listante
di inizio della simulazione con listante di unione dellultimo federato.
Se per la comunicazione avviene usando per esempio internet tale differenza
potrebbe essere significativa, e lo diventa tanto più la durata
della simulazione è breve.
Intervallo di Sincronismo
Come gia accennato la sezione precedente non è detto che listante in cui lultimo federato si unisce alla federazione coincida con listante di inizio della simulazione. Ciò è tanto più vero quanto più è lenta la rete usata come mezzo di comunicazione tra i simulatori. E utile quindi definire un parametro che indichi quando lapprossimazione fatta in precedenza può essere ritenuta valida.
Si definisce intervallo di sincronismo la differenza tra listante di tempo in cui lultimo federato ha preso parte alla federazione e listante di tempo in cui la federazione si è sincronizzata. Questo mediato su N replicazioni può essere scritto come:
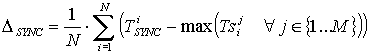
dove :
![]() = istante in
cui la federazione si è sincronizzata nella prova i-esima.
= istante in
cui la federazione si è sincronizzata nella prova i-esima.
E da precisare che ![]() risulta
essere unico per tutta la federazione, quindi si può confondere
con il tempo di sincronismo di un federato qualsiasi.
risulta
essere unico per tutta la federazione, quindi si può confondere
con il tempo di sincronismo di un federato qualsiasi.
Il valore di ![]() tende ad essere tanto più vicino a zero quanto più la comunicazione
tra i federati è efficiente. Ciò dipende non solo dal tipo
di rete utilizzata, ma anche dai parametri di comunicazione definiti dallRTI
(nel file RTI.rid), e dal tick di ciascun federato.
tende ad essere tanto più vicino a zero quanto più la comunicazione
tra i federati è efficiente. Ciò dipende non solo dal tipo
di rete utilizzata, ma anche dai parametri di comunicazione definiti dallRTI
(nel file RTI.rid), e dal tick di ciascun federato.
Nelle prove in locale ![]() ha
un valore inferiore al minuto, per questo spesso verrà trascurato.
Se ciò non fosse, o se il tempo di vita della federazione non fosse
molto maggiore del
ha
un valore inferiore al minuto, per questo spesso verrà trascurato.
Se ciò non fosse, o se il tempo di vita della federazione non fosse
molto maggiore del ![]() , nella
definizione del coefficiente di performance della federazione bisognerebbe
sostituire all espressione
, nella
definizione del coefficiente di performance della federazione bisognerebbe
sostituire all espressione ![]() il valore di
il valore di ![]() .
.
Risulta perciò utile definire un altro coefficiente, che chiameremo coefficiente di sincronismo :
![]() .
.
Esso rappresenta il rapporto tra lintervallo necessario per sincronizzare la federazione e la durata totale della federazione da quando il primo federato si è unito o la ha creata. Questo rapporto deve essere ragionevolmente basso. Valori accettabili per poter considerare lapprossimazione
![]()
sono dellordine di ![]() .
.
Coefficiente di Start up della federazione
Questo parametro risulta strettamente connesso al precedente. Misura infatti lefficienza e la velocità della fase iniziale, di start up, della federazione. Si valuta il rapporto tra la durata totale della federazione e la durata effettiva della simulazione.
Per fare ciò, con più replicazioni, si usano due coefficienti, il primo definito come rappresenta la velocità media della federazione partendo da zero, ossia dallistante di creazione della federazione stessa:
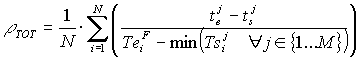
Il secondo è semplicemente il coefficiente di performance della federazione definito in precedenza:
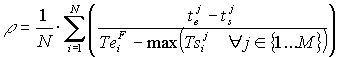
che da la velocità della federazione dallistante
di inizio effettivo della simulazione. Il loro rapporto ![]() fornisce una chiara indicazione di quanto incida il tempo di start up sullintera
simulazione.
fornisce una chiara indicazione di quanto incida il tempo di start up sullintera
simulazione.
Il valore di ![]() risulta
essere inferiore ad 1, ed è tanto più grande quanto più
lo start up è veloce.
risulta
essere inferiore ad 1, ed è tanto più grande quanto più
lo start up è veloce.
Come per lindice di sincronismo il coefficiente di start up è fortemente influenzato dalla durata della simulazione. A parità di tempo di start up più la durata media effettiva della simulazione, definita come :
![]()
è breve, e più il coefficiente si abbassa. Per questo motivo tali coefficienti vanno visti sempre in relazione alla durata media di un lancio.
Performance del singolo federato
Si consideri il simulatore j-esimo. Per valutare quanto esso incide sulla velocità di simulazione dellintera federazione è utile stimare il seguente coefficiente :
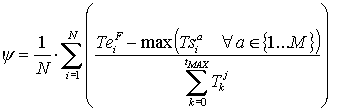
in cui :
N= numero di lanci.
M= numero di federati.
![]() = tempo reale
di fine simulazione per la federazione nel lancio i-esimo.
= tempo reale
di fine simulazione per la federazione nel lancio i-esimo.
![]() = tempo reale
di inizio simulazione per il federato a-esimo nel lancio i-esimo.
= tempo reale
di inizio simulazione per il federato a-esimo nel lancio i-esimo.
![]() = numero di
avanzamenti temporali della federazione.
= numero di
avanzamenti temporali della federazione.
![]() = durata effettiva
della simulazione dello step k-esimo per il federato j-esimo.
= durata effettiva
della simulazione dello step k-esimo per il federato j-esimo.
Il valore di ![]() è
tanto più vicino ad 1 quanto più il federato risulta essere
il collo di bottiglia della federazione, in una federazione di simulatori
perfettamente bilanciata
è
tanto più vicino ad 1 quanto più il federato risulta essere
il collo di bottiglia della federazione, in una federazione di simulatori
perfettamente bilanciata ![]() dovrebbe valere
dovrebbe valere
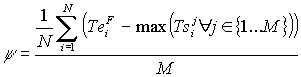
Indici di Affidabilità della Federazione
Oltre alle performance della federazione o dei singoli federati è utile conoscere laffidabilità del sistema. Utilizzando diversi tipi di software che si interfacciano tra loro mediante socket in reti che spesso non sono dedicate può succedere che le comunicazioni vengano interrotte, che la federazione quindi si fermi. I motivi possono essere differenti, elenchiamo in figura le cause principali di interruzione della federazione in un set di 15 prove fatte sia usando Internet che in LAN.
Risulta pertanto indispensabile capire la probabilità di successo del sistema creato, e le possibili cause di insuccesso.
Per fare questo definiamo affidabilità del federato j-esimo il rapporto:
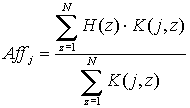
Laffidabilità della federazione viene valutata come di seguito:
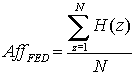
dove ![]() e
e ![]() sono due funzioni cosi
definite:
sono due funzioni cosi
definite:

dove Sj è linsieme dei federati che prendono parte al lancio.
![]()
ed N è il numero di lanci eseguiti.
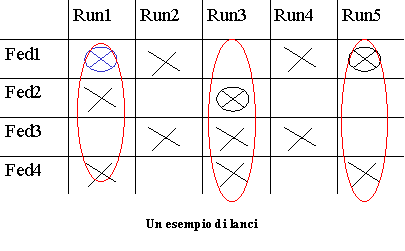
Il rapporto definito risulta quindi il rapporto tra il numero di lanci andati a buon fine sul numero di lanci totali a cui ha partecipato il federato. Per lancio andato a buon fine si intende un lancio in cui la federazione ha raggiunto listante di fine simulazione producendo risultati utili per un analisi statistica. Spesso succede infatti che la simulazione benché raggiunga la condizione finale debba venire invalidata per diversi motivi, tra cui per esempio la mancata ricezione o il mancato invio di oggetti da parte di un federato. Errori di questo tipo si verificano spesso in fase di sviluppo della federazione.
Lesempio, riassunto in figura, mostra una serie di 5
lanci di cui per la federazione solo 2 sono andati a buon fine. Laffidabilità
della federazione è quindi ![]() ,
se si considera però ogni singolo federato laffidabilità
risulta diversa a seconda del numero di lanci a cui il federato partecipa.
Più il numero di lanci è elevato e più il federato
è rappresentativo della federazione. Un federato infatti che avesse
partecipato solo al run2 e al run3 risulterebbe avere affidabilità
unitaria.
,
se si considera però ogni singolo federato laffidabilità
risulta diversa a seconda del numero di lanci a cui il federato partecipa.
Più il numero di lanci è elevato e più il federato
è rappresentativo della federazione. Un federato infatti che avesse
partecipato solo al run2 e al run3 risulterebbe avere affidabilità
unitaria.
Un altro aspetto è che laffidabilità di
un federato risente dellinfluenza di altri federati meno affidabili. Mentre
il sistema infatti si comporta come un sistema meccanico con M componenti
in serie di affidabilità data, per cui allaumentare del numero
dei componenti laffidabilità del sistema scende. Il singolo federato
risente, nel calcolare la sua affidabilità in questo modo, del federato
con affidabilità minore che prende parte al run. Rifacendosi allesempio
riportato il federato 3 non causa mai nessuna interruzione della federazione,
se preso singolarmente sarebbe affidabile al 100%, ma di fatto in questo
set di prove risulta che il federato 3 ha affidabilità ![]() .
.
In un set di prove sufficientemente numerose il federato
con affidabilità più bassa, che abbia partecipato almeno
ai ![]() dei lanci risulta quello
critico per la federazione.
dei lanci risulta quello
critico per la federazione.
Sperimentazione su caso industriale
Sperimentazione
Per compiere un analisi sperimentale sono stati fatti il maggior numero possibile di lanci, sia utilizzando internet (e quindi con i simulatori distribuiti sullarea nazionale), sia in rete locale. Considereremo un set di 15 prove fatte in remoto e di altrettante prove fatte in locale.
Di seguito riportiamo i dati delle prove fatte, per ciascuna prova verrà riportato:
A=la durata della federazione ![]() in minuti
in minuti
B=la durata della simulazione ![]() in minuti
in minuti
G =il tempo di sincronia in
minuti ![]()
se è andata a buon fine
Nelle tabelle seguenti sono riassunte le cause derrore.
| Run | A | B | G | Success | Kind of Error |
| 1 | no | Federatedoesnotrespond | |||
| 2 | 2,5 | no | Javaerror | ||
| 3 | 2,3 | no | JavaError | ||
| 4 | 2,0 | no | RTI internal Error | ||
| 5 | no | SocketError | |||
| 6 | no | SocketError | |||
| 7 | 204,9 | 189,4 | 1,7 | si | |
| 8 | 206,1 | 196,9 | 1,9 | si | |
| 9 | 2,1 | no | SirioPanel caused error | ||
| 10 | 204,3 | 186,2 | 3,2 | si | |
| 11 | 204,8 | 189,0 | 1,0 | si | |
| 12 | 2,2 | no | HumanError | ||
| 13 | 2,4 | no | SocketEror | ||
| 14 | 1,7 | no | RTI internal Error | ||
| 15 | 205,3 | 192,1 | 2,8 | si |
Dati Prove in Internet
| Run | A | B | G | Success | Kind of Error |
| 1 | no | Starting RtIError | |||
| 2 | 0,5 | no | Federate OMA e Geven | ||
| 3 | 1,2 | no | Federate Geven | ||
| 4 | 0,3 | no | RTI internal Error | ||
| 5 | 101,9 | 89,2 | 1,5 | si | |
| 6 | 108,6 | 106,9 | 0,9 | si | |
| 7 | 102,6 | 97,5 | 0,9 | si | |
| 8 | 105,4 | 101,0 | 2,1 | si | |
| 9 | 1,3 | no | Java Internal Error | ||
| 10 | 114,2 | 109,2 | 1,5 | si | |
| 11 | 103,6 | 97,7 | 0,7 | si | |
| 12 | 102,8 | 99,6 | 0,5 | si | |
| 13 | 101,3 | 86,4 | 0,4 | si | |
| 14 | 102,5 | 93,0 | 0,5 | si | |
| 15 | 103,6 | 99,7 | 1,2 | si |
Dati Prove in LAN
Ciascuna prova aveva una durata fissa di simulazione pari a 156 settimane, partendo da zero.
Da questi dati si posso ottenere alcune considerazioni.
Si nota subito che le prove in remoto hanno una durata notevolmente più lunga di quelle in LAN e che il tempo di sincronia per ciascun lancio risulta essere sempre maggiore.
Infatti:
![]()
per il set di prove in locale, mentre risulta pari a 2.14 , cioè più del doppio, per quelle in remoto.
Questo scostamento risulta essere abbastanza normale, infatti nelle prove in remoto le comunicazioni dellrti sono notevolmente più lente (per lo meno in fase di avvio della federazione) per via del routing dei pacchetti che è del tutto assente in locale. In entrambi i casi risulata tuttavia trascurabile rispetto il tempo totale di simulazione, mentre infatti per sincronizzare la federazione si impiega 1, massimo 2 minuti, per compiere la simulazione si impiega un tempo che va da 1ora e mezza alle tre ore.
Si calcolino ora i tre indicatori di performance:
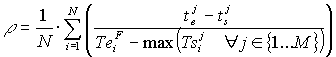
![]()
Nel caso dellutilizzo di internet si ha:
![]()
![]()
![]() .
.
Usando una rete locale invece
![]()
![]()
![]() .
.
Come si nota in entrambi i casi il coefficiente di setup è molto vicino ad uno, questo perché come si è detto prima, la durata complessiva della simulazione è molto più lunga rispetto alla durata dello staurt up. Inoltre facendo le prove in remoto per avviare tutti i federati il tempo necessario viene ad essere più lungo, confrontando i dati si ha infatti una media di 6minuti per avviare tutti i federati in locale e di 14 minuti per avviarli in remoto.
Altre informazioni che si possono ottenere con questi
dati sono circa laffidabilità del sistema e dei vari federati.
Dalle tabelle 5-1 e 5-2 si può vedere che laffidabilità
della federazione risulta ![]() in internet e
in internet e ![]() in locale.
in locale.
Per calcolare laffidabilità di ogni singolo
federato è necessario conoscere a quali prove ha partecipato ciascun
federato. Riportiamo nelle due tabelle seguenti i dati sulla partecipazione
dei federati alla federazione e sullaffidabilità di ciascun federato.
| WAN RUN | Piaggio Genova | Salver | Magnaghi | Plyform | Sirio Panel | Geven | Oma | PiaggioKit | Pratt & Whitney |
| 1 |
|
|
|
|
|
|
|
|
|
| 2 |
|
|
|
|
|
|
|
|
|
| 3 |
|
|
|
|
|
|
|
|
|
| 4 |
|
|
|
|
|
|
|
|
|
| 5 |
|
|
|
|
|
|
|
|
|
| 6 |
|
|
|
|
|
|
|
|
|
| 7 |
|
|
|
|
|
|
|
|
|
| 8 |
|
|
|
|
|
|
|
|
|
| 9 |
|
|
|
|
|
|
|
|
|
| 10 |
|
|
|
|
|
|
|
|
|
| 11 |
|
|
|
|
|
|
|
|
|
| 12 |
|
|
|
|
|
|
|
|
|
| 13 |
|
|
|
|
|
|
|
|
|
| 14 |
|
|
|
|
|
|
|
|
|
| 15 |
|
|
|
|
|
|
|
|
|
| Aff. | 0,33 | 0,42 | 0,31 | 0,36 | 0,33 | 0,36 | 0,33 | 0,38 | 0,25 |
Prove in Internet
| LAN RUN | Piaggio Genova | Salver | Magnaghi | Plyform | Sirio Panel | Geven | Oma | PiaggioKit | Pratt & Whitney |
| 1 |
|
|
|
|
|
|
|
|
|
| 2 |
|
|
|
|
|
|
|
|
|
| 3 |
|
|
|
|
|
|
|
|
|
| 4 |
|
|
|
|
|
|
|
|
|
| 5 |
|
|
|
|
|
|
|
|
|
| 6 |
|
|
|
|
|
|
|
|
|
| 7 |
|
|
|
|
|
|
|
|
|
| 8 |
|
|
|
|
|
|
|
|
|
| 9 |
|
|
|
|
|
|
|
|
|
| 10 |
|
|
|
|
|
|
|
|
|
| 11 |
|
|
|
|
|
|
|
|
|
| 12 |
|
|
|
|
|
|
|
|
|
| 13 |
|
|
|
|
|
|
|
|
|
| 14 |
|
|
|
|
|
|
|
|
|
| 15 |
|
|
|
|
|
|
|
|
|
| Aff. | 0,67 | 0,62 | 0,58 | 0,67 | 0,62 | 0,64 | 0,73 | 0,64 | 0,77 |
Prove in LAN
Da notare come laffidabilità di un federato dipenda
fortemente dal numero di prove da esso eseguite. Un federato che ha partecipato
a poche prove ma tutte con esito positivo avrà affidabilità
unitaria, viceversa un federato con molte prove di cui alcune negetive
avrà affidabilità senza dubbio più bassa.
DEF, Firenze
Il simulatore della realtà produttiva di SP (SirioPanel) è in grado di istanziare gli ordini di lavorazione con il dovuto anticipo, lanciare ordini di acquisto, processare i codici da fabbricare nei vari reparti, seguendo la logica dello shop order. La produzione tra i vari reparti segue quindi una schedulazione basata sul rispetto delle due-date, e non esiste nessuna forma di re-scheduling dinamico (ad esempio, per riprogrammare il lavoro dei reparti in seguito alla presenza di rush-order, piuttosto che per limpossibilità di processare un lotto per assenza di materie prime). Questo rispecchia il modus operandi della realtà descritta, e non è sembrato opportuno introdurre, al momento, forme più raffinate di programmazione della produzione, anche se tali logiche potranno essere sviluppate in seguito nel modello del federato (SP si sta dotando di uno strumento specifico, denominato Skedula per la programmazione operativa della produzione, che consentirà di ottimizzare il sistema in accordo a molteplici obiettivi, anche se lo scopo principale dellintroduzione di questo strumento resta legato a necessità contrattuali, quali garantire la traceability dei lotti di produzione nei reparti e nelle successive spedizioni, comunicare al cliente sullo stato di avanzamento della produzione che lo riguarda).
Per quanto riguarda lintegrazione tra la logica di schedulazione ed il modello di simulazione, occorre evidenziare che lo schedulatore è implementato internamente al modello SiMPLE++, tramite lo sviluppo di specifici metodi (scritti in simscript) che consentono di gestire il dispatching. dellordine di produzione sui rispettivi reparti. Gli ordini di produzione che provengono dal contractor Piaggio sono infatti processati ed elaborati, analogamente ad altri ordini (fittizi), e quindi istanziati in produzione al momento opportuno.
DE, LAquila
Linterazione del simulatore con la realtà aziendale avviene attualmente acquisendo tramite lettura di file esterno proveniente da database Informix in modalità ODBC, loutput dello schedulatore attualmente funzionante in azienda.
Operativamente a valle della pianificazione MRP e della seguente schedulazione (che copre i lanci dei singoli ODL su un orizzonte di circa 24 mesi e che viene aggiornata con la stessa periodicità dello MRP) la OMA interroga il proprio sistema informatico e fornisce una serie di tabelle tipo ODBC create da database Informix e collegate mediante la chiave comune ODL (Ordini di Lavoro), così strutturate:
Tabella ODL
Per tutti gli ODL indica: Identificativo ODL, identificativo PN, quantità, data inizio, data fine, identificazione tipo PN (se trattasi di lavorazione alle macchine o assemblaggio di lamiere o componenti).
Tabella cicli di lavoro
Per tutti gli ODL indica: Identificativo ODL, Sequenza dei centri di lavoro o delle operazioni, tempo setup per ogni centro di lavoro, tempo totale impegno del centro di lavoro per eseguire lODL, date schedulate di inizio e fine.
Tabella prenotazioni
Per ogni ODL indica: Identificativo ODL, e la lista dei figli diretti con indicazione delle relative quantità e data di necessità (data in cui è schedulato linizio assemblaggio).
Tabella centri di lavoro
Per ogni centro di lavoro indica: Identificativo, Turni al giorno, Ore per turno, Ore macchina giornaliere totali, indicazione se presidiato o meno.
Tabella calendari
Calendario macchine presidiate e macchine automatiche non presidiate.
Tali informazioni vengono lette dal simulatore che quindi acquisisce il piano di produzione dettagliato ed elaborato a capacità infinita sulla base del quale esegue la simulazione inserendo i nuovi ordini provenienti dal cliente Piaggio.
Lattività, tuttora in corso e che richiederà una successiva ottimizzazione, ha riguardato lacquisizione dei dati sulla struttura produttiva dellazienda, di pari passo con lo sviluppo del simulatore, la definizione delle modalità di acquisizione dei dati relativi ai jobs da schedulare, la definizione del formato di output del simulatore E anche in considerazione lipotesi di utilizzare direttamente loutput dello schedulatore a capacità infinita esistente al fine di elaborare schedule ottimizzate in alternativa alla schedulazione effettuata direttamente a valle del sistema MRP aziendale.
DIG, Milano
La federazione che è stata realizzata è una parte della catena logistica di Piaggio AeroIndustries S.p.A. dedicata alla produzione del velivolo P180, rappresentata da sei sottofornitori di primo livello, tra di loro indipendenti. La simulazione distribuita realizzata ha soltanto lo scopo di verificare la portabilità e la stabilità della struttura, mentre ogni obiettivo strategico è stato rimandato ai futuri sviluppi del modello.
Ogni azienda della catena è modellizzata in un modello distinto che riproduce la realtà produttiva interna ed i relativi criteri di gestione della produzione. I singoli simulatori cooperano in una sola simulazione distribuita HLA, scambiandosi solo due categorie di informazioni durante il processamento: ordini di produzione (cioè acquisto di componenti da un fornitore) e risposte di produzione eseguita (cioè invio del materiale al cliente).
Lo scambio informativo avviene solo tra Piaggio (cliente main contractor) ed ogni singolo fornitore. Non è invece prevista alcuna comunicazione trasversale tra simulatori al medesimo livello gerarchico.
I federati sono Time Regulating e Time Constrained, con lookahead di default (1 E10-9). Lunità di misura temporale è la settimana. Laggiornamento della produzione effettuata e dei nuovi ordini, avviene con time stamp dellistante di fine settimana, che può anche coincidere, nelle aziende a ciclo continuo, con le ore 00:00 del lunedì successivo. La richiesta di avanzamento del tempo viene fatta, dopo aver localmente simulato lintera settimana e aver pubblicato nuovi oggetti e modifiche a quelli esistenti, per le ore 00:00 del lunedì successivo, (Tfederato_corrente_time = Tfederato_corrente_time +1).
I singoli federati sono stati realizzati ricorrendo a linguaggi diversi di simulazione, che hanno spaziato dai simulatori commerciali più complessi (SIMPLE++ come nel caso di Milano) a linguaggi general purpose comunemente impiegati dai programmatori, dimostrando così leffettiva garanzia di interoperabilità estrema fornita da HLA.
DPGI, Napoli
Come ovvio, vista lobiettivo finale dellintero progetto
di ricerca, il modello Arena dello stabilimento di Napoli della Magnaghi
Aerospace è stato realizzato e sperimentato in vista della sua integrazione
verso lesterno; esso, infatti, è stato predisposto, mediante lutilizzo
di codice Visual Basic, per dialogare con lesterno con qualunque altro
software tramite porte socket.
Sperimentazione su Caso Industriale
DIP, Genova
La sperimentazione sul caso industriale ha previsto lo sviluppo di simulatori ad hoc per limplementazione dei modelli,
Il Funzionamento del GGSimulator
GG è un simulatore ad eventi discreti costruito in java.
Esso integra al suo interno la possibilità di interfacciarsi con il Run Time Infrastructure usando larchitettura HLA. Alla partenza si presentano i 4 pulsanti di scelta:
Option: apre una finestra per linserimento dati in cui poter inserire la data di inizio simulazione (Default: data odierna), lopzione File Trace e la scelta del numero di federati da aspettare durante la creazione della federazione.
Una volta premuto il pulsante RUN si dà inizio alla creazione della federazione ovvero al lancio della simulazione. Avviata la simulazione, apparirà un form con più cartelle al suo interno ed una text area.
La cartella che compare di default è quella in cui si da una rappresentazione del magazzino, item per item vengono elencati tutti i componenti del magazzino e il numero di pezzi presenti in esso. Inoltre da questo frame si può leggere anche a che punto è la produzione, indicata con gli aerei rossi (ordini in caricati, in attesa o in lavorazione), gialli (ordini in lavorazione) o verdi (ordini finiti).
La text area a destra scrive settimana per settimana lavanzamento e le eventuali comunicazioni con lRTI.
A sinistra in basso si può leggere un utile indicazione sullo stato di avanzamento della simulazione, cioè sulla fase in cui la simulazione si trova.
Un'altra cartella è quella relativa agli ordini. In essa si può leggere la lista delle commesse inserite nel sistema, e ordine per ordine si può andare a vedere lavanzamento della lavorazione.
I pulsanti presenti sono i seguenti:

Una volta visualizzato lordine (con il pulsate LOAD) appariranno due tabelle, una che rappresenta lo stato dellordine (attivo, finito dormiente) ed una che visualizza lo stato delle fasi di lavorazione dellordine stesso. In essa si hanno il nome della fase, lo stato, e se necessario, lentità che la sta facendo ritardare, ossia ciò di cui la fase è in attesa, che può essere un suo predecessore, una risorsa, o un pezzo assente a magazzino.
Nel riquadro mostrato in figura, viene rappresentato un GANTT in cui si evidenziano le fasi di lavorazione dellordine scelto.
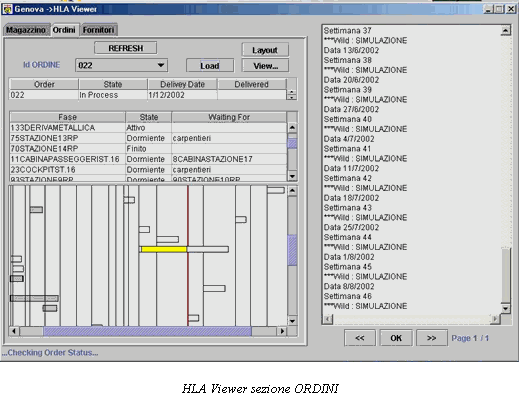
Le fasi rappresentate sono disegnate in giallo (Y) se attive, in grigio (G) se finite e in bianco (B) se in attesa. Con il pulsante VIEW si aprirà una schermata che in 3D renderà un idea dello stato di avanzamento dellordine, finché lordine non è finito non sarà visualizzato laereo intero, ma solo le componenti finite realmente. Unaltra cartella è quella riguardante i fornitori. In essa si può avere un elenco dei fornitori interessati, scegliere un fornitore e in qualsiasi istante avere un elenco degli ordini lanciati, di quelli consegnati e del ritardo di consegna.
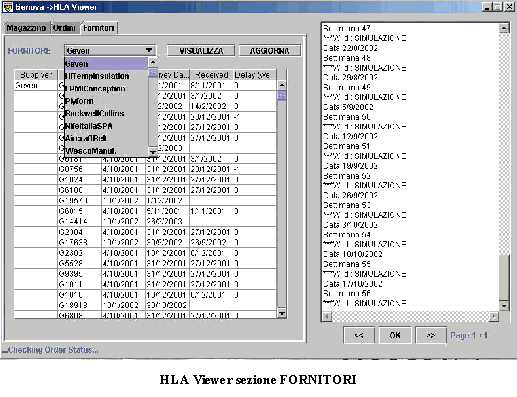
I pulsanti sono i seguenti:
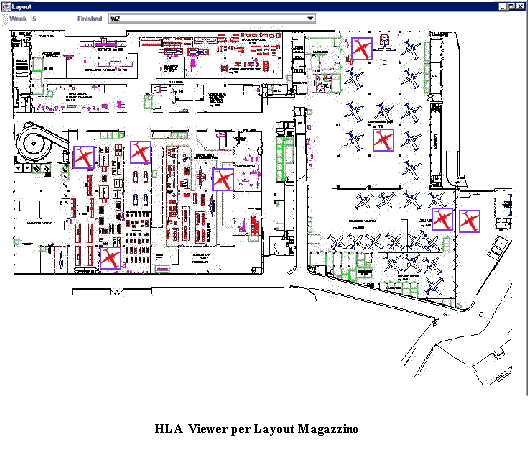
DEF, Firenze
Con il simulatore/schedulatore della realtà SP sono state realizzate varie esperienze di simulazione distribuita, tramite la creazione di specifiche federazioni. La robustezza dellarchitettura è stata verificata mediante prove congiunte fra le varie sedi coinvolte nel progetto. Sono stati effettuati vari test su WAN (rete geografica) che su LAN (rete locale). I test su WAN hanno mostrato una certa instabilità nellarchitettura, imputabili a non comprovate inefficienze della rete internet ed a errata configurazione dei parametri di settings del RID file, certamente problemi esogeni al progetto e/o facilmente risolvibili, mentre i test in rete LAN sono più volte riusciti. Da questa ultima serie di prove si evince una certa stabilità che deve comunque essere migliorata con l'approfondimento della serie di test.
In definitiva, le prove hanno comprovato la bontà
dimpiego dell'architettura HLA per la simulazione distribuita, anche su
rete geografica estesa.
DE, LAquila
Al fine di sperimentare in un ambito realistico il modello di simulazione sviluppato, con lintento di verificare la corretta interazione con altri simulatori, è stata concordata con le altre unità di ricerca la creazione di una federazione dimostrativa di simulatori che riproducesse la catena logistica della Piaggio Aero Industries (main contractor). Oltre alla OMA (associata come detto alla Unità di Ricerca dellUniversità di LAquila), la supply chain risulta composta dalle seguenti entità produttive: Piaggio Aero Industries Stab. Genova, Piaggio Aero Industries Stab. Finale, Geven, Magnaghi, Plyform, Sirio Panel, Salver, in cui figurano subfornitori del main contractor su due distinti livelli.
Le specifiche per la costruzione della federazione dimostrativa sono state emanate a seguito di una riunione tenuta il 3 aprile 2001 presso il Politecnico di Bari ed hanno previsto limpiego di due tipologie di oggetti differenti formalizzati in due classi distinte: oggetto "Ordine" ed oggetto "Prodotto Finito". Loggetto Ordine rappresenta lordine di produzione emesso dal cliente verso il suo fornitore; loggetto Prodotto Finito rappresenta il prodotto consegnato dal fornitore al proprio cliente.
Il processo di outsourcing-subfornitura viene simulato ricorrendo ad HLA mediante la registrazione da parte del cliente di un oggetto di tipo Ordine verso il fornitore che appena ricevuta notizia dellistanza predispone il proprio processo produttivo per la fornitura generando eventualmente un ordine interno di produzione.
Nel momento in cui il fornitore ha completato la produzione di quanto richiesto dal cliente registra un oggetto Prodotto Finito che riporta nei suoi attributi, il riferimento allordine del cliente e che ha una quantità che dovrebbe essere pari a quella richiesta dal cliente. In caso di ordini evasi parzialmente si registreranno tanti oggetti Prodotto Finito quanti saranno gli eventi di consegna caratterizzati dallo stesso riferimento allidentificativo ordine. A produzione eseguita il cliente cancella listanza della consegna Prodotto Finito, provvede ad aggiornare la propria situazione di magazzino e cancella lordine di approvvigionamento relativo avente lo stesso codice identificativo.
La sede di LAquila ha dunque provveduto alla modifica del simulatore OMA precedentemente sviluppato e testato in rete locale, per adeguarlo alle nuove specifiche. E stato anche implementato un processo di cifratura/decifratura, con algoritmo cifrante a sostituzione multipla fornito dalla sede di Genova, operante su alcuni attributi sensibili degli oggetti (nome, quantità, data e codice identificativo) al fine di garantire la riservatezza delle comunicazioni tra cliente e fornitore
DIG, Milano
Tale attività è stata realizzata mediante prove congiunte fra tutte le sedi universitarie coinvolte nel progetto: la federazione Piaggio è stata eseguita più volte per un orizzonte temporale di simulazione di 156 settimane (pari a 3 anni di produzione) e si sono raccolti dati circa la sua stabilità ed elaborazione.
Sono stati effettuati vari test sia in rete geografica WAN, sia in rete locale LAN. La procedura di testing si è rivelata lunga e laboriosa, date le problematiche evidenti di coordinamento esistenti in situazioni geograficamente distribuite, ma anche per la stessa complessità delle fasi di avvio di ogni singolo simulatore federato. La complessità del dover gestire fino a 7 calcolatori in rete WAN è stata in parte aggravata dal fatto che i simulatori impiegati sono stati di ben 4 tipologie differenti, a prova delleffettiva integrabilità che HLA permette.
I test della federazione in rete WAN condotte dal Politecnico hanno mostrato una certa instabilità nellarchitettura, non permettendo di raggiungere la clearance obiettivo, ottenibile dopo tre tentativi di simulazione consecutivi di intervallo temporale di 156 settimane giunti a buon fine. Linstabilità riscontrata pare, comunque, che possa essere sostanzialmente imputata ad erronee operatività umane e a non meglio comprovate inefficienze nel settaggio dei parametri di federazione presenti nel file RID di RTI.
I test della federazione in rete LAN sono invece più volte riusciti, salvo lievi problemi con alcuni simulatori non progettati secondo le specifiche e non del tutto funzionanti nei rispettivi proxy per HLA. Il simulatore Plyform ha terminato le proprie elaborazioni in maniera corretta tutte le volte, sia impiegando il Java Proxy redatto con Firenze che adoperando un sistema, denominato Delegated Simulator, creato dalluniversità di Genova.
La serie di prove realizzate permette di evincere conclusioni di carattere meramente tecnico, obiettivo effettivo del lavoro finora illustrato. Presentiamo queste considerazioni in forma puntuale, al fine di darne il merito opportuno.
Futuri sviluppi del progetto (i.e. Progetto WILD) sono indirizzati allutilizzo della federazione come strumento di problem solving. In questottica, oltre a risolvere i problemi ancora presenti nei confronti di HLA, si deve per lappunto procedere allo sviluppo di nuovi modelli simulativi delle realtà aziendali, più fedeli rispetto agli odierni alla SC di Piaggio. Come già descritto, questo significa dover implementare nei modelli una schedulazione della produzione più realistica di quella implementata al momento e, parallelamente, modificare il vocabolario che sintende condividere nella federazione (SOM).
DIMEC, Salerno
Il modello Arena riguardante lazienda Geven è stato realizzato e sperimentato pensando allintegrazione verso lesterno; esso, infatti, è stato predisposto, mediante lutilizzo di porzioni di codice Visual Basic e di "blocchi VBA" (moduli inseriti direttamente nel modello di simulazione) che attivano il codice medesimo, per dialogare con lesterno con qualunque altro software che disponga di porte di comunicazione compatibili con il protocollo TCP/IP (porte socket).
Le informazioni scambiate dal modello, attraverso le suddette porte di comunicazione, sono essenzialmente di tre tipologie diverse: informazioni riguardanti gli ordini di produzione, ricevute ed inviate dal modello, quelle riguardanti le conferme di produzione eseguita, anchesse inviate o ricevute, e le informazioni riguardanti la sincronizzazione del tempo.
Al fine di sperimentare il funzionamento delle porte Socket e lo scambio delle informazioni è stato sviluppato un piccolo software che emulasse la porte di comunicazione del software per il collegamento. Grazie a questo software, sono state sperimentate in locale le connessioni, tutte le informazioni scambiate ed i messaggi di sincronizzazione. Una volta risolti tutti i piccoli problemi di comunicazione, il passo successivo è stato la realizzazione dellintegrazione con il software di collegamento con lambiente HLA.
Lintegrazione con larchitettura HLA è stata realizzata grazie alla collaborazione con il DIP -Università di Genova- la quale ci ha fornito uninterfaccia, sviluppata in linguaggio Java, che si occupa di utilizzare tutte le funzioni messe a disposizione dallambiente HLA, di convertire i dati scambiati con lHLA e di inviarli alle porte Socket.
La collaborazione si è svolta personalizzando linterfaccia Java al fine di poterla utilizzare con il modello Geven, compito svolto dal DIP di Genova; il modello Geven, invece, è stato modificato aggiungendo una nuova porta socket, in aggiunta alle due già esistenti, per rendere possibile il dialogo completo con lapplicazione Java.
Il modello Geven, integrato HLA, è stato eseguito in rete locale in collegamento con il modello di simulazione Piaggio predisposto dallUniversità di Genova. La simulazione si è svolta in modo corretto, infatti, il modello Piaggio ha inviato gli ordini di produzione al suo fornitore Geven, il quale ha realizzato tali ordini ed ha inviato le conferme di produzione eseguita a Piaggio che ha ricevuto il materiale prodotto.
Durante lo svolgimento delle prove è emersa la necessità di realizzare alcune modifiche al modello Geven relative alla gestione dei Piani di produzione; infatti, Piaggio ha inviato, ad ogni inizio anno, tutte le richieste di produzione relative allanno in corso con le relative scadenze, per cui il modello Geven doveva essere in grado di congelare alcuni ordini fino al raggiungimento della data di lancio in produzione.
La sincronizzazione del tempo, aspetto critico del funzionamento dei simulatori distribuiti in rete, tra i modelli appartenenti alla federazione, è stata svolta con cadenza settimanale; lintervallo di sincronizzazione scelto, non preclude comunque la possibilità di poter modificare il periodo di riferimento, sia in maniera fissa, sia in modo variabile durante la simulazione. Infatti il modello Geven, ogni qual volta avviene la sincronizzazione, riceve in input il tempo di delay per il prossimo appuntamento e, quindi, operando unopportuna gestione in ambiente HLA, tale tempo può essere modificato di volta in volta durante lesecuzione della simulazione.
Infine, il modello integrato è stato eseguito in
rete geografica in federazione con il modello Magnaghi, predisposto dallUniversità
di Napoli, e con il modello Piaggio, ciascuno in esecuzione presso la propria
sede Universitaria. La simulazione si è svolta in modo corretto
evidenziando lesattezza dei dati scambiati e lefficienza dellarchitettura
HLA in unione con il modello di simulazione sviluppato.
Network di Simulatori e Schedulatori
Questo processo presiede all'interazione del simulatore con il resto della federazione. Tra le specifiche del progetto è previsto uno scambio di dati che comprende, tra gli altri, anche delle stringhe (codici identificativi dell'unità produttiva, tipologia dei prodotti e quantità). Questa specifica non può essere direttamente implementata, poiché il linguaggio SIMAN (utilizzato in Arena) non riconosce le stringhe. Sarà quindi compito dell'Ambassador provvedere alla conversione delle stringhe in numeri, per gli aggiornamenti in ingresso, e dei numeri in stringhe per gli aggiornamenti in uscita. E' inoltre previsto che l'Ambassador memorizzi, in opportuni files, tutti i dati in ingresso ed in uscita.
A seconda delle specifiche del modello di simulazione sono stati implementati due tipi differenti di Ambassador.
Il primo scambia informazioni tramite socket, sia in ingresso che in uscita linterfaccia in java comunica con i simulatori in Arena e in Simple scambiando stringhe su porte socket.
Il secondo scambia dati con Arena anche utilizzando file. In particolare nel caso del simulatore di Magnaghi, gli ordini entranti vengono letti, ogni settimana, dal simulatore da un file PianoDiProduzione.txt. LAmbassador quindi non fa altro che scrivere su questo file gli ordini ricevuti dalla federazione.
Per quanto riguarda gli eventi di pubblicazione in federazione, l'Ambassador riceverà, in base al servizio richiesto, una stringa da un socket contenente l'aggiornamento, provvederà alla conversione delle stringhe, salverà permanentemente (in un file di "log") loggetto da pubblicare e quindi trasmetterà l'aggiornamento in federazione. Per quanto riguarda gli eventi di aggiornamento dalla federazione, l'Ambassador provvederà sia a salvare permanentemente i nuovi dati, sia a convertirli per poi metterli, momentaneamente, in un file per ARENA.
LAmbassador è perennemente collegato con la federazione e mantiene gli aggiornamenti per il simulatore. Il comportamento dell'Ambassador può essere assimilato a quello di un server.
Connessione tra Interfaccia Arena e Ambassador
Dovendo risolvere il problema di mettere in comunicazione il simulatore, per mezzo di codice scritto in Visual Basic, e l'Ambassador scritto in Java, è stata implementata una trasmissione che utilizza il protocollo TCP/IP.
In particolare è stata implementata una struttura che prevede, per l'Ambassador, una funzionalità da server. L'Ambassador è infatti sempre collegato con la federazione e può esserne considerato il tramite a cui rivolgersi per emettere e ricevere dati. L'Ambassador andrà ad interrogare ciclicamente, tramite funzioni che fanno sì che non rimanga in attesa della connessione (accept()), la porta dedicata alla trasmissione dei dati con la Arena o con Simple++. Nel momento in cui viene verificata la presenza di un tentativo di connessione; l'Ambassador provvederà a rendere disponibile o acquisire i dati del simulatore. Poiché è prevista un'interrogazione ciclica della porta da parte dell'Ambassador; la Visual Basic, nel momento in cui viene ad essere chiamato da Arena, non dovrà fare altro che tentare di connettersi con il server (assumendo quindi un tipico comportamento da client).
Le porte socket aperte per ogni simulatori sono 3. Una per la trasmissione dei dati dal simulatore allAmbassador, una per la trasmissione dei dati dallAmbassador al simulatore ed una per gestire il tempo del simulatore.
Il problema della sincronizzazione, di cui si parlerà dopo, è infatti stato risolto mettendo in pausa il simulatore finche lAmbassador non ottiene dalla federazione il TimeGrant. Ottenuto il permesso di avanzare di una settimana lAmbassador comunica al simulatore di procedere di 7 giorni tramite la spedizione di una stringa (contenente il tempo di avanzamento).
Per la creazione della federazione e la partenza della simulazione si è reso indispensabile un protocollo di sincronizzazione tra i federati. Il maincontractor, rappresentato dal simulatore di Piaggio a Genova, sarà il federato che aspetta gli altri. Prima della creazione della federazione è infatti possibile introdurre il numero di federati da aspettare. Appena creata la federazione, Piaggio lancia un "blocco di sincronia", aspetta che arrivino tutti i federati richiesti, dopodiché consente linizio della simulazione.
Per avviare gli altri federati ci sono diverse procedure a seconda del tipo di simulatore con cui è stato implementato il federato. In generale si deve aprire il tool di simulazione usato (Arena o Simple++), caricare il modello, aprire le porte socket in ascolto (questa operazione per alcuni modelli è automatica, per altri basta dare il "run" alla simulazione), aprire linterfaccia in java con lRTI, connettere le due entità (con il pulsante connettiti dellambassador), e dare il run allambassador.
Cerchiamo di capire cosa accade, in dettaglio, quando è mandato in esecuzione un modello. Il flusso desecuzione di un modello è condizionato dagli eventi; rappresentando questi un istante di tempo in cui termina o ha inizio unattività. Un evento può produrre in generale:
Un aggiornamento delle variabili.
Un aggiornamento degli accumulatori statistici.
Unalterazione degli attributi delle entità.
La registrazione di un nuovo evento nel calendario.
Durante lesecuzione una simulazione deve essere a conoscenza degli eventi che si verificheranno in futuro. Questo tipo di informazioni sono registrate nel calendario degli eventi e gli oggetti in esso contenuti sono chiamati record.
Poiché la gestione del tempo da parte dei simulatori avviene in stretto rapporto con il calendario degli eventi, entriamo maggiormente in dettaglio sullargomento. Ogni record contiene le seguenti informazioni:
Lidentificativo dellevento in questione.
Il tempo in cui levento sarà processato.
Che tipo di evento sarà.
Nel momento in cui viene prodotto un nuovo evento è compito del simulatore ordinarlo temporalmente nel calendario. Per quanto riguarda la gestione del calendario, quando si raggiunge listante di tempo a cui corrisponde un nuovo evento da processare, il record corrispondente viene rimosso e le informazioni in esso contenute vengono utilizzate per seguire unappropriata logica.
Differentemente dal real-time, il simulation clock dei simulatori non fluisce continuamente attraverso tutti gli istanti di tempo, bensì avanza "bruscamente", dal tempo legato ad un evento, al tempo del successivo evento da schedulare. Poiché niente cambia fra gli eventi, non cè necessità di sprecare il tempo (reale) di chi osserva la simulazione (tempi simulati).
Nei tool di simulazione da noi usati è sempre possibile accedere alla variabile che indica listante di tempo in cui è la simulazione.
È perciò possibile sincronizzare I vari simulatori facendo uso dellambassador.
Rivolgiamo lattenzione al problema di effettuare lo scambio di dati in federazione per mezzo di un protocollo in grado di garantire una sincronizzazione temporale tra ARENA o SIMPLE++ ed il suo Ambassador.
Parleremo più nel dettaglio del caso di simulatori sviluppati con ARENA, sia per semplicità di discorso, sia perchè le stesse considerazioni possono essere fatte per i simulatori di SIMPLE++.
Trattiamo inizialmente il problema dellacquisizione di oggetti dalla federazione. Considerandola come unipotesi iniziale, assumiamo che I simulatori ricevano solamente oggetti, ma non li pubblichino. Una volta risolto il problema della sincronizzazione per lacquisizione di oggetti, si procederà con linserimento anche degli eventi di pubblicazione tra quelli possibili.
Poiché ARENA non è sensibile ad eventi esterni che vadano ad interrompere il flusso della simulazione, lunica soluzione è rappresentata dallinterrogazione ciclica dellAmbassador, da parte di ARENA, per acquisire nuovi eventi. Infatti se da un lato ARENA non è sensibile ad eventi provenienti dallesterno lAmbassador lo è. Sarà quindi compito dellAmbassador registrare i nuovi oggetti nel momento in cui vengono forniti dalla federazione per poi renderli disponibili ad ARENA. Per quanto riguarda la ricezione di nuovi eventi, lAmbassador non deve far altro che esprimere il proprio interesse agli aggiornamenti per mezzo del metodo di interfaccia subscribeObjectClassAttributes(); sarà lRTI a notificare gli aggiornamenti per mezzo della callback reflectAttributeValues().
Nel tentativo di mantenere una certa generalità
nel discorso assumiamo che ARENA acquisisca gli aggiornamenti dalla federazione
ad intervalli di tempo ![]() (vedi figura). Linterrogazione ciclica dellAmbassador viene realizzata
in ARENA per mezzo di un ciclo che prevede un blocco DELAY[1] e dei blocchi
EVENT necessari per la richieste da inoltrare allAmbassador.
(vedi figura). Linterrogazione ciclica dellAmbassador viene realizzata
in ARENA per mezzo di un ciclo che prevede un blocco DELAY[1] e dei blocchi
EVENT necessari per la richieste da inoltrare allAmbassador.
Poiché il nostro obiettivo è la sincronizzazione di un simulatore per la gestione della produzione, leventuale ritardo nellacquisizione di un nuovo oggetto dalla federazione non comporta alcuna criticità nel sistema.
Andiamo quindi a sviluppare una soluzione per la sincronizzazione tra ARENA ed Ambassador nel caso di sola acquisizione di oggetti dalla federazione. Supponiamo che inizialmente ARENA ed il suo Ambassador si trovino sincronizzati sullo stesso istante di tempo ta.
Tale assunzione non fa perdere di generalità alla soluzione. Andremo a dimostrare che uno stato con entrambi i processi sincronizzati viene raggiunto al termine di ogni attività, in conseguenza ad un evento che richiede linterazione con lAmbassador da parte di ARENA. Vediamo quindi come gestire il successivo evento presente in calendario. Quando ARENA arriva a gestire levento sopra citato ha raggiunto listante di tempo tb, mentre lAmbassador è rimasto allistante di tempo ta.

Conseguentemente ad un richiesta di ARENA, lAmbassador emette un timeAdvanceRequest() al tempo tb e si mette in attesa del timeGrant. Una volta che gli viene restituito il timeGrant lAmbassadorr notifica la presenza di eventuali nuovi oggetti e restituisce il controllo ad ARENA. Ricordiamo che la modalità di processo dellRTI, in conseguenza ad un timeAdvanceRequest(), prevede la restituzione di un timeGrant al tempo richiesto, nel momento in cui viene assicurato che non sarà prodotto nessun nuovo aggiornamento con tempo inferiore.
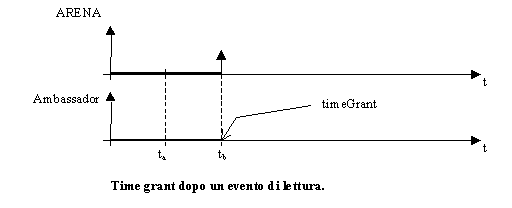
Utilizzando il metodo timeAdvanceRequest() lRTI non fornirà in nessun caso un timeGrant inferiore a quello richiesto.
LAmbassador rimarrà quindi in attesa della callback timeAdvanceGrant() e non restituirà il controllo ad ARENA finche non verrà fornito un timeGrant esattamente pari a tb.
Abbiamo quindi dimostrato che i due processi rimangono sincronizzati nellipotesi di sola acquisizione di nuovi oggetti dalla federazione.
Andiamo ora a descrivere il protocollo di sincronizzazione per gli eventi di scrittura, mantenendo immutato quanto sino ad ora detto. Saranno descritti due casi.
Il primo prevede un evento di scrittura che si verifica ad un tempo maggiore del time grant più il lookahead; il secondo prevede un evento di scrittura che si verifica ad un tempo minore del time grant più il lookahead.
I due casi che andremo a trattare comprendono tutti i casi possibili. Supponiamo che entrambi i processi si trovino sincronizzati allistante di tempo tb. Come caso generale andremo a considerare un evento di scrittura, presente nel calendario degli eventi, con un tempo maggiore del timeGrant più il lookahead[2]
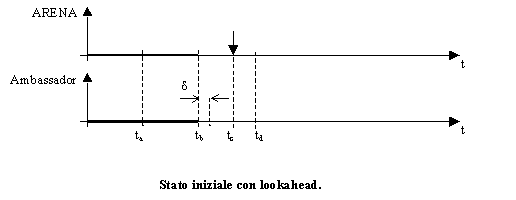
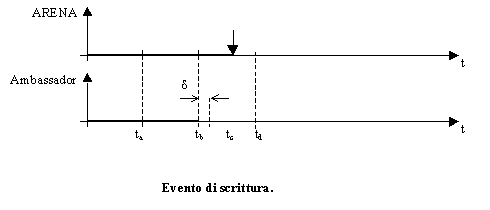
La notifica allAmbassador dellintenzione di pubblicare un nuovo oggetto in federazione avviene, in ARENA, per mezzo di un blocco EVENT.
Nel momento in cui ARENA processa levento di scrittura, si trova allistante di tempo tc mentre lAmbassador si trova ancora allistante di tempo tb.
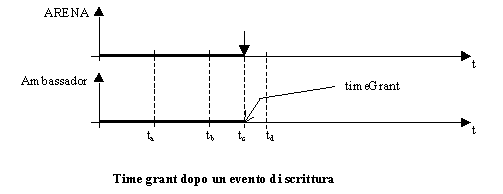
Quando lAmbassador riceve una richiesta di pubblicazione in federazione, avendo precedentemente utilizzato i metodi publishObjectClass() e registerObjectInstance() per notificare alla federazione le proprie intenzioni di pubblicare oggetti, emette un updateAttributeValues() al tempo tc ed immediatamente dopo un timeAdvanceRequest() al tempo tc.
Come per il caso dellacquisizione di nuovi oggetti, il controllo non viene restituito ad ARENA finche il timeGrant non è esattamente pari a tc. Precisiamo che se, successivamente al timeAdvanceRequest(), si verificano trasmissioni di nuovi oggetti in federazione, la callback reflectAttributeValues() provvederà a registrare i nuovi eventi; che verrano letti alla successiva richiesta da parte di ARENA.
Per completare il discorso sulla sincronizzazione ci rimane da trattare il caso in cui levento di pubblicazione si presenta in un istante di tempo tc minore timeGrant più il lookahead. In questo caso lAmbassador pubblicherà il nuovo oggetto in federazione con un tempo pari al timeGrant più il lookahead, ma non emetterà il timeAdvanceRequest() al tempo sopra citato.
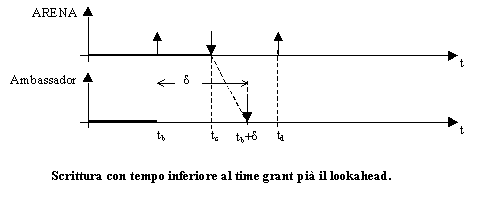
Il timeAdvanceRequest() non viene emesso poiché non è possibile assicurare che nessun altro evento venga prodotto, da parte di ARENA, in un istante di tempo inferiore al timeGrant più il lookahead. Il timeAdvanceRequest() verrà invece richiesto ad un successivo evento di lettura di nuovi oggetti oppure ad un evento di pubblicazione con tempo oltre il timeGrant più il lookahead (nellesempio in esame loggetto verrà pubblicato con il tempo tb+d ).
Dovendo convalidare un modello di simulazione di uno stabilimento, sono diverse le alternative possibili. Nel caso più semplice in cui il modello viene fatto per consolidare una situazione reale gia esistente la migliore convalida è quella con i dati reali forniti dallazienda. Purtroppo non sempre si dispongono di questi dati. La simulazione viene spesso usata per testare nuove possibilità produttive, nuove alternative alla situazione gia in essere. In questo caso è chiaro che non si può disporre di un set di dati reali con cui confrontare il modello. Per questo si fa uso spesso di "metamodelli" sperimentali. Data cioè la realtà aziendale si crea un modello a parte che rispecchi il più possibile i dati forniti, questo modello verrà utilizzato come confronto per la simulazione generale.
Un simulatore composto da più federati ha molte più difficoltà di convalida. Per molti aspetti le tecniche di base di V.V.&A. possono essere applicate anche in questo caso. Il problema fondamentale è che per la simulazione dellintera federazione le comunicazioni sono affidate ad una rete che spesso può causare inaffidabilità e quindi perdita dei dati.
Per convalidare la federazione, supposto che ogni singolo simulatore sia convalidato per quello che riguarda la linea di produzione simulata, la metodologia proposta è proprio quella di usare un metamodello stand-alone che rappresenti limpianto e le sue relazioni con i fornitori per esempio (se la federazione simula la supply chain dellazienda).
DE, LAquila
Predisposti presso le singole sedi partecipanti alla ricerca i simulatori da utilizzarsi per la realizzazione di una federazione dimostrativa rappresentativa di una supply chain complessa, ne è stata implementata la messa in rete.
La modalità di esecuzione della federazione ha previsto federati di tipo Time Regulating e Time Constrained, con lookahead di default (1 E10-9). Lunità di misura temporale è stata assunta pari alla settimana e si è concordato laggiornamento della produzione effettuata e dei nuovi ordini con timestamp dellistante di fine settimana. La richiesta di avanzamento del tempo viene fatta quindi dopo aver localmente simulato lintera settimana ed aver pubblicato nuovi oggetti e modifiche a quelli esistenti, per le ore 00:00 del lunedì successivo.
Limplementazione di un punto di sincronizzazione si è reso necessario per permettere a tutti i componenti della simulazione distribuita di partire contemporaneamente. Per quanto riguarda il simulatore OMA, poiché fornitore, si è resa necessaria esclusivamente limplementazione di una struttura che prevedesse:
In data 23 Maggio 2001 è stata eseguita con successo una simulazione completa con tutti i componenti della federazione in modalità distribuita su wide area network (interconnessione dei simulatori operanti presso le diverse sedi mediante rete internet). In particolare è stato simulato un periodo di 156 settimane in 4 ore. La simulazione è stata eseguita mediante lutilizzo di un modello dellazienda OMA sviluppato dalla sede di LAquila.
Nelle 156 settimane di simulazione sono stati gestiti 11 nuovi ordini di produzione relativi ai componenti che la OMA realizza per il main contractor Piaggio. Allinterno del modello i nuovi ordini si andavano ad integrare con la normale produzione dellazienda in oggetto come previsto dal piano di produzione precedentemente elaborato.
Al termine delle 4 ore è stata eseguita la validazione della simulazione mediante comunicazione verbale con il main contractor (Genova). La validazione ha riguardato lintero ciclo di vita dellordine, dalla registrazione fino alla cancellazione includendo loggetto produzione eseguita, e la stabilità dellintero tool volto alla realizzazione dellintegrazione. Si è altresì rilevata la possibile vulnerabilità del sistema ad interruzione del collegamento Internet dovute a scarsa affidabilità della rete utilizzata per lo scambio dati.
Il test si è concluso con successo dimostrando la fattibilità della realizzazione di una federazione di simulatori indipendenti e geograficamente distribuiti cooperanti nella simulazione del funzionamento di una supply chain complessa con riferimento ad un caso industriale realistico.
DIMEG, Bari
La procedura sviluppata dallunità di ricerca del Politecnico di Bari per lintroduzione del proprio "modello locale" nella federazione è basata sullimpiego di un modulo base in codice Java in grado di far scambiare informazioni in ambiente HLA ad un modello di simulazione realizzato in ARENA®.
Il modulo in Java è costruito secondo unarchitettura ad oggetti basata sulle librerie allegate al package RTI13java1. Il modulo è in grado di comunicare con il modulo di gestione della federazione del package RTI13java1 per la gestione delle seguenti funzioni:
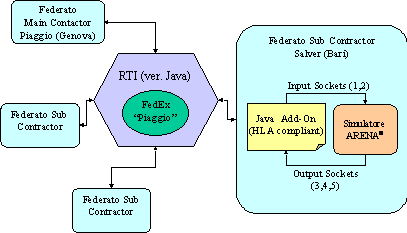
Integrazione in ambiente HLA del modello di simulazione "Salver"
Il modulo in codice Java comprende istruzioni di controllo della trasmissione dati che definiscono "sockets" distinte per linvio al modello di simulazione dei dati di input e la ricezione dei dati di output. Il codice VBA di ARENA® prevede istruzioni di controllo della trasmissione dati che utilizzano le medesime "sockets" ma con funzione inversa: le "sockets" di output del modulo in Java sono di input per il simulatore ARENA® e le "sockets" di input del modulo in Java sono di output per il simulatore ARENA®.
Per il modello "Salver" sono state utilizzate 5 "sockets" per la comunicazione dei dati necessari sia al controllo del federato SALVER sia del suo subfornitore PIAGGIOKIT. Delle 5 sockets:
Con riferimento allo schema di figura, le sockets sono utilizzate come segue:
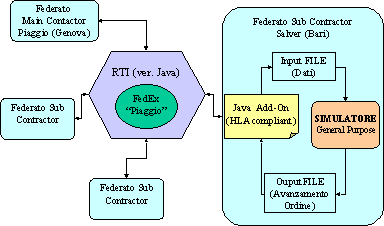
Schema generale di integrazione del modello di federato SALVER con simulatore General Purpouse.
DIG, Milano
Come definito nel documento programmatico di presentazione al MURST, "obiettivo primario della ricerca è la creazione di uno strumento innovativo per la gestione integrata on line/real time della produzione di unità operative distribuite, nellimprescindibile ottica della quick response".
Obiettivo etico della ricerca è quindi permettere un "miglioramento delle relazioni tra i fornitori "forti" e i sottofornitori "deboli" (PMI), essendo ancora oggi troppo spesso questi ultimi costretti a dover fare le spese della inefficienze che i prime-contractors generano nei sistemi integrati di produzione, ma anche, per contro, quello di garantire ai main-contractors, il rispetto degli impegni assunti, molte volte con leggerezza, dai sub-contractors (con conseguente messa a repentaglio sia del risultato economico, sia della credibilità del prime-contractors stesso)".
Lobiettivo pratico, in termini metodologici, corrisponde alla "creazione di network di simulatori/schedulatori gerarchicamente interagenti e attivati on line/real time per la produzione". Si tratta pertanto di progettare ed implementare una simulazione distribuita che consenta la costituzione di un ambiente virtuale, nel quale ogni simulatore/schedulatore corrisponde ad un nodo indipendente di una catena logistica.
Ogni simulatore di livello gerarchicamente inferiore (es. un sotto fornitore) deve essere in grado di ricevere ed elaborare le informazioni di sua competenza, relative a variazioni nella programmazione della produzione al livello superiore. In conformità a queste, lo strumento locale di simulazione/schedulazione deve provvedere alla riprogrammazione della produzione dellunità interessata. Riprogrammazione che, successivamente, deve essere inviata, assieme a quella di altri eventuali sottofornitori di medesimo livello gerarchico, al simulatore posto al livello immediatamente superiore. Questultimo, sulla base dei risultati ottenuti a seguito del loop di schedulazione/simulazione, deve essere in grado a sua volta di vagliare laccettabilità delle soluzioni proposte, rinviando al livello inferiore eventuali richieste di una nuova riprogrammazione.
In questo Progetto si è provveduto alla stesura della struttura di simulazione distribuita, attraverso la creazione di più simulatori di singoli nodi aziendali. In tali simulatori, la pianificazione della produzione locale è effettuata in maniera indipendente, secondo le logiche realmente implementate in ogni azienda.
Si è così creato uno strumento che risulta essere di non poca utilità per lattività di scheduling intesa a livello distribuito: infatti, eseguendo più run di simulazione su più alternative implementative, differenti, ad esempio, per diverse leve operative realizzabili in ogni singolo nodo, si possono ricavare utili considerazioni circa la creazione di un vero e proprio piano di sequenziamento della produzione, condiviso fra i diversi simulatori, tendente verso lottimizzazione dellintera supply chain.
Su questa struttura base si possono ipotizzare differenti scenari da implementare per lo sviluppo di uno scheduling approfondito; questo è, per lappunto, il compito di futuri sviluppi (i.e. WILD).